Obsah
Čo sa stane, keď odošlete dotaz na umelú inteligenciu?
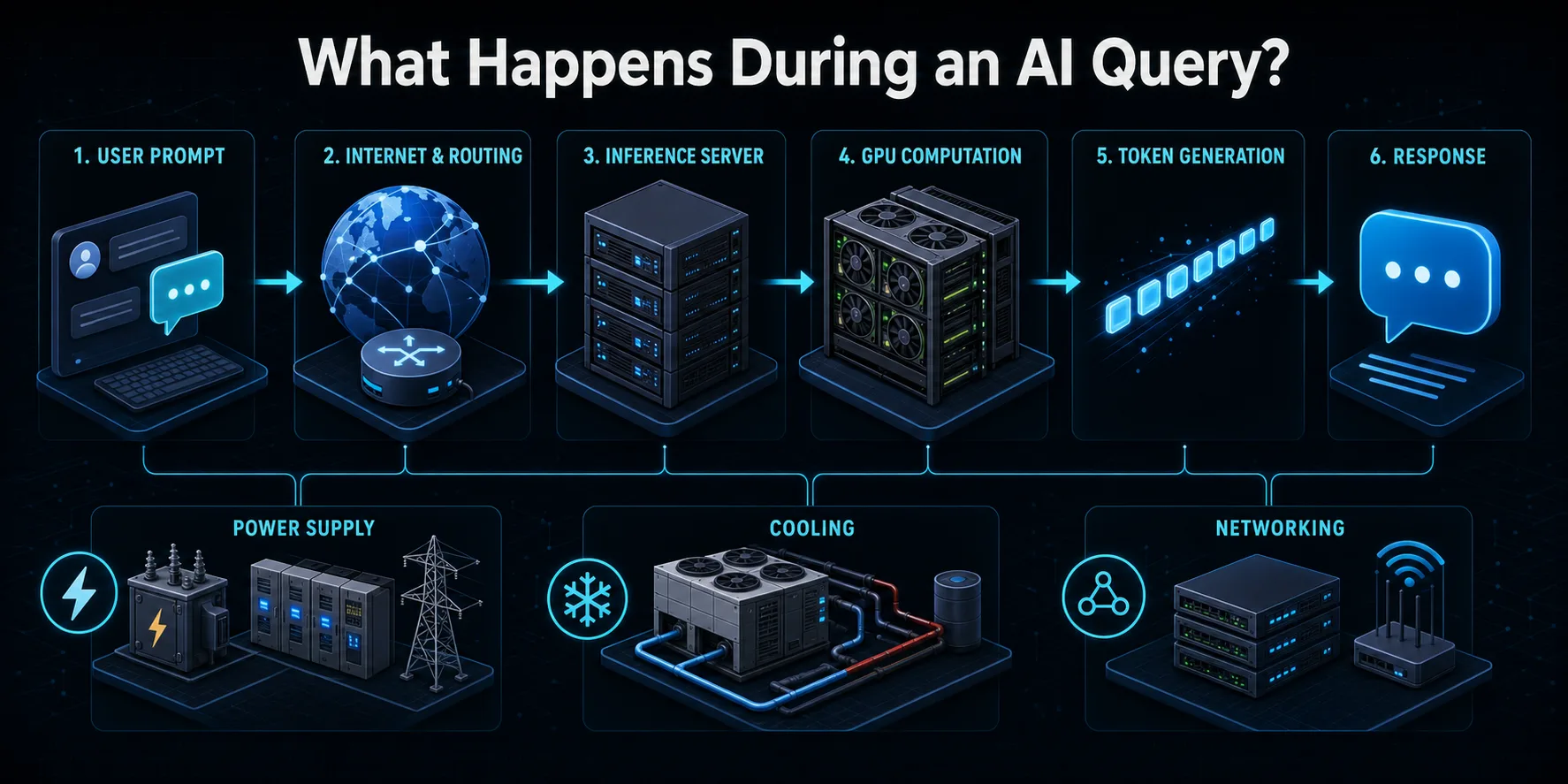
Keď odošlete prompt službe umelej inteligencie, požiadavka sa najprv prenesie cez internet do infraštruktúry poskytovateľa. Smerovacie systémy overia autentickosť požiadavky, použijú bezpečnostné kontroly a kontroly používania a nasmerujú ju na dostupný inferenčný server. Vyvažovač záťaže môže vyberať medzi mnohými strojmi tak, aby sa prevádzka používateľov rozdelila bez preťaženia jednej časti systému.
Server konvertuje prompt na tokeny, číselné jednotky spracované jazykovým modelom. Tieto tokeny a akýkoľvek predchádzajúci kontext konverzácie sa načítajú do pamäte akcelerátora. Grafické procesory alebo iné čipy umelej inteligencie potom vykonávajú vrstvy maticových výpočtov naprieč parametrami modelu s cieľom predpovedať ďalší token. Tento proces sa opakuje mnohokrát, kým nie je odpoveď úplná alebo kým sa nedosiahne nakonfigurovaný limit.
Vygenerovaný výstup sa dekóduje do textu a posiela sa späť používateľovi, často ešte počas výpočtu neskorších tokenov. Okolo tejto viditeľnej interakcie zostávajú aktívne úložné, sieťové, monitorovacie, konverzné a chladiace zariadenia. Dotaz preto spotrebuje viac elektrickej energie, ako sa nameralo len na GPU, hoci akcelerátor zvyčajne vykonáva väčšinu intenzívnych výpočtov.
Prečo dotazy AI spotrebúvajú elektrickú energiu
Odvodzovanie umelej inteligencie je skôr aktívnym výpočtom ako jednoduchým vyhľadávaním z databázy. Veľký model musí pre každý vygenerovaný token vyhodnotiť mnoho numerických operácií, pričom sa používajú parametre, ktoré môžu zaberať desiatky alebo stovky gigabajtov pamäte. Presúvanie týchto parametrov a medziľahlých hodnôt medzi pamäťou s veľkou šírkou pásma a jadrami procesora spotrebúva elektrickú energiu spolu so samotnými výpočtami.
Množstvo práce rastie s modelom, promptom a požadovaným výstupom. Dlhé histórie konverzácií si vyžadujú viac kontextu na spracovanie, zatiaľ čo dlhé odpovede udržiavajú akcelerátory v chode viac krokov generovania. Obrázkové, zvukové a video systémy môžu vyžadovať rôzne spracovateľské pipeline alebo opakované spresňovacie operácie, takže dopyt AI nepredstavuje jednu štandardizovanú jednotku práce.
Záleží aj na réžii dátového centra. Servery potrebujú napájacie zdroje, siete, úložiská a chladenie a časť elektrickej energie sa stráca pri konverzii a distribúcii energie. Prevádzkovatelia často vyjadrujú túto réžiu prostredníctvom efektívnosti využitia energie alebo PUE. Efektívne zariadenie približuje celkovú energiu k energii spotrebovanej výpočtovým zariadením, zatiaľ čo menej efektívne zariadenie vyžaduje viac podpornej elektrickej energie na rovnakú inferenčnú záťaž.
Koľko elektrickej energie spotrebuje dotaz na umelú inteligenciu?
Pre dotaz na umelú inteligenciu neexistuje univerzálna hodnota elektrickej energie. Verejné odhady pre textové interakcie sa bežne pohybujú od zlomkov watt-hodiny po niekoľko watt-hodín, ale rozsah by sa mal považovať skôr za rádovú hodnotu než za pevný prepočet. Krátka požiadavka spracovaná optimalizovaným, dobre využitým modelom môže spotrebovať oveľa menej energie ako dlhá odpoveď väčšieho modelu bežiaceho na nedostatočne využívanom hardvéri.
Watthodina meria energiu, nie okamžitý výkon. Napríklad server, ktorý odoberá vysoký výkon počas zlomku sekundy, môže spotrebovať menej celkovej energie ako systém s nižším výkonom, ktorý beží oveľa dlhšie. Pre dôveryhodný odhad na požiadavku je preto potrebný odber energie zariadenia, ako aj trvanie a podiel tohto zariadenia pripadajúci na požiadavku.
Porovnania s vyhľadávaním na webe, žiarovkami alebo nabíjaním telefónu môžu uľahčiť vizualizáciu rozsahu, ale často skrývajú dôležité predpoklady. Podstatnou otázkou nie je, či každý prompt spotrebuje jedno konkrétne množstvo. Ide o to, ktorý model obsluhoval požiadavku, koľko tokenov a modalít bolo spracovaných, ako efektívne boli požiadavky zoskupené a koľko energie infraštruktúry bolo zahrnuté do výpočtu.
Prečo sa odhady líšia
Poskytovatelia umelej inteligencie len zriedka zverejňujú úplné merania, ktoré spájajú jednotlivé požiadavky s veľkosťou modelu, využitím hardvéru, počtom tokenov a réžiou zariadenia. Výskumníci preto musia kombinovať zverejnené hardvérové špecifikácie, výsledky benchmarkov, odhadované časy obsluhy a predpoklady efektívnosti dátového centra. Rôzne voľby v ktoromkoľvek kroku môžu priniesť podstatne odlišné odpovede.
Dávkovanie je jedným z hlavných zdrojov odchýlok. Inferenčný server môže spracúvať niekoľko používateľov spoločne, pričom načítanie modelu a výpočty sa zdieľajú v rámci dávky. Vysoké využitie môže znížiť priemernú energiu priradenú každej požiadavke, zatiaľ čo nevyužitá kapacita, požiadavky na latenciu alebo prudké nárasty prevádzky môžu spôsobiť, že drahý hardvér zostane čiastočne využitý. Novšie akcelerátory môžu tiež dokončiť rovnakú záťaž rýchlejšie alebo s menším počtom joulov.
Hranica odhadu mení aj výsledok. Niektoré výpočty počítajú len s energiou akcelerátora, iné zahŕňajú aj straty energie procesorov, pamäte, siete, chladenia a napájania. Väčšina údajov na jeden dotaz nezahŕňa skoršiu energiu použitú na výrobu hardvéru a trénovanie modelu. Odhady sú najužitočnejšie vtedy, keď sú ich systémové hranice a predpoklady explicitné, nie keď sa jedno číslo prezentuje ako univerzálne.
Dotazy na umelú inteligenciu v porovnaní s tréningom umelej inteligencie
Tréning vytvára alebo aktualizuje model opakovaným spracovaním veľkých súborov údajov a úpravou jeho parametrov. Veľký tréningový beh môže zabrať tisíce akcelerátorov na niekoľko dní alebo týždňov, čo z neho robí koncentrovanú a veľmi viditeľnú výpočtovú udalosť. Po dokončení školenia sa výsledný model môže nasadiť na mnohých inferenčných serveroch, aby odpovedal na požiadavky používateľov.
Inferencia je zvyčajne oveľa menšia pre jednu interakciu, ale je spojitá. Produkčné systémy musia reagovať v ktorúkoľvek hodinu, udržiavať dostatočnú kapacitu pre špičky a obsluhovať používateľov vo viacerých regiónoch. Energetický profil sa preto rozdeľuje do mnohých dátových centier a opakuje sa pri každom generovaní textu, obrázkov, zvuku alebo iných výstupov.
Nemalo by sa automaticky predpokladať, že ani jedno z týchto zaťažení bude dominovať v spotrebe elektrickej energie modelu počas jeho životnosti. Tréning môže byť najväčšou jednorazovou udalosťou, najmä v prípade hraničných systémov, zatiaľ čo inferencia ju môže nakoniec prekročiť, keď služba spracováva obrovskú prevádzku počas mesiacov alebo rokov. Rovnováha závisí od toho, ako často sa modely preškoľujú, ako široko sú nasadené a ako intenzívne ich ľudia používajú.
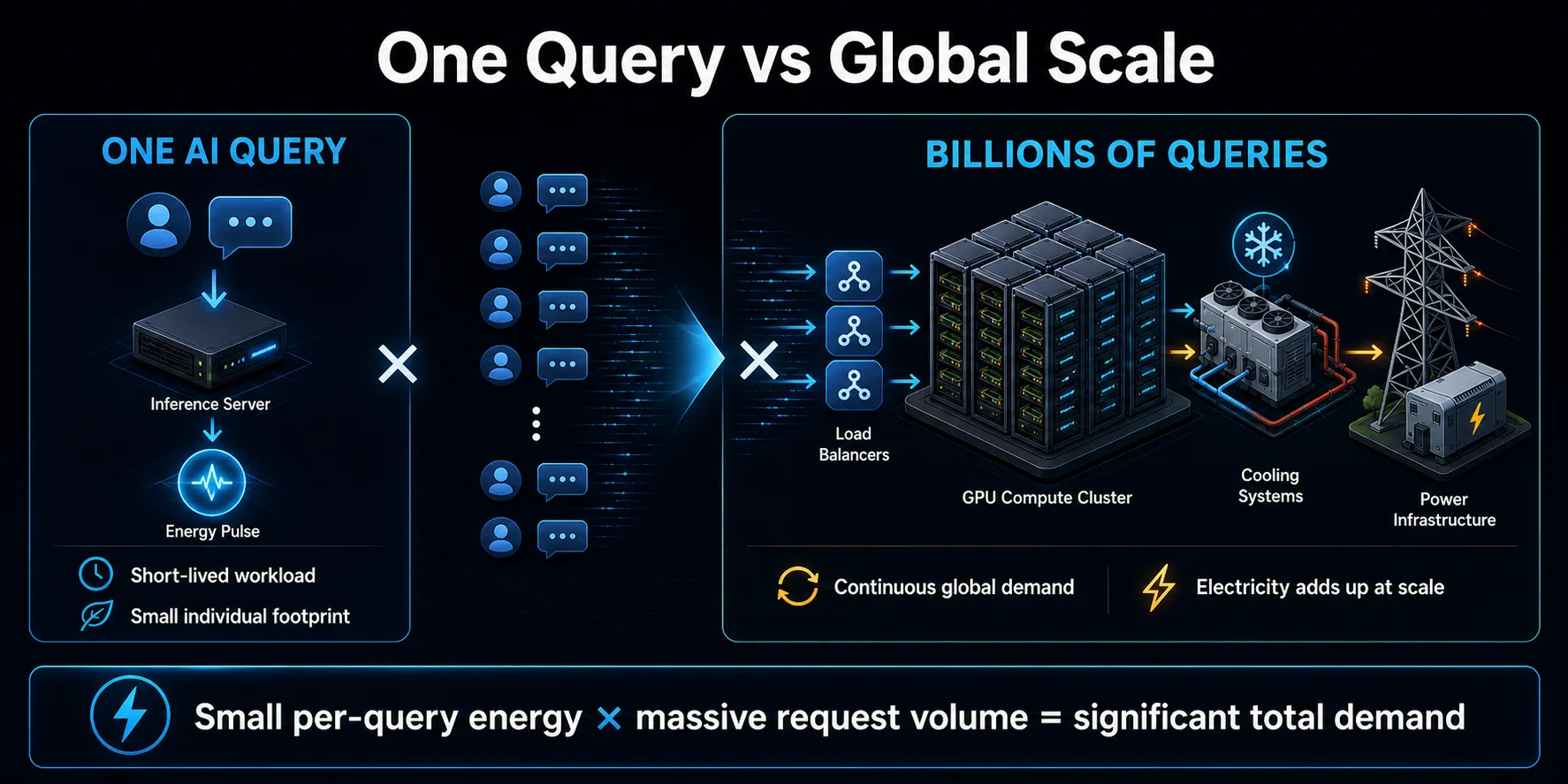
Miliardy dopytov sa sčítajú
Význam dotazov na umelú inteligenciu pre životné prostredie vyplýva predovšetkým z množenia. Jediný krátky dotaz môže predstavovať malé množstvo energie, ale asistenti pre spotrebiteľov, vyhľadávacie funkcie, kódovacie nástroje a obchodné aplikácie môžu generovať obrovské množstvo požiadaviek. Pri nepretržitom opakovaní sa skromná energia na jeden dopyt stáva značnou záťažou dátového centra.
Dopyt nie je obmedzený na viditeľné správy chatbota. Aplikácie môžu vykonať niekoľko modelových volaní, aby odpovedali na jednu používateľskú akciu, používať samostatné modely na moderovanie alebo vyhľadávanie, opakovať neúspešné požiadavky a generovať súhrny alebo odporúčania na pozadí. Agentové systémy môžu tento vzor rozšíriť opakovaným volaním modelov a softvérových nástrojov počas vykonávania jednej úlohy.
Plánovanie infraštruktúry ovplyvňuje aj rozsah. Poskytovatelia budujú kapacitu pre rast a špičkovú prevádzku, čo môže zvýšiť dopyt po elektrickej energii skôr, ako sa naplno využije každý server. Celkový vplyv závisí od účinnosti na jeden dotaz aj od rýchlosti, akou sa používanie rozširuje. Ak dopyt rastie rýchlejšie ako sa zlepšuje účinnosť, celková spotreba elektrickej energie môže naďalej rásť, aj keď každá jednotlivá interakcia bude menej energeticky náročná.
Budú dotazy na umelú inteligenciu efektívnejšie?
Odvodzovanie pomocou umelej inteligencie bude pravdepodobne energeticky efektívnejšie na úrovni porovnateľnej úlohy. Nové akcelerátory poskytujú viac výpočtov na jednotku elektrickej energie, zatiaľ čo kvantizácia, pruning, špekulatívne dekódovanie a vylepšené architektúry modelov môžu znížiť operácie potrebné na užitočný výstup. Lepšie plánovanie a dávkovanie môže tiež zvýšiť využitie hardvéru bez toho, aby sa zmenil používateľský zážitok.
Inú cestu ponúkajú menšie špecializované modely. Služba nepotrebuje vždy svoj najväčší model na klasifikáciu, extrakciu alebo rutinné otázky. Smerovanie jednoduchej práce do kompaktných modelov, obmedzenie nepotrebného kontextu a ukladanie opakovane použiteľných výsledkov do vyrovnávacej pamäte môže znížiť latenciu aj spotrebu elektrickej energie. Dátové centrá môžu ďalej zlepšiť celkovú účinnosť prostredníctvom dodávky energie, chladenia a umiestnenia pracovného zaťaženia.
Účinnosť nezaručuje nižšiu celkovú spotrebu. Rýchlejšia a lacnejšia umelá inteligencia môže podporovať viac aplikácií, dlhšie interakcie a nové funkcie náročné na výpočty, čo sa niekedy označuje ako odrazový dopyt. Budúca elektrická stopa dopytov po UI bude preto závisieť od dvoch konkurenčných trendov: ako rýchlo sa každá jednotka užitočnej práce stane efektívnejšou a ako rýchlo porastie celkový objem a zložitosť používania UI.