Indholdsfortegnelse
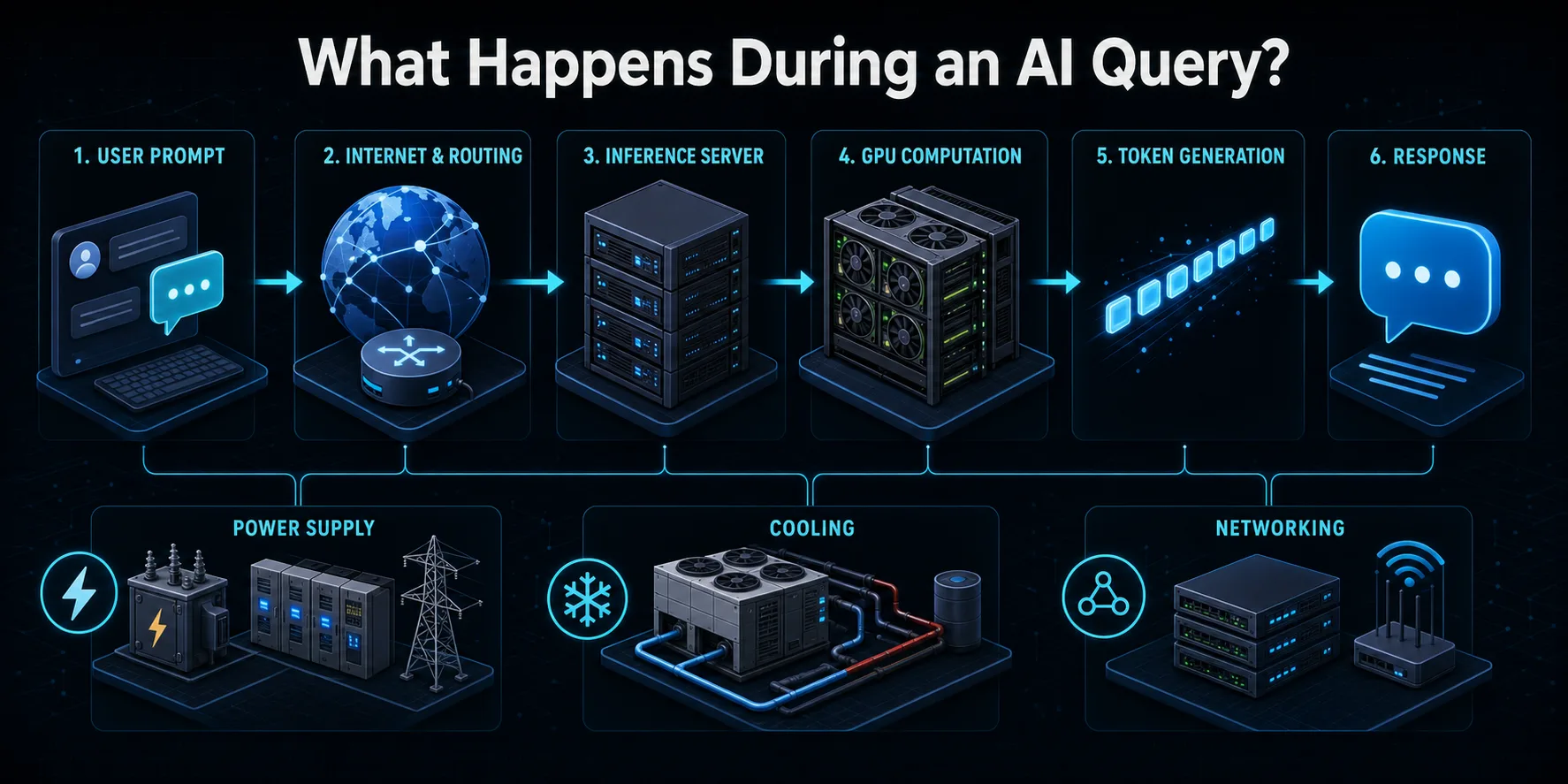
Hvad sker der, når du sender en AI-forespørgsel?
Når du sender en forespørgsel til en AI-tjeneste, rejser forespørgslen først over internettet til udbyderens infrastruktur. Routing-systemer autentificerer forespørgslen, anvender sikkerheds- og brugskontrol og leder den hen til en tilgængelig inferensserver. En load balancer kan vælge mellem mange maskiner, så brugertrafikken fordeles uden at overbelaste en del af systemet.
Serveren konverterer prompten til tokens, de numeriske enheder, der behandles af en sprogmodel. Disse tokens og enhver tidligere samtalekontekst indlæses i acceleratorens hukommelse. GPU'er eller andre AI-chips udfører derefter lag af matrixberegninger på tværs af modellens parametre for at forudsige det næste token. Processen gentages mange gange, indtil svaret er komplet eller når en konfigureret grænse.
Det genererede output afkodes til tekst og streames tilbage til brugeren, ofte mens senere tokens stadig er ved at blive beregnet. Omkring denne synlige interaktion er lager-, netværks-, overvågnings-, strømkonverterings- og køleudstyr fortsat aktivt. En forespørgsel bruger derfor mere end den elektricitet, der måles på GPU'en alene, selv om acceleratoren normalt udfører det meste af den intensive beregning.
Hvorfor AI-forespørgsler bruger strøm
AI-inferens er en aktiv beregning snarere end en simpel hentning fra en database. En stor model skal evaluere mange numeriske operationer for hvert genereret token ved hjælp af parametre, der kan optage titusindvis eller hundredvis af gigabyte hukommelse. At flytte disse parametre og mellemliggende værdier mellem hukommelse med høj båndbredde og processorkerner bruger strøm sammen med selve beregningerne.
Mængden af arbejde vokser med modellen, prompten og det ønskede output. Lange samtalehistorier kræver mere kontekst, der skal behandles, mens lange svar holder acceleratorerne i gang i flere generationstrin. Billed-, lyd- og videosystemer kan kræve forskellige behandlingspipelines eller gentagne forfiningsoperationer, så en AI-forespørgsel er ikke en standardiseret arbejdsenhed.
Datacentrets overhead betyder også noget. Servere har brug for strømforsyninger, netværk, lagerplads og køling, og noget elektricitet går tabt under strømkonvertering og -distribution. Operatører udtrykker ofte dette overhead gennem strømforbrugseffektivitet eller PUE. En effektiv facilitet bringer den samlede energi tættere på den energi, der bruges af computerudstyr, mens en mindre effektiv facilitet kræver mere understøttende elektricitet til den samme slutningsarbejdsbyrde.
Hvor meget strøm bruger en AI-forespørgsel?
Der findes ikke noget universelt elforbrug for en AI-forespørgsel. Offentlige estimater for tekstinteraktioner spænder ofte fra brøkdele af en watt-time til flere watt-timer, men intervallet skal behandles som en størrelsesorden snarere end en fast konvertering. En kort forespørgsel, der håndteres af en optimeret, veludnyttet model, kan bruge meget mindre energi end et langt svar fra en større model, der kører på underudnyttet hardware.
En watt-time måler energi, ikke øjeblikkelig effekt. For eksempel kan en server, der trækker meget strøm i en brøkdel af et sekund, bruge mindre samlet energi end et system med lavere strømforbrug, der kører i meget længere tid. Et troværdigt estimat pr. forespørgsel har derfor brug for både udstyrets strømforbrug og varigheden og andelen af dette udstyr, der kan tilskrives forespørgslen.
Sammenligninger med websøgninger, elpærer eller telefonopladning kan gøre skalaen lettere at visualisere, men de skjuler ofte vigtige antagelser. Det relevante spørgsmål er ikke, om hver forespørgsel bruger en bestemt mængde. Det er, hvilken model der betjente anmodningen, hvor mange tokens og modaliteter der blev behandlet, hvor effektivt anmodninger blev grupperet, og hvor meget infrastrukturenergi der blev inkluderet i beregningen.
Hvorfor estimater varierer
AI-udbydere offentliggør sjældent komplette målinger, der forbinder individuelle anmodninger med modelstørrelse, hardwareudnyttelse, token-tællinger og anlægsoverhead. Forskere må derfor kombinere offentliggjorte hardwarespecifikationer, benchmarkresultater, anslåede serveringstider og antagelser om datacentrenes effektivitet. Forskellige valg på ethvert trin kan give væsentligt forskellige svar.
Batching er en vigtig kilde til variation. En inferensserver kan behandle flere brugere sammen og dele modelindlæsning og beregning på tværs af en batch. Høj udnyttelse kan reducere den gennemsnitlige energi, der tildeles hver anmodning, mens ledig kapacitet, latenstidskrav eller trafikspidser kan efterlade dyr hardware delvist brugt. Nyere acceleratorer kan også gennemføre den samme arbejdsbyrde hurtigere eller med færre joule.
Afgrænsningen af estimatet ændrer også resultatet. Nogle beregninger tæller kun acceleratorenergi; andre inkluderer CPU'er, hukommelse, netværk, køling og strømtab. De fleste tal pr. forespørgsel udelukker den tidligere energi, der blev brugt til at fremstille hardware og træne modellen. Estimater er mest nyttige, når deres systemgrænser og antagelser er eksplicitte, ikke når et enkelt tal præsenteres som universelt.
AI-forespørgsler versus AI-træning
Træning skaber eller opdaterer en model ved gentagne gange at behandle store datasæt og justere dens parametre. En stor træningskørsel kan optage tusindvis af acceleratorer i dage eller uger, hvilket gør det til en koncentreret og meget synlig computerbegivenhed. Når træningen er færdig, kan den resulterende model implementeres på tværs af mange inferensservere for at besvare brugeranmodninger.
Inferens er normalt meget mindre for en interaktion, men den er kontinuerlig. Produktionssystemer skal reagere når som helst, have nok kapacitet til rådighed til spidsbelastninger og betjene brugere i flere regioner. Energiprofilen er derfor fordelt på mange datacentre og gentages, hver gang der genereres tekst, billeder, lyd eller andre outputs.
Ingen af arbejdsbelastningerne bør automatisk antages at dominere en models strømforbrug i hele dens levetid. Træning kan være den største enkeltstående begivenhed, især for grænsesystemer, mens udledning i sidste ende kan overstige den, når en tjeneste håndterer enorm trafik over måneder eller år. Balancen afhænger af, hvor ofte modellerne bliver genoptrænet, hvor udbredt de er, og hvor intensivt folk bruger dem.
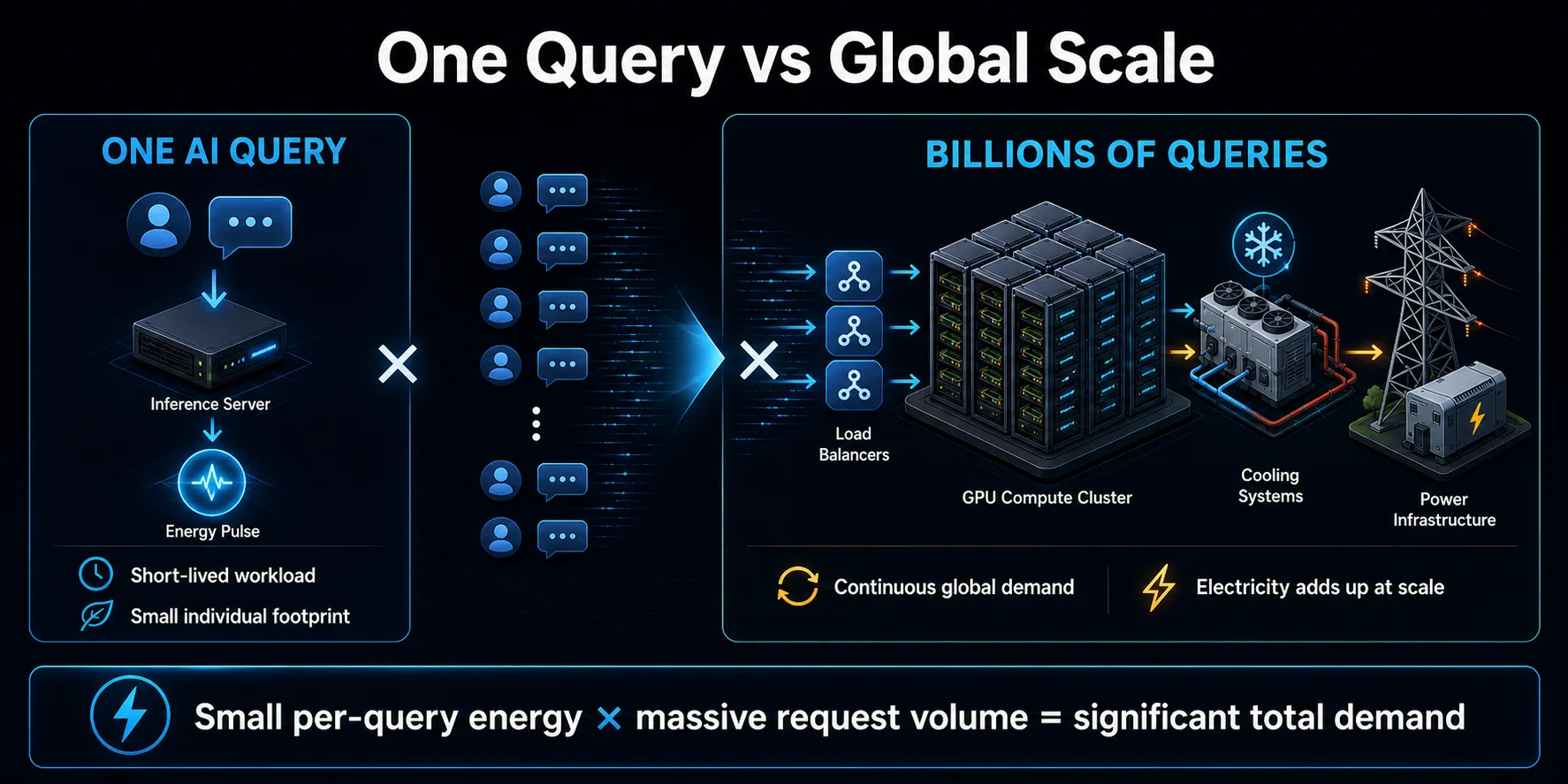
Milliarder af forespørgsler løber op
Den miljømæssige betydning af AI-forespørgsler kommer primært fra multiplikation. En enkelt kort forespørgsel kan repræsentere en lille mængde energi, men forbrugerassistenter, søgefunktioner, kodningsværktøjer og forretningsapplikationer kan generere et stort antal forespørgsler. Når det gentages kontinuerligt, bliver den beskedne energi pr. forespørgsel til en betydelig belastning af datacentret.
Efterspørgslen er ikke begrænset til synlige chatbot-beskeder. Programmer kan foretage flere modelkald for at besvare en brugerhandling, bruge separate modeller til moderering eller hentning, prøve mislykkede anmodninger igen og generere baggrundsresuméer eller anbefalinger. Agentiske systemer kan udvide dette mønster ved at kalde modeller og softwareværktøjer gentagne gange, mens de udfører en enkelt opgave.
Skala påvirker også infrastrukturplanlægningen. Udbydere opbygger kapacitet til vækst og spidsbelastning, hvilket kan øge efterspørgslen efter elektricitet, før hver server er fuldt udnyttet. Den samlede effekt afhænger af både effektiviteten pr. forespørgsel og den hastighed, hvormed brugen udvides. Hvis efterspørgslen vokser hurtigere, end effektiviteten forbedres, kan det samlede elforbrug fortsætte med at stige, selv om hver enkelt interaktion bliver mindre energikrævende.
Vil AI-forespørgsler blive mere effektive?
AI-inferens vil sandsynligvis blive mere energieffektiv på niveau med en sammenlignelig opgave. Nye acceleratorer leverer mere beregning pr. enhed elektricitet, mens kvantisering, beskæring, spekulativ afkodning og forbedrede modelarkitekturer kan reducere de operationer, der er nødvendige for et nyttigt output. Bedre planlægning og batching kan også øge hardwareudnyttelsen uden at ændre brugeroplevelsen.
Mindre specialiserede modeller tilbyder en anden vej. En tjeneste har ikke altid brug for sin største model til klassificering, udtræk eller rutinemæssige spørgsmål. Ved at dirigere simpelt arbejde til kompakte modeller, begrænse unødvendig kontekst og cachelagre genanvendelige resultater kan man reducere både latenstid og elforbrug. Datacentre kan yderligere forbedre den samlede effektivitet gennem strømforsyning, køling og placering af arbejdsbyrden.
Effektivitet garanterer ikke et lavere samlet forbrug. Hurtigere og billigere AI kan tilskynde til flere applikationer, længere interaktioner og nye beregningsintensive funktioner, en effekt, der undertiden beskrives som rebound-efterspørgsel. Det fremtidige elaftryk fra AI-forespørgsler vil derfor afhænge af to konkurrerende tendenser: hvor hurtigt hver enhed af nyttigt arbejde bliver mere effektiv, og hvor hurtigt den samlede mængde og kompleksitet af AI-brug vokser.