Obsah
Školenie začína údajmi
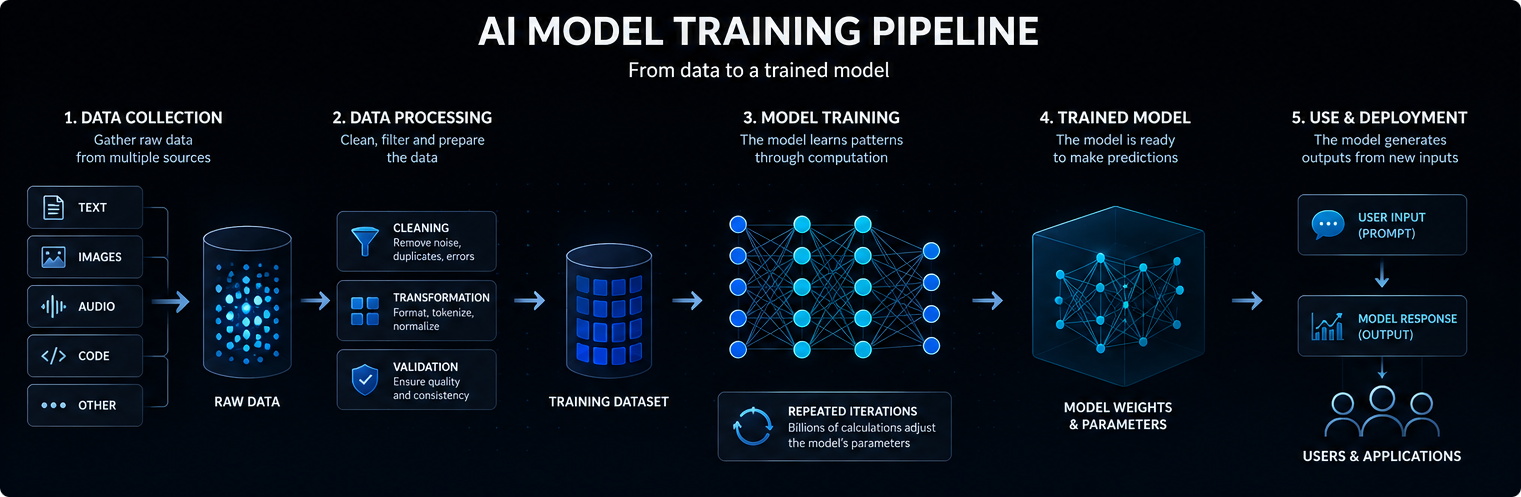
Trénovanie modelu umelej inteligencie sa začína údajmi. V závislosti od modelu môžu tieto údaje obsahovať text, obrázky, zvuk, kód, video, vedecké merania alebo štruktúrované záznamy.
Veľké jazykové modely sa trénujú na rozsiahlych zbierkach textov a kódov, aby sa mohli naučiť štatistické vzťahy medzi slovami, pojmami, inštrukciami a výstupmi.
Kvalita, rozmanitosť a štruktúra trénovaných údajov výrazne ovplyvňujú to, čo sa model dokáže naučiť, ako dobre zovšeobecňuje a kde sa prejavujú jeho obmedzenia.
Neurónové siete a parametre
Moderné modely umelej inteligencie sú zvyčajne založené na neurónových sieťach. Tieto siete obsahujú mnoho vrstiev matematických operácií, ktoré transformujú vstupné údaje na predpovede, klasifikácie alebo generované výstupy.
Vnútorné hodnoty upravené počas trénovania sa nazývajú parametre. Veľké modely umelej inteligencie môžu obsahovať miliardy alebo dokonca bilióny parametrov.
Trénovanie je proces úpravy týchto parametrov tak, aby sa model stal lepším v predpovedaní, klasifikácii, generovaní alebo usudzovaní na základe nových vstupných údajov. Zjednodušene povedané, model umelej inteligencie funguje tak, že prevádza vstupné údaje na vnútorné signály, prechádza tieto signály cez naučené parametre a generuje výstup, ktorý je s najväčšou pravdepodobnosťou užitočný.
Ako prebieha učenie
Počas trénovania model spracováva príklady a vytvára predpovede. Tieto predpovede sa porovnávajú s očakávanými výstupmi alebo cieľmi tréningu.
Keď sa model pomýli, optimalizačné algoritmy mierne upravia jeho parametre. Tento proces sa opakuje mnohokrát v obrovských súboroch údajov.
Postupom času sa model naučí štatistické vzory, ktoré mu umožnia vytvárať užitočnejšie výstupy, keď neskôr dostane nové prompty alebo vstupy.
Prečo si školenie vyžaduje toľko výpočtovej techniky
Trénovanie veľkých modelov umelej inteligencie si vyžaduje masívne výpočty, pretože miliardy parametrov sa musia opakovane aktualizovať v obrovských objemoch údajov.
Tento proces sa zvyčajne distribuuje do veľkých klastrov GPU v špecializovaných dátových centrách. GPU vykonávajú paralelné matematické operácie oveľa rýchlejšie ako bežné procesory.
Čím väčší je model a súbor údajov, tým viac výpočtovej techniky, elektrickej energie, chladenia a infraštruktúry je potrebných.
Ako dlho trvá tréning umelej inteligencie?
Trvanie odbornej prípravy sa značne líši. Malé modely sa dajú natrénovať za niekoľko minút alebo hodín, zatiaľ čo hraničné modely si môžu vyžadovať týždne alebo mesiace koordinovaných výpočtov.
Čas trénovania závisí od veľkosti modelu, veľkosti súboru údajov, dostupnosti hardvéru, optimalizačných techník a počtu paralelne používaných GPU.
Veľké laboratóriá umelej inteligencie investujú veľké prostriedky do infraštruktúry, pretože rýchlejšie tréningové cykly im umožňujú testovať viac nápadov, rýchlejšie zlepšovať modely a skôr nasadzovať nové systémy.
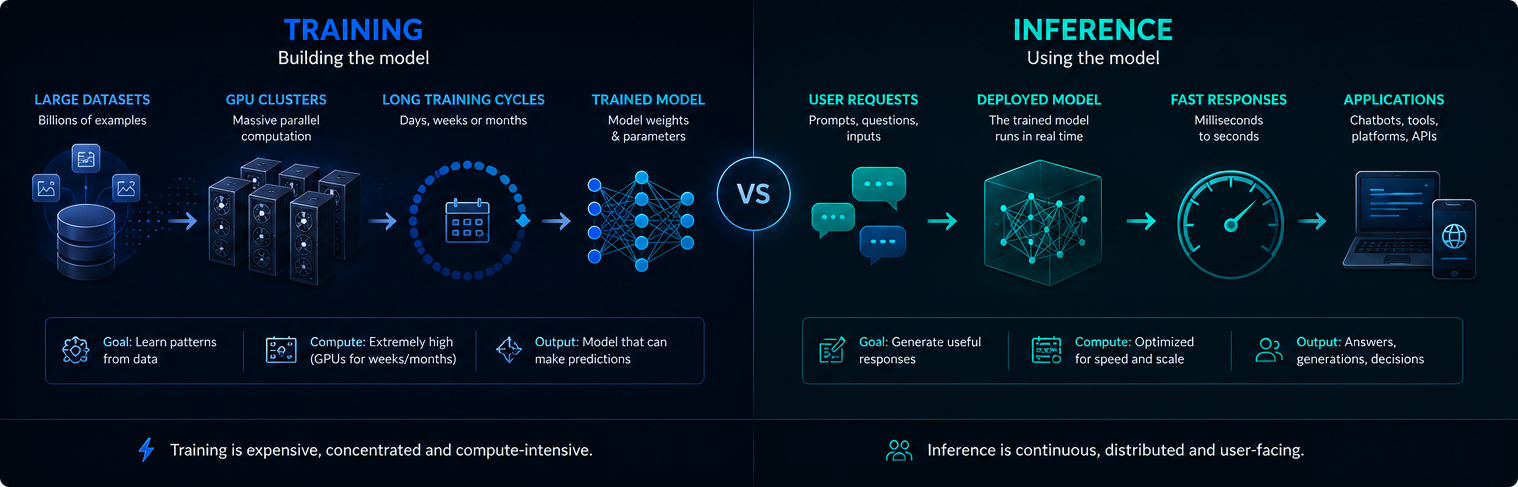
Školenie vs. odvodzovanie
Trénovanie a odvodzovanie sú rôzne fázy infraštruktúry umelej inteligencie. Tréning vytvára alebo aktualizuje model, zatiaľ čo inferencia využíva natrénovaný model na odpovedanie na požiadavky používateľov.
Školenie je zvyčajne koncentrované a veľmi náročné na výpočty. Odvodzovanie je nepretržité, pretože nasadené systémy umelej inteligencie môžu každý deň doručiť milióny promptov.
Obe fázy majú význam pre dopyt po elektrickej energii, využívanie GPU a vplyv modernej umelej inteligencie na životné prostredie.
Budúcnosť školenia umelej inteligencie
Tréning umelej inteligencie sa pravdepodobne stane efektívnejším vďaka lepšiemu hardvéru, lepším algoritmom, menším špecializovaným modelom a optimalizovanejším dátovým potrubiam.
Zároveň stále rastie dopyt po výkonnejších modeloch. Zlepšenia efektívnosti môžu znížiť náklady na jednotlivé pracovné zaťaženia, zatiaľ čo celkový dopyt po výpočtoch stále rastie.
Pochopenie toho, ako sa modely umelej inteligencie trénujú, je nevyhnutné na posúdenie budúcnosti infraštruktúry umelej inteligencie, využívania energie a technologického pokroku.