Съдържание
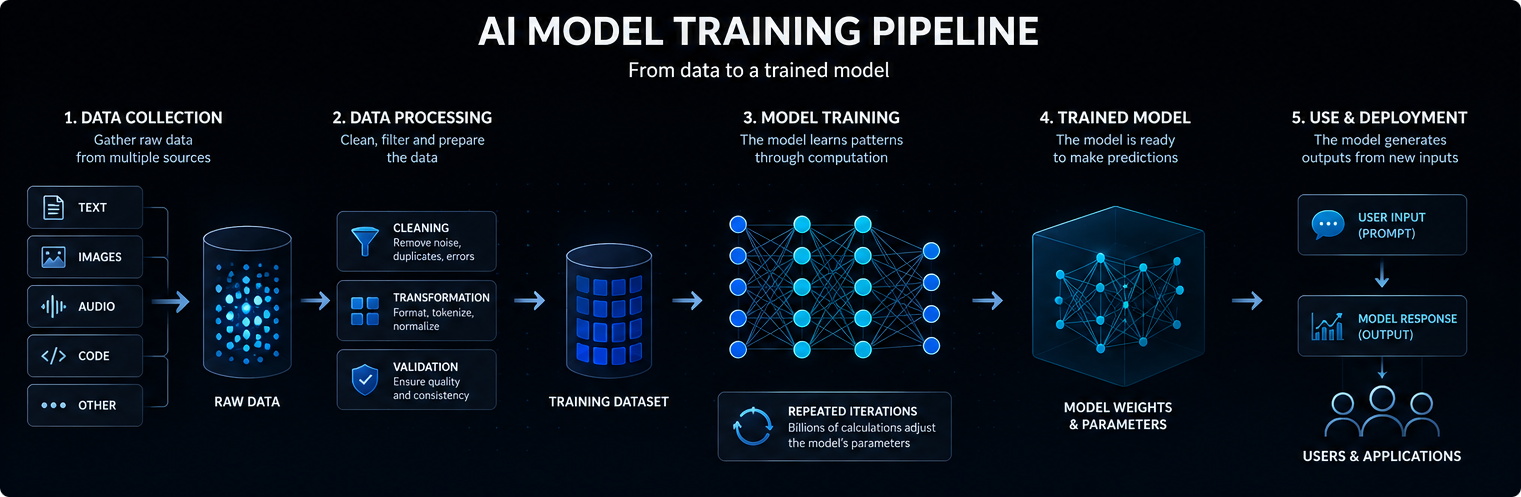
Обучението започва с данни
Обучението на модел на ИИ започва с данни. В зависимост от модела тези данни могат да включват текст, изображения, аудио, код, видео, научни измервания или структурирани записи.
Големите езикови модели се обучават върху огромни колекции от текстове и кодове, за да могат да научат статистически връзки между думи, понятия, инструкции и резултати.
Качеството, разнообразието и структурата на данните за обучение оказват силно влияние върху това какво може да научи моделът, колко добре обобщава и къде се появяват неговите ограничения.
Невронни мрежи и параметри
Съвременните модели на изкуствен интелект обикновено се основават на невронни мрежи. Тези мрежи се състоят от много слоеве с математически операции, които преобразуват входните данни в прогнози, класификации или генерирани резултати.
Вътрешните стойности, коригирани по време на обучението, се наричат параметри. Големите модели на изкуствен интелект могат да съдържат милиарди или дори трилиони параметри.
Обучението е процесът на настройване на тези параметри, така че моделът да се справи по-добре с прогнозирането, класифицирането, генерирането или извеждането на заключения въз основа на нови входни данни. С прости думи, моделът за изкуствен интелект работи, като преобразува входните данни във вътрешни сигнали, прекарва тези сигнали през научените параметри и генерира най-вероятния полезен резултат.
Как всъщност се случва ученето
По време на обучението моделът обработва примери и изготвя прогнози. Тези прогнози се сравняват с очакваните резултати или с целите на обучението.
Когато моделът допусне грешки, алгоритмите за оптимизация коригират леко параметрите му. Този процес се повтаря многократно в огромни набори от данни.
С течение на времето моделът усвоява статистически модели, които му позволяват да произвежда по-полезни резултати, когато по-късно получи нови промптове или входни данни.
Защо обучението изисква толкова много изчисления
Обучението на големи модели с изкуствен интелект изисква огромни изчисления, тъй като милиарди параметри трябва да се актуализират многократно в огромни обеми от данни.
Този процес обикновено се разпределя в големи клъстери от графични процесори в специализирани центрове за данни. Графичните процесори изпълняват паралелни математически операции много по-бързо от конвенционалните процесори.
Колкото по-голям е моделът и наборът от данни, толкова повече изчисления, електроенергия, охлаждане и инфраструктура са необходими.
Колко време отнема обучението на ИИ?
Продължителността на обучението варира в широки граници. Малките модели могат да бъдат обучени за минути или часове, докато граничните модели могат да изискват седмици или месеци координирани изчисления.
Времето за обучение зависи от размера на модела, размера на набора от данни, наличността на хардуера, техниките за оптимизация и броя на паралелно използваните графични процесори.
Големите лаборатории за изкуствен интелект инвестират много в инфраструктура, защото по-бързите цикли на обучение им позволяват да тестват повече идеи, да подобряват моделите по-бързо и да внедряват нови системи по-бързо.
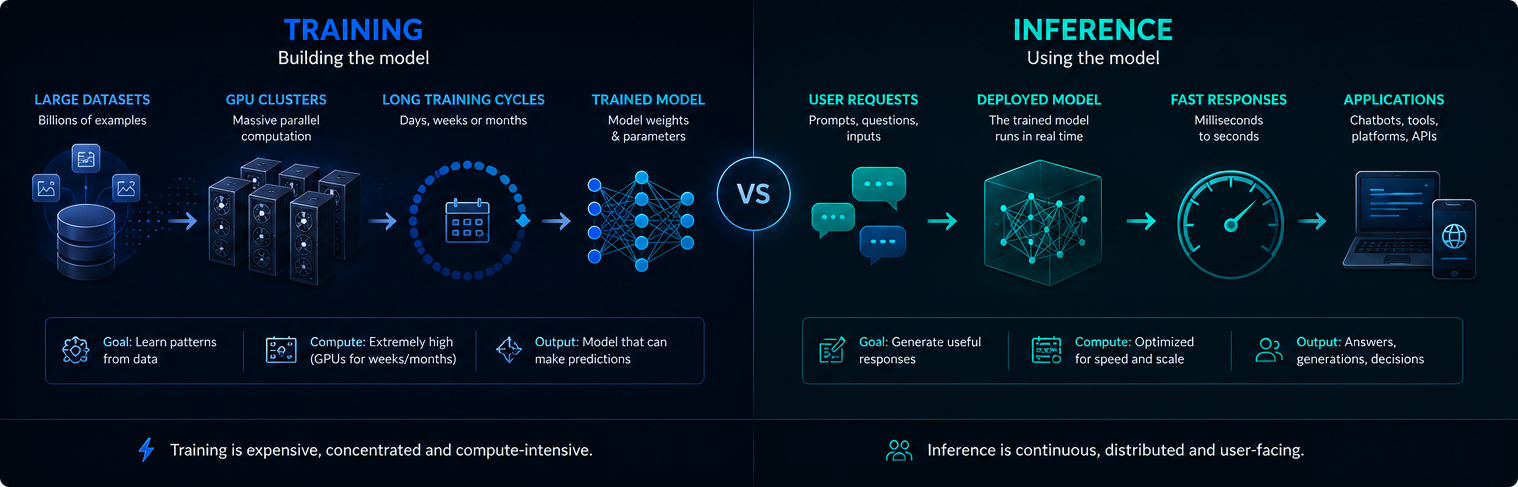
Обучение срещу извод
Обучението и изводът са различни етапи от инфраструктурата на ИИ. Обучението създава или актуализира модела, а изводът използва обучения модел, за да отговори на потребителските заявки.
Обикновено обучението е концентрирано и изисква изключително много компютри. Изводът е непрекъснат, тъй като внедрените системи за изкуствен интелект могат да обслужват милиони промптове всеки ден.
И двете фази са от значение за търсенето на електроенергия, използването на графични процесори и въздействието на съвременния изкуствен интелект върху околната среда.
Бъдещето на обучението по изкуствен интелект
Обучението на ИИ вероятно ще стане по-ефективно чрез по-добър хардуер, подобрени алгоритми, по-малки специализирани модели и по-оптимизирани потоци от данни.
В същото време търсенето на по-мощни модели продължава да расте. Подобренията в ефективността могат да намалят разходите за отделните работни натоварвания, докато общото търсене на изчислителни технологии продължава да нараства.
Разбирането на начина, по който се обучават моделите на изкуствения интелект, е от съществено значение за оценката на бъдещето на инфраструктурата на изкуствения интелект, използването на енергия и технологичния напредък.