Obsah
Školení začíná daty
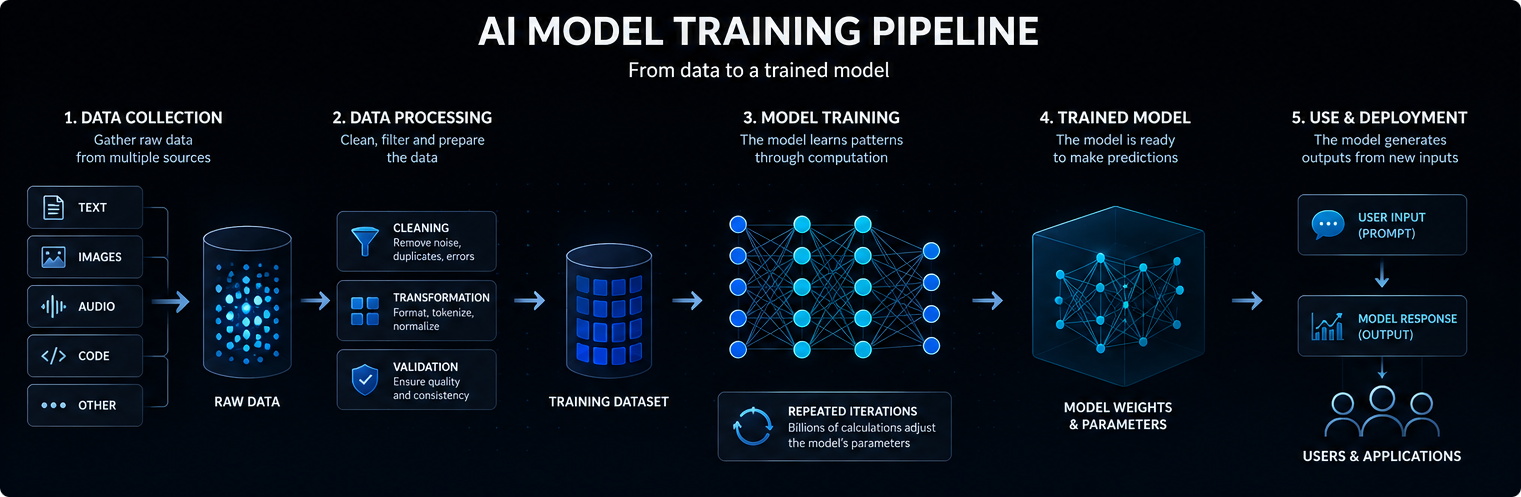
Trénování modelu umělé inteligence začíná daty. V závislosti na modelu mohou tato data zahrnovat text, obrázky, zvuk, kód, video, vědecká měření nebo strukturované záznamy.
Velké jazykové modely se trénují na rozsáhlých sbírkách textů a kódů, aby se mohly naučit statistické vztahy mezi slovy, pojmy, instrukcemi a výstupy.
Kvalita, rozmanitost a struktura trénovacích dat výrazně ovlivňují to, co se model může naučit, jak dobře zobecňuje a kde se projevují jeho omezení.
Neuronové sítě a parametry
Moderní modely umělé inteligence jsou obvykle založeny na neuronových sítích. Tyto sítě obsahují mnoho vrstev matematických operací, které převádějí vstupní data na předpovědi, klasifikace nebo generované výstupy.
Vnitřní hodnoty upravené během tréninku se nazývají parametry. Velké modely umělé inteligence mohou obsahovat miliardy nebo dokonce biliony parametrů.
Trénování je proces, při kterém se tyto parametry upravují tak, aby model lépe předpovídal, klasifikoval, generoval nebo uvažoval o nových vstupech. Zjednodušeně řečeno, model umělé inteligence funguje tak, že převádí vstup na interní signály, tyto signály procházejí naučenými parametry a výsledkem je nejpravděpodobnější užitečný výstup.
Jak vlastně probíhá učení
Během trénování model zpracovává příklady a vytváří předpovědi. Tyto předpovědi se porovnávají s očekávanými výstupy nebo cíli tréninku.
Pokud se model dopustí chyby, optimalizační algoritmy mírně upraví jeho parametry. Tento proces se opakuje mnohokrát v obrovských souborech dat.
Postupem času se model naučí statistické vzorce, které mu umožní vytvářet užitečnější výstupy, když později obdrží nové podněty nebo vstupy.
Proč školení vyžaduje tolik výpočetní techniky
Trénování rozsáhlých modelů umělé inteligence vyžaduje masivní výpočet, protože je třeba opakovaně aktualizovat miliardy parametrů na obrovských objemech dat.
Tento proces je obvykle distribuován do velkých clusterů GPU ve specializovaných datových centrech. GPU provádějí paralelní matematické operace mnohem rychleji než běžné procesory.
Čím větší je model a soubor dat, tím více výpočetní techniky, elektřiny, chlazení a infrastruktury je potřeba.
Jak dlouho trvá trénink umělé inteligence?
Délka školení se značně liší. Malé modely lze natrénovat během několika minut nebo hodin, zatímco hraniční modely mohou vyžadovat týdny nebo měsíce koordinovaných výpočtů.
Doba trénování závisí na velikosti modelu, velikosti datové sady, dostupnosti hardwaru, optimalizačních technikách a počtu paralelně používaných GPU.
Velké laboratoře AI investují velké prostředky do infrastruktury, protože rychlejší tréninkové cykly jim umožňují testovat více nápadů, rychleji zlepšovat modely a dříve nasazovat nové systémy.
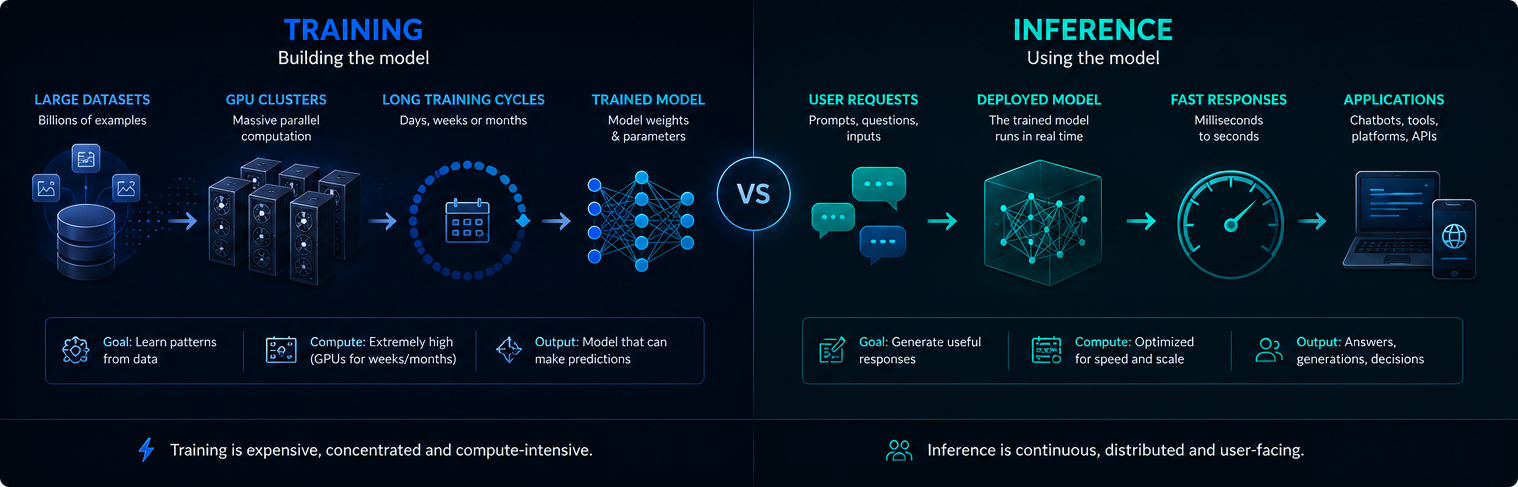
Školení vs. odvozování
Trénování a odvozování jsou různé fáze infrastruktury umělé inteligence. Tréninkem se vytváří nebo aktualizuje model, zatímco inference používá natrénovaný model k zodpovídání požadavků uživatelů.
Školení je obvykle koncentrované a velmi náročné na výpočetní techniku. Odvozování je nepřetržité, protože nasazené systémy umělé inteligence mohou denně obsluhovat miliony promptů.
Obě fáze mají význam pro poptávku po elektřině, využití GPU a dopad moderní umělé inteligence na životní prostředí.
Budoucnost výcviku umělé inteligence
Trénink umělé inteligence bude pravděpodobně efektivnější díky lepšímu hardwaru, vylepšeným algoritmům, menším specializovaným modelům a optimalizovanějším datovým pipeline.
Zároveň stále roste poptávka po výkonnějších modelech. Zlepšení efektivity může snížit náklady na jednotlivé pracovní zátěže, zatímco celková poptávka po výpočetní technice stále roste.
Pochopení způsobu, jakým jsou modely umělé inteligence trénovány, je zásadní pro hodnocení budoucnosti infrastruktury umělé inteligence, využívání energie a technologického pokroku.