Saturs
Apmācība sākas ar datiem
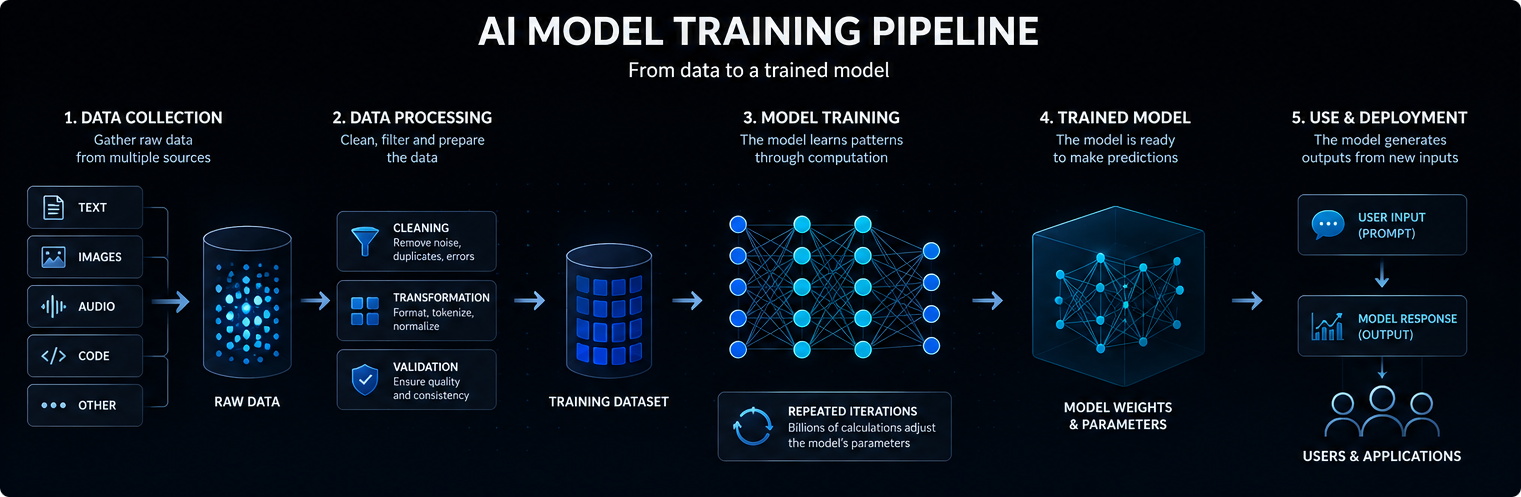
Mākslīgā intelekta modeļa apmācība sākas ar datiem. Atkarībā no modeļa šie dati var ietvert tekstu, attēlus, audio, kodu, video, zinātniskus mērījumus vai strukturētus ierakstus.
Lieli valodas modeļi tiek apmācīti, izmantojot plašas teksta un kodu kolekcijas, lai tie varētu apgūt statistiskās attiecības starp vārdiem, jēdzieniem, instrukcijām un rezultātiem.
Mācību datu kvalitāte, daudzveidība un struktūra būtiski ietekmē to, ko modelis var iemācīties, cik labi tas vispārina un kur parādās tā ierobežojumi.
Neironu tīkli un parametri
Mūsdienu mākslīgā intelekta modeļi parasti balstās uz neironu tīkliem. Šie tīkli sastāv no daudziem matemātisko operāciju slāņiem, kas ievades datus pārveido par prognozēm, klasifikācijām vai ģenerētiem rezultātiem.
Apmācības laikā pielāgotās iekšējās vērtības sauc par parametriem. Lielos mākslīgā intelekta modeļos var būt miljardiem vai pat triljoniem parametru.
Apmācība ir process, kurā šie parametri tiek pielāgoti tā, lai modelis spētu labāk prognozēt, klasificēt, ģenerēt vai izdarīt secinājumus par jauniem ieejas datiem. Vienkārši runājot, mākslīgā intelekta modelis darbojas tā, ka pārvērš ieejas datus iekšējos signālos, vadot šos signālus caur apgūtajiem parametriem un ģenerējot visdrīzāk noderīgu izejas rezultātu.
Kā patiesībā notiek mācīšanās
Apmācīšanas laikā modelis apstrādā piemērus un sagatavo prognozes. Šīs prognozes tiek salīdzinātas ar paredzamajiem rezultātiem vai apmācības mērķiem.
Ja modelis kļūdās, optimizācijas algoritmi nedaudz koriģē tā parametrus. Šis process tiek atkārtots daudzas reizes milzīgās datu kopās.
Laika gaitā modelis apgūst statistiskos modeļus, kas ļauj tam radīt noderīgākus rezultātus, kad tas vēlāk saņem jaunus norādījumus vai ievades datus.
Kāpēc apmācībai nepieciešams tik daudz skaitļošanas
Lielu mākslīgā intelekta modeļu apmācībai ir nepieciešami apjomīgi aprēķini, jo miljardiem parametru ir atkārtoti jāatjaunina milzīgi datu apjomi.
Šis process parasti tiek sadalīts pa lieliem GPU klasteriem specializētos datu centros. GPU veic paralēlas matemātiskas operācijas daudz ātrāk nekā parastie procesori.
Jo lielāks modelis un datu kopa, jo vairāk skaitļošanas iekārtu, elektroenerģijas, dzesēšanas un infrastruktūras ir nepieciešams.
Cik ilgs ir mākslīgā intelekta apmācības laiks?
Apmācību ilgums ir ļoti atšķirīgs. Nelielus modeļus var apmācīt dažu minūšu vai stundu laikā, bet robežmodeļiem var būt nepieciešamas nedēļas vai mēneši koordinētu aprēķinu.
Apmācības laiks ir atkarīgs no modeļa lieluma, datu kopas lieluma, aparatūras pieejamības, optimizācijas metodēm un paralēli izmantoto GPU skaita.
Lielās mākslīgā intelekta laboratorijas veic lielus ieguldījumus infrastruktūrā, jo ātrāki apmācības cikli ļauj tām pārbaudīt vairāk ideju, ātrāk uzlabot modeļus un ātrāk ieviest jaunas sistēmas.
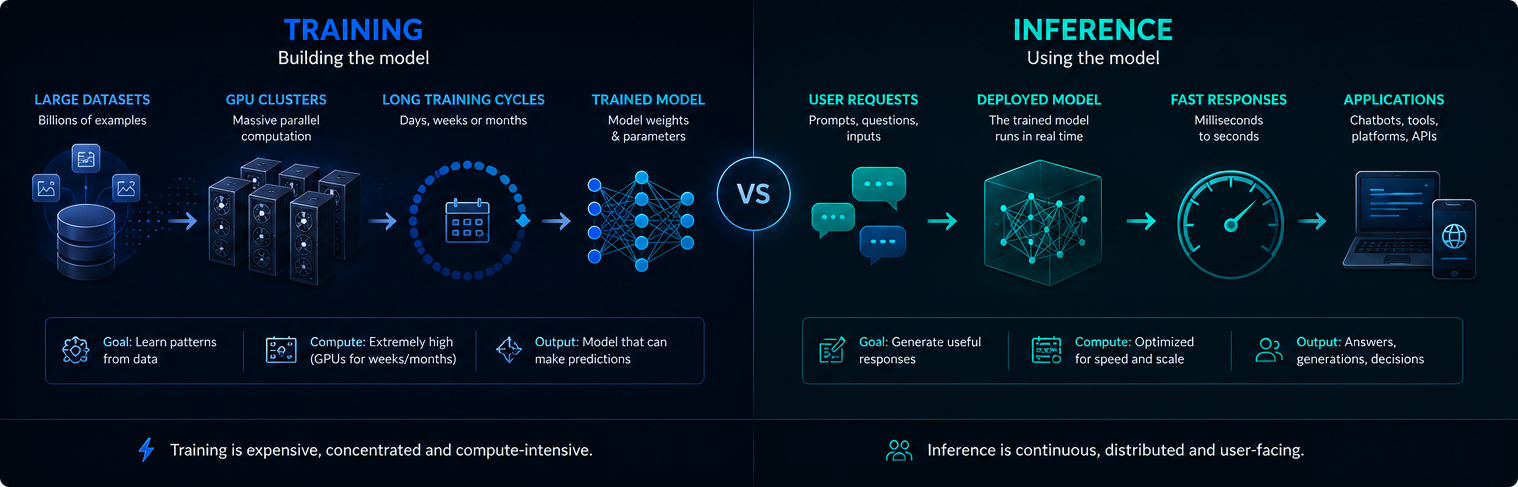
Apmācība pret secinājumu izdarīšanu
Apmācība un secinājumu izdarīšana ir dažādi mākslīgā intelekta infrastruktūras posmi. Apmācīšanas laikā tiek izveidots vai atjaunināts modelis, bet secinājumu izdarīšanas laikā apmācītais modelis tiek izmantots, lai atbildētu uz lietotāja pieprasījumiem.
Apmācība parasti ir koncentrēta un ļoti darbietilpīga. Secinājumi ir nepārtraukti, jo izvietotās mākslīgā intelekta sistēmas katru dienu var apstrādāt miljoniem ieteikumu.
Abi posmi ir svarīgi attiecībā uz elektroenerģijas pieprasījumu, GPU izmantošanu un modernā mākslīgā intelekta ietekmi uz vidi.
Mākslīgā intelekta apmācības nākotne
Mākslīgā intelekta apmācība, visticamāk, kļūs efektīvāka, pateicoties labākai aparatūrai, uzlabotiem algoritmiem, mazākiem specializētiem modeļiem un optimizētākiem datu cauruļvadiem.
Tajā pašā laikā pieprasījums pēc jaudīgākiem modeļiem turpina pieaugt. Efektivitātes uzlabojumi var samazināt atsevišķu darba slodžu izmaksas, bet kopējais skaitļošanas pieprasījums joprojām pieaug.
Izpratne par to, kā tiek apmācīti mākslīgā intelekta modeļi, ir būtiska, lai novērtētu mākslīgā intelekta infrastruktūras nākotni, enerģijas izmantošanu un tehnoloģiju attīstību.