Inhalt
Das Training beginnt mit Daten
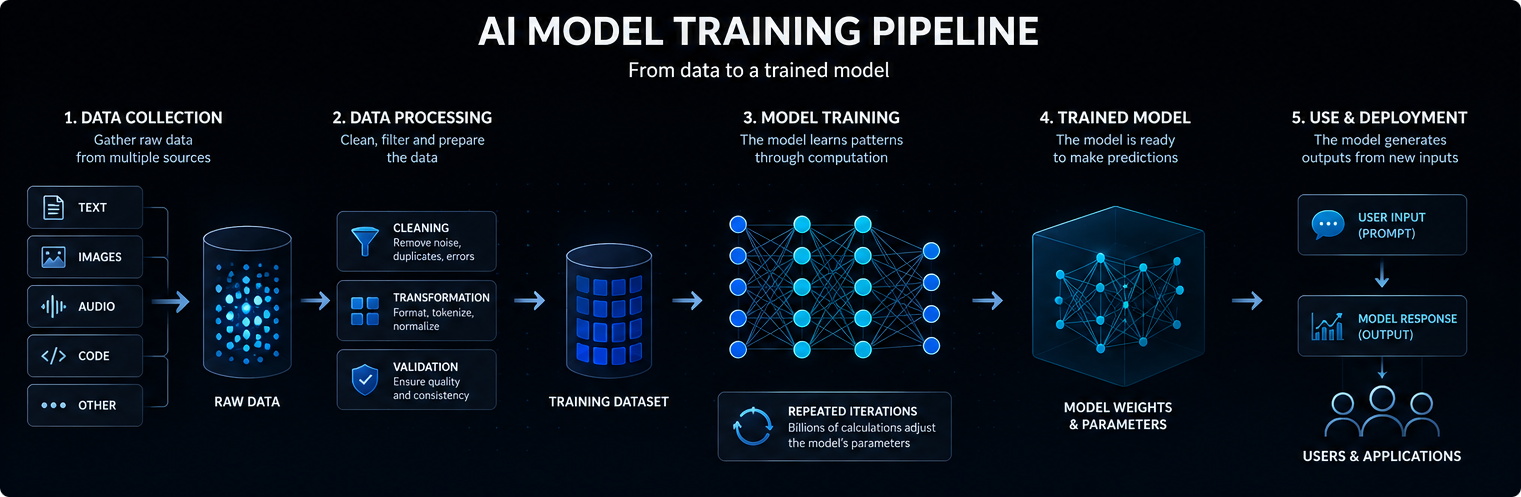
Das Training eines KI-Modells beginnt mit Daten. Je nach Modell können diese Daten Text, Bilder, Audio, Code, Video, wissenschaftliche Messungen oder strukturierte Datensätze umfassen.
Große Sprachmodelle werden anhand umfangreicher Text- und Codesammlungen trainiert, damit sie statistische Beziehungen zwischen Wörtern, Konzepten, Anweisungen und Ausgaben lernen können.
Die Qualität, Vielfalt und Struktur der Trainingsdaten haben einen großen Einfluss darauf, was das Modell lernen kann, wie gut es verallgemeinert und wo seine Grenzen liegen.
Neuronale Netze und Parameter
Moderne KI-Modelle basieren in der Regel auf neuronalen Netzen. Diese Netze bestehen aus vielen Schichten mathematischer Operationen, die Eingabedaten in Vorhersagen, Klassifizierungen oder generierte Ergebnisse umwandeln.
Die beim Training angepassten internen Werte werden als Parameter bezeichnet. Große KI-Modelle können Milliarden oder sogar Billionen von Parametern enthalten.
Beim Training werden diese Parameter so angepasst, dass das Modell neue Eingaben besser vorhersagen, klassifizieren, generieren oder auswerten kann. Vereinfacht ausgedrückt funktioniert ein KI-Modell so, dass es eine Eingabe in interne Signale umwandelt, diese Signale durch die erlernten Parameter leitet und die wahrscheinlich nützlichste Ausgabe erzeugt.
Wie Lernen tatsächlich geschieht
Während des Trainings verarbeitet das Modell Beispiele und erstellt Vorhersagen. Diese Vorhersagen werden mit den erwarteten Ergebnissen oder Trainingszielen verglichen.
Wenn das Modell Fehler macht, passen die Optimierungsalgorithmen seine Parameter leicht an. Dieser Prozess wird bei riesigen Datensätzen viele Male wiederholt.
Mit der Zeit lernt das Modell statistische Muster, die es ihm ermöglichen, nützlichere Ergebnisse zu produzieren, wenn es später neue Prompts oder Eingaben erhält.
Warum das Training so viel Rechenleistung erfordert
Das Training großer KI-Modelle erfordert enorme Rechenleistungen, da Milliarden von Parametern in riesigen Datenmengen wiederholt aktualisiert werden müssen.
Dieser Prozess wird in der Regel auf große GPU-Cluster in speziellen Rechenzentren verteilt. Die GPUs führen parallele mathematische Operationen viel schneller durch als herkömmliche Prozessoren.
Je größer das Modell und der Datensatz, desto mehr Rechenleistung, Strom, Kühlung und Infrastruktur werden benötigt.
Wie lange dauert das KI-Training?
Die Trainingsdauer ist sehr unterschiedlich. Kleine Modelle können in Minuten oder Stunden trainiert werden, während Grenzmodelle Wochen oder Monate koordinierter Berechnungen erfordern können.
Die Trainingszeit hängt von der Modellgröße, der Größe des Datensatzes, der Hardwareverfügbarkeit, den Optimierungstechniken und der Anzahl der parallel verwendeten GPUs ab.
Große KI-Labors investieren viel in ihre Infrastruktur, weil sie dank schnellerer Trainingszyklen mehr Ideen testen, Modelle schneller verbessern und neue Systeme schneller einsetzen können.
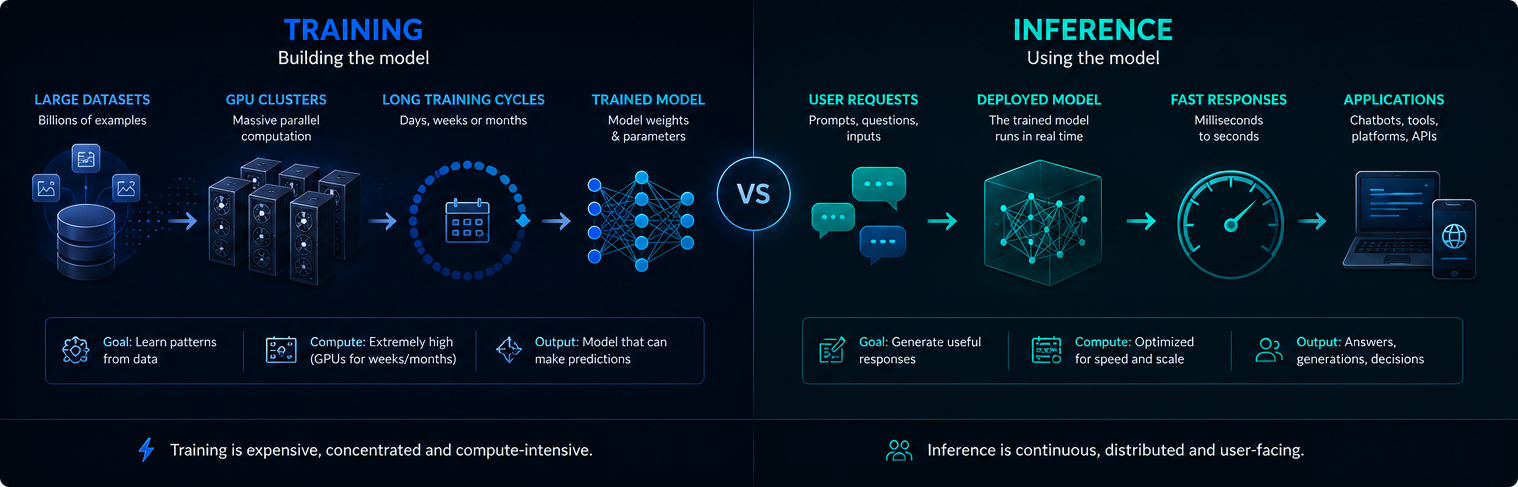
Training vs. Inferenz
Training und Inferenz sind unterschiedliche Phasen der KI-Infrastruktur. Beim Training wird das Modell erstellt oder aktualisiert, während bei der Inferenz das trainierte Modell verwendet wird, um Benutzeranfragen zu beantworten.
Das Training ist in der Regel konzentriert und extrem rechenintensiv. Die Schlussfolgerungen sind kontinuierlich, da die eingesetzten KI-Systeme jeden Tag Millionen von Prompts ausführen können.
Beide Phasen sind für den Strombedarf, die GPU-Nutzung und die Umweltauswirkungen der modernen KI von Bedeutung.
Die Zukunft des KI-Trainings
Das KI-Training wird wahrscheinlich durch bessere Hardware, verbesserte Algorithmen, kleinere spezialisierte Modelle und optimierte Datenpipelines effizienter werden.
Gleichzeitig steigt die Nachfrage nach leistungsfähigeren Modellen weiter an. Effizienzverbesserungen können die Kosten für einzelne Arbeitslasten senken, während der Gesamtbedarf an Rechenleistung weiter steigt.
Um die Zukunft der KI-Infrastruktur, des Energieverbrauchs und des technologischen Fortschritts beurteilen zu können, muss man verstehen, wie KI-Modelle trainiert werden.