Indhold
Træning starter med data
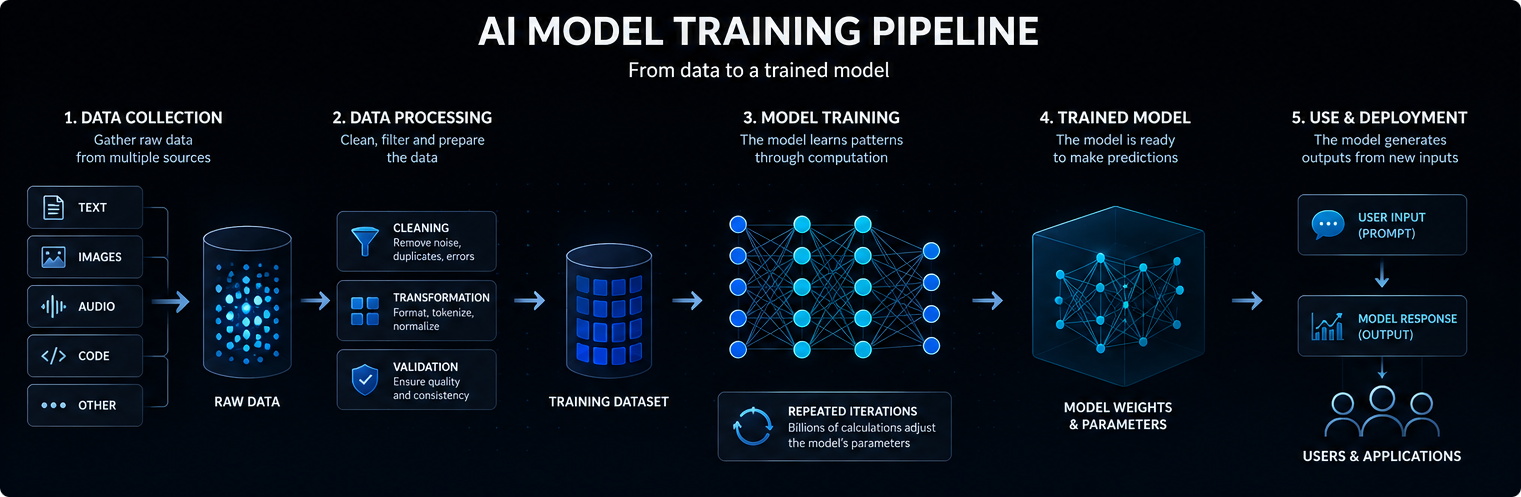
Træning af en AI-model begynder med data. Afhængigt af modellen kan disse data omfatte tekst, billeder, lyd, kode, video, videnskabelige målinger eller strukturerede optegnelser.
Store sprogmodeller trænes på store samlinger af tekst og kode, så de kan lære statistiske relationer mellem ord, begreber, instruktioner og output.
Kvaliteten, mangfoldigheden og strukturen af træningsdataene har stor indflydelse på, hvad modellen kan lære, hvor godt den generaliserer, og hvor dens begrænsninger viser sig.
Neurale netværk og parametre
Moderne AI-modeller er som regel baseret på neurale netværk. Disse netværk består af mange lag med matematiske operationer, der omdanner inddata til forudsigelser, klassificeringer eller genererede resultater.
De interne værdier, der justeres under træningen, kaldes parametre. Store AI-modeller kan indeholde milliarder eller endda billioner af parametre.
Træning er den proces, hvor disse parametre justeres, så modellen bliver bedre til at forudsige, klassificere, generere eller drage konklusioner ud fra nye inddata. Enkelt sagt fungerer en AI-model ved at omdanne inddata til interne signaler, sende disse signaler gennem de indlærte parametre og generere det mest sandsynlige og nyttige uddata.
Hvordan læring faktisk sker
Under træningen behandler modellen eksempler og producerer forudsigelser. Disse forudsigelser sammenlignes med forventede resultater eller træningsmål.
Når modellen begår fejl, justerer optimeringsalgoritmerne dens parametre en smule. Denne proces gentages mange gange på tværs af enorme datasæt.
Med tiden lærer modellen statistiske mønstre, som gør den i stand til at producere mere brugbare output, når den senere modtager nye instruktioner eller input.
Hvorfor træning kræver så meget computerarbejde
Træning af store AI-modeller kræver massiv beregning, fordi milliarder af parametre skal opdateres gentagne gange på tværs af enorme datamængder.
Denne proces er typisk fordelt på store GPU-klynger i specialiserede datacentre. GPU'erne udfører parallelle matematiske operationer langt hurtigere end konventionelle processorer.
Jo større modellen og datasættet er, jo mere computer, elektricitet, køling og infrastruktur kræves der.
Hvor lang tid tager AI-træning?
Varigheden af træningen varierer meget. Små modeller kan trænes på få minutter eller timer, mens grænsemodeller kan kræve uger eller måneder med koordinerede beregninger.
Træningstiden afhænger af modelstørrelse, datasætstørrelse, hardwaretilgængelighed, optimeringsteknikker og antallet af GPU'er, der bruges parallelt.
Store AI-laboratorier investerer massivt i infrastruktur, fordi hurtigere træningscyklusser giver dem mulighed for at teste flere ideer, forbedre modeller hurtigere og implementere nye systemer hurtigere.
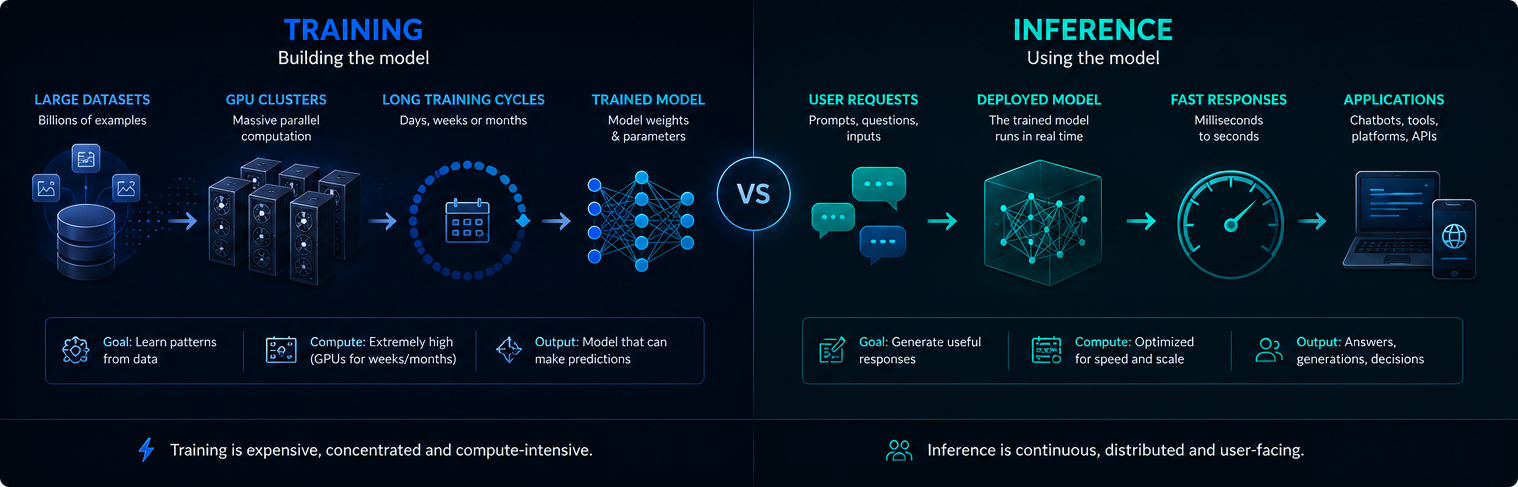
Træning vs. udledning
Træning og inferens er forskellige faser i AI-infrastrukturen. Træning skaber eller opdaterer modellen, mens inferens bruger den trænede model til at besvare brugeranmodninger.
Træning er normalt koncentreret og ekstremt computerintensiv. Inferens er kontinuerlig, fordi implementerede AI-systemer kan betjene millioner af forespørgsler hver dag.
Begge faser har betydning for elforbrug, GPU-forbrug og den moderne AI's miljøpåvirkning.
Fremtiden for AI-træning
AI-træning vil sandsynligvis blive mere effektiv gennem bedre hardware, forbedrede algoritmer, mindre specialiserede modeller og mere optimerede datapipelines.
Samtidig fortsætter efterspørgslen efter mere effektive modeller med at vokse. Effektivitetsforbedringer kan reducere omkostningerne ved individuelle arbejdsopgaver, mens den samlede efterspørgsel efter computere stadig stiger.
At forstå, hvordan AI-modeller trænes, er afgørende for at kunne vurdere fremtiden for AI-infrastruktur, energiforbrug og teknologiske fremskridt.