Содержание
Обучение начинается с данных
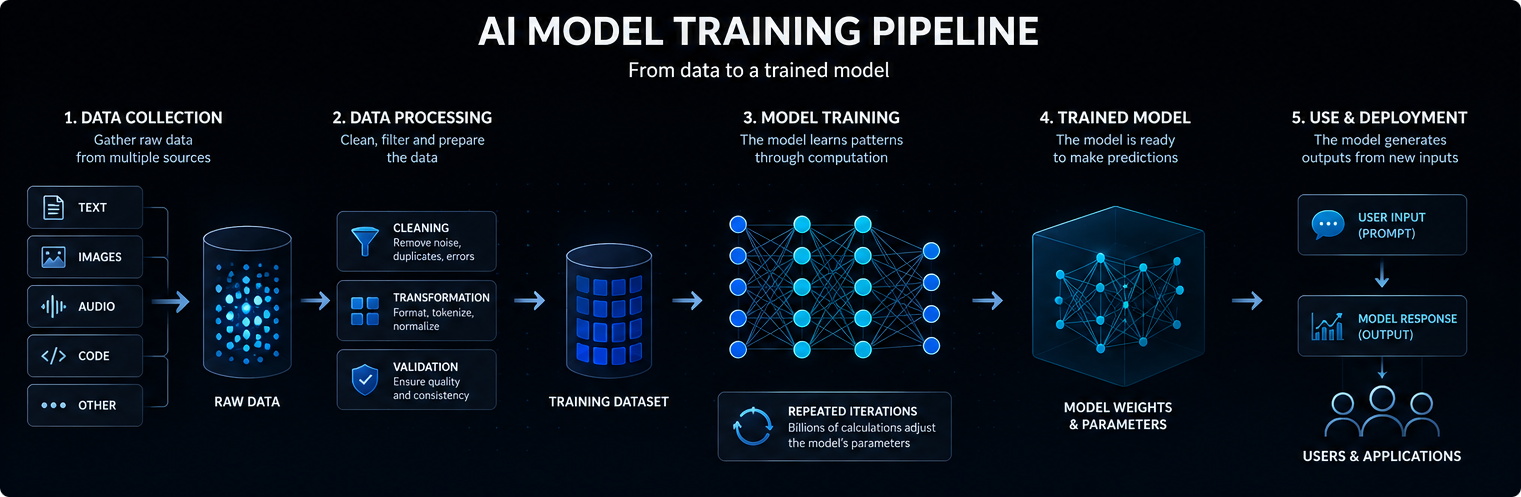
Обучение модели искусственного интеллекта начинается с данных. В зависимости от модели эти данные могут включать текст, изображения, аудио, код, видео, научные измерения или структурированные записи.
Большие языковые модели обучаются на огромных коллекциях текстов и кода, чтобы они могли изучать статистические связи между словами, понятиями, инструкциями и результатами.
Качество, разнообразие и структура обучающих данных сильно влияют на то, чему может научиться модель, насколько хорошо она обобщает и в чем проявляются ее недостатки.
Нейронные сети и параметры
Современные модели искусственного интеллекта, как правило, основаны на нейронных сетях. Эти сети состоят из множества слоёв математических операций, которые преобразуют входные данные в прогнозы, классификации или сгенерированные результаты.
Внутренние значения, настраиваемые в процессе обучения, называются параметрами. Большие модели ИИ могут содержать миллиарды или даже триллионы параметров.
Обучение — это процесс настройки этих параметров, благодаря которому модель начинает более точно прогнозировать, классифицировать, генерировать данные или выводить заключения на основе новых входных данных. Проще говоря, модель искусственного интеллекта преобразует входные данные во внутренние сигналы, пропускает эти сигналы через обученные параметры и генерирует наиболее вероятный полезный результат.
Как происходит обучение на самом деле
В процессе обучения модель обрабатывает примеры и выдает прогнозы. Эти прогнозы сравниваются с ожидаемыми результатами или целями обучения.
Когда модель допускает ошибки, алгоритмы оптимизации слегка корректируют ее параметры. Этот процесс повторяется много раз на огромных массивах данных.
Со временем модель изучает статистические закономерности, которые позволяют ей выдавать более полезные результаты, когда она получает новые подсказки или вводные данные.
Почему обучение требует так много вычислений
Обучение больших моделей искусственного интеллекта требует огромных вычислений, поскольку необходимо многократно обновлять миллиарды параметров в огромных объемах данных.
Этот процесс обычно распределяется по большим кластерам GPU в специализированных центрах обработки данных. GPU выполняют параллельные математические операции гораздо быстрее, чем обычные процессоры.
Чем больше модель и набор данных, тем больше требуется вычислений, электроэнергии, охлаждения и инфраструктуры.
Сколько времени занимает обучение ИИ?
Продолжительность обучения варьируется в широких пределах. Небольшие модели можно обучить за несколько минут или часов, в то время как для передовых моделей могут потребоваться недели или месяцы согласованных вычислений.
Время обучения зависит от размера модели, объема набора данных, доступности оборудования, методов оптимизации и количества параллельно используемых графических процессоров.
Крупные лаборатории ИИ вкладывают значительные средства в инфраструктуру, поскольку ускоренные циклы обучения позволяют им тестировать больше идей, быстрее совершенствовать модели и быстрее внедрять новые системы.
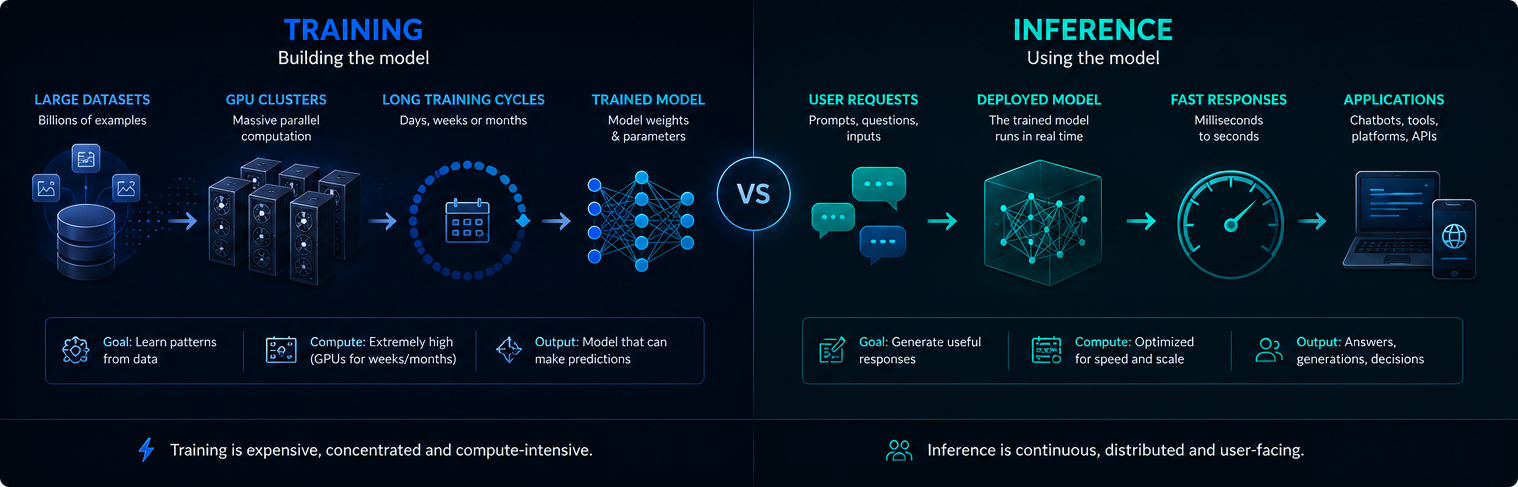
Обучение и вывод
Обучение и вывод - это разные этапы работы инфраструктуры ИИ. Обучение создает или обновляет модель, а вывод использует обученную модель для ответа на запросы пользователей.
Обучение обычно носит концентрированный характер и требует больших вычислительных затрат. Выводы делаются непрерывно, поскольку развернутые системы ИИ могут обслуживать миллионы запросов каждый день.
Обе фазы имеют значение для спроса на электроэнергию, использования графических процессоров и воздействия современного ИИ на окружающую среду.
Будущее обучения с помощью искусственного интеллекта
Обучение ИИ, вероятно, станет более эффективным благодаря более совершенному оборудованию, улучшенным алгоритмам, более компактным специализированным моделям и более оптимизированным конвейерам данных.
В то же время спрос на более производительные модели продолжает расти. Повышение эффективности может снизить стоимость отдельных рабочих нагрузок, в то время как общий спрос на вычисления продолжает расти.
Понимание того, как происходит обучение моделей ИИ, необходимо для оценки будущего инфраструктуры ИИ, использования энергии и технологического прогресса.