Satura rādītājs
Kas notiek, kad nosūtāt AI pieprasījumu?
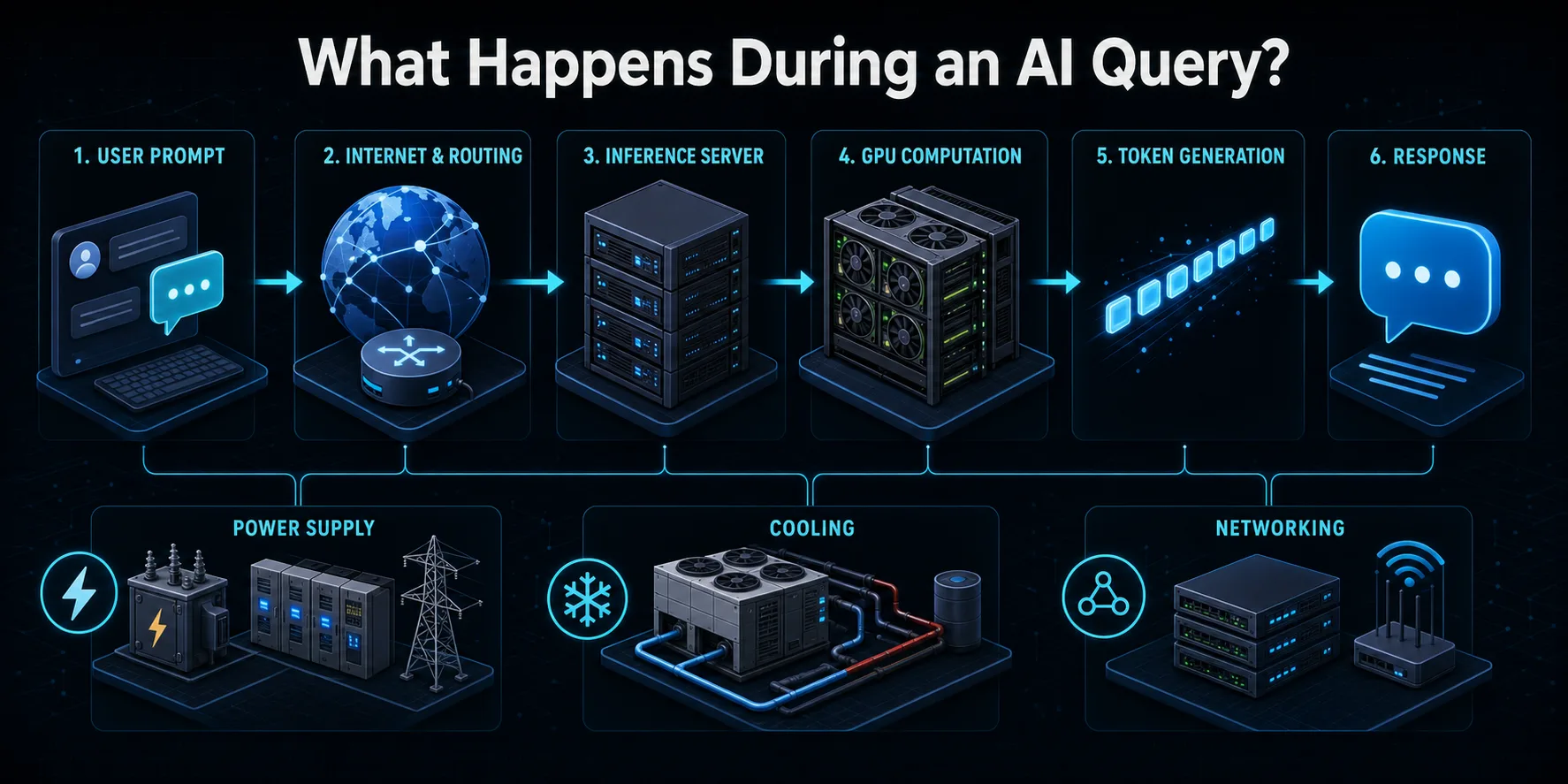
Kad AI pakalpojumam iesniedzat pieprasījumu, pieprasījums vispirms tiek nosūtīts caur internetu uz pakalpojumu sniedzēja infrastruktūru. Maršrutēšanas sistēmas autentificē pieprasījumu, piemēro drošības un lietošanas kontroli un novirza to uz pieejamo secinājumu serveri. Slodzes balansētājs var izvēlēties starp daudzām mašīnām, lai lietotāju datplūsma tiktu sadalīta, nepārslogojot vienu sistēmas daļu.
Serveris pārvērš uzaicinājumu par žetoniem, kas ir skaitliskās vienības, kuras apstrādā valodas modelis. Šie žetoni un jebkurš iepriekšējās sarunas konteksts tiek ielādēti paātrinātāja atmiņā. Pēc tam GPU vai citas mākslīgā intelekta mikroshēmas veic matricas aprēķinu slāņus, izmantojot modeļa parametrus, lai prognozētu nākamo žetonu. Process atkārtojas daudzas reizes, līdz atbilde ir pilnīga vai sasniedz konfigurēto robežu.
Izveidotais rezultāts tiek dekodēts tekstā un pārraidīts atpakaļ lietotājam, bieži vien laikā, kad vēl tiek aprēķināti vēlākie žetoni. Ap šo redzamo mijiedarbību turpina darboties glabāšanas, tīkla, uzraudzības, enerģijas pārveidošanas un dzesēšanas iekārtas. Tāpēc pieprasījums patērē vairāk nekā tikai GPU izmērītā elektroenerģija, lai gan paātrinātājs parasti veic lielāko daļu intensīvo aprēķinu.
Kāpēc AI pieprasījumi patērē elektroenerģiju
Mākslīgā intelekta atziņa ir aktīvs aprēķins, nevis vienkārša iegūšana no datubāzes. Lielam modelim ir jāizvērtē daudzas skaitliskās operācijas katram ģenerētajam simbolam, izmantojot parametrus, kas var aizņemt desmitiem vai simtiem gigabaitu atmiņas. Šo parametru un starpvērtību pārvietošana starp ātrdarbīgu atmiņu un procesora kodoliem patērē elektroenerģiju līdztekus pašiem aprēķiniem.
Darba apjoms pieaug līdz ar modeli, izsaukumu un pieprasīto rezultātu. Garas sarunu vēstures prasa apstrādāt vairāk konteksta, savukārt garas atbildes liek paātrinātājiem darboties vairāk ģenerēšanas soļu. Attēlu, audio un video sistēmām var būt nepieciešami dažādi apstrādes cauruļvadi vai atkārtotas precizēšanas operācijas, tāpēc AI pieprasījums nav viena standartizēta darba vienība.
Nozīme ir arī datu centra pieskaitāmajām izmaksām. Serveriem ir nepieciešami barošanas avoti, tīkli, krātuves un dzesēšana, un daļa elektroenerģijas tiek zaudēta elektroenerģijas pārveidošanas un sadales laikā. Operatori bieži vien izsaka šo pieskaitāmo daļu, izmantojot enerģijas patēriņa efektivitāti jeb PUE. Efektīva iekārta kopējo enerģiju tuvina skaitļošanas iekārtu patērētajai enerģijai, savukārt mazāk efektīvai iekārtai ir nepieciešams vairāk atbalsta elektroenerģijas, lai nodrošinātu to pašu secinājumu darba slodzi.
Cik daudz elektroenerģijas patērē mākslīgā intelekta pieprasījums?
Nav universāla elektrības rādītāja, kas būtu piemērots AI pieprasījumam. Publiskās aplēses teksta mijiedarbībai parasti svārstās no daļskaitļa vātsstundas līdz vairākām vātsstundām, taču šis diapazons drīzāk jāuzskata par lieluma kārtu, nevis par fiksētu pārrēķinu. Īss pieprasījums, ko apstrādā optimizēts, labi izmantots modelis, var patērēt daudz mazāk enerģijas nekā gara atbilde no lielāka modeļa, kas darbojas ar nepietiekami izmantotu aparatūru.
Ar vātsstundu mēra enerģiju, nevis momentāno jaudu. Piemēram, serveris, kas daļu sekundes patērē lielu jaudu, var patērēt mazāk kopējās enerģijas nekā sistēma ar mazāku jaudu, kas darbojas daudz ilgāk. Tāpēc ticamam aprēķinam par katru pieprasījumu ir nepieciešams gan iekārtas patērētā jauda, gan ilgums un daļa, kas attiecināma uz pieprasījumu.
Salīdzinājumi ar meklēšanu tīmeklī, spuldzēm vai tālruņa uzlādi var atvieglot skalas vizualizāciju, taču tie bieži slēpj svarīgus pieņēmumus. Būtiskais jautājums nav par to, vai ikviens pamudinājums patērē vienu konkrētu daudzumu. Tas ir, kurš modelis apkalpoja pieprasījumu, cik daudz žetonu un modalitāšu tika apstrādāti, cik efektīvi pieprasījumi tika sagrupēti un cik daudz infrastruktūras enerģijas tika iekļauts aprēķinā.
Kāpēc aplēses atšķiras
Mākslīgā intelekta pakalpojumu sniedzēji reti publicē pilnīgus mērījumus, kas sasaista atsevišķus pieprasījumus ar modeļa lielumu, aparatūras izmantošanu, žetonu skaitu un iekārtas pieskaitāmajām izmaksām. Tāpēc pētniekiem ir jāapvieno atklātās aparatūras specifikācijas, etalonu rezultāti, aplēstais apkalpošanas laiks un datu centra efektivitātes pieņēmumi. Atšķirīgas izvēles jebkurā posmā var dot būtiski atšķirīgas atbildes.
Viens no galvenajiem atšķirību avotiem ir partiju veidošana. Secinājumu serveris var apstrādāt vairākus lietotājus kopā, dalot modeļa ielādi un aprēķinus partijā. Liela izmantošana var samazināt katram pieprasījumam piešķirto vidējo enerģiju, savukārt dīkstāves jauda, latentuma prasības vai datplūsmas lēcieni var atstāt dārgu aparatūru daļēji izmantotu. Jaunāki paātrinātāji var arī izpildīt to pašu darba slodzi ātrāk vai ar mazāku džoulu daudzumu.
Rezultātu maina arī aplēses robeža. Dažos aprēķinos tiek ņemta vērā tikai paātrinātāja enerģija, citos - arī procesora, atmiņas, tīkla, dzesēšanas un enerģijas zudumi. Lielākajā daļā skaitļu par vienu pieprasījumu nav iekļauta iepriekš aparatūras ražošanai un modeļa apmācībai izmantotā enerģija. Aprēķini ir visnoderīgākie, ja to sistēmas robežas un pieņēmumi ir skaidri norādīti, nevis ja viens skaitlis tiek uzrādīts kā universāls.
Mākslīgā intelekta pieprasījumi pret mākslīgā intelekta apmācību
Apmācot tiek izveidots vai atjaunināts modelis, atkārtoti apstrādājot lielas datu kopas un pielāgojot tā parametrus. Liels apmācības cikls var aizņemt tūkstošiem paātrinātāju dienām vai nedēļām ilgi, padarot to par koncentrētu un labi pamanāmu skaitļošanas pasākumu. Kad apmācība ir pabeigta, iegūto modeli var izvietot daudzos secinājumu serveros, lai atbildētu uz lietotāju pieprasījumiem.
Vienai mijiedarbībai parasti ir daudz mazāka, taču tā ir nepārtraukta. Ražošanas sistēmām ir jāreaģē jebkurā stundā, jāsaglabā pietiekama kapacitāte, lai varētu reaģēt uz maksimumu, un jāapkalpo lietotāji vairākos reģionos. Tāpēc enerģijas profils tiek sadalīts pa daudziem datu centriem un atkārtojas katru reizi, kad tiek ģenerēts teksts, attēli, audio vai citi rezultāti.
Neviena no šīm darba slodzēm nav automātiski jāuzskata par dominējošo modeļa elektroenerģijas patēriņā visā tā darbības laikā. Apmācība var būt lielākais vienreizējais darbs, jo īpaši robežsistēmās, bet secinājumi var pārsniegt to, ja pakalpojums apstrādā milzīgu datplūsmu mēnešiem vai gadiem. Līdzsvars ir atkarīgs no tā, cik bieži modeļi tiek pārkvalificēti, cik plaši tie tiek izvietoti un cik intensīvi cilvēki tos izmanto.
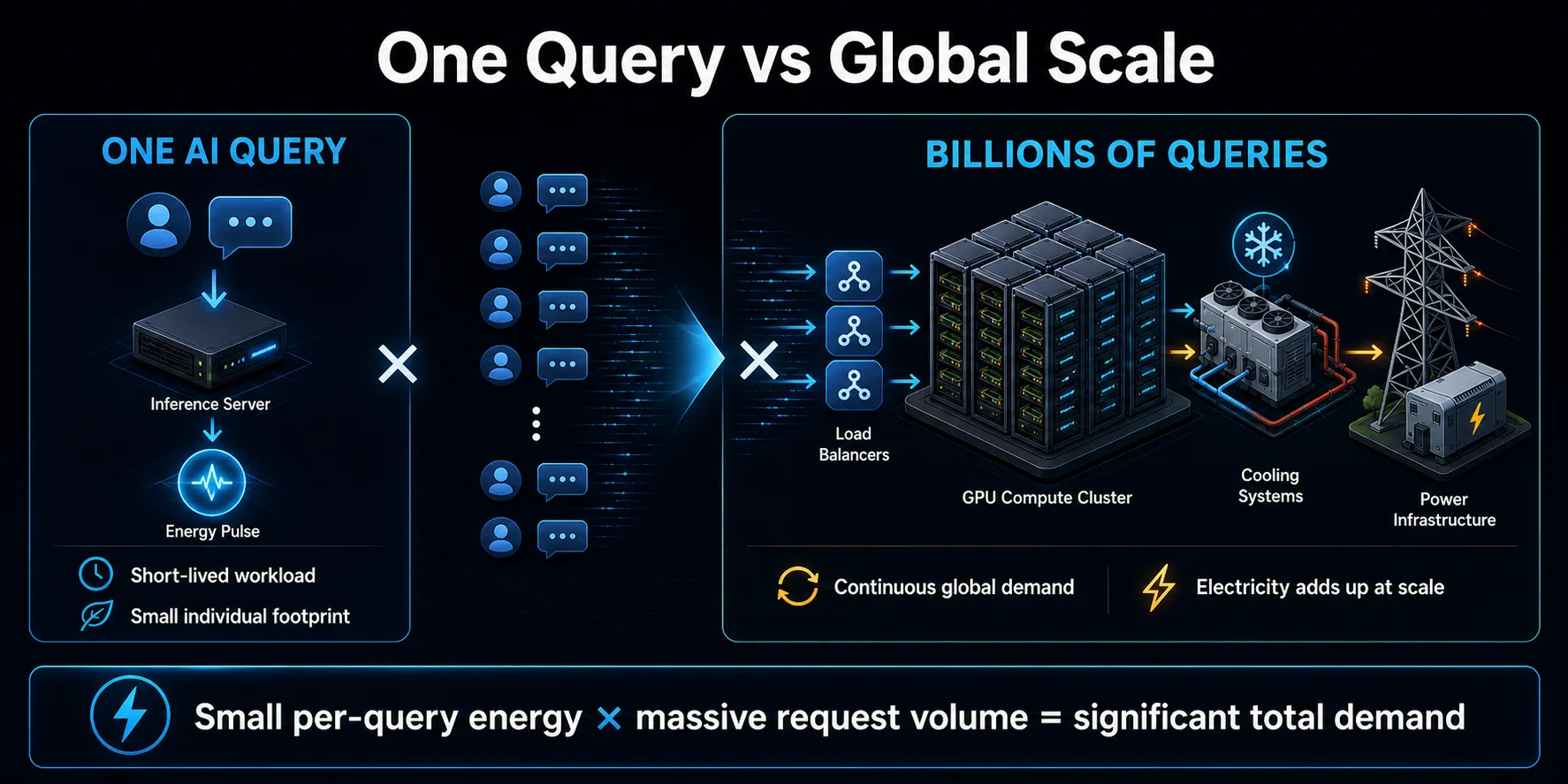
Miljardiem vaicājumu summējas
Mākslīgā intelekta vaicājumu nozīme videi galvenokārt ir saistīta ar pavairošanu. Viens īss pieprasījums var būt neliels enerģijas daudzums, taču patērētāju palīgi, meklēšanas funkcijas, kodēšanas rīki un biznesa lietojumprogrammas var radīt milzīgu pieprasījumu skaitu. Nepārtraukti atkārtojot, neliela viena pieprasījuma enerģija kļūst par ievērojamu datu centra slodzi.
Pieprasījums neaprobežojas tikai ar redzamiem čatbota ziņojumiem. Lietojumprogrammas var veikt vairākus modeļa izsaukumus, lai atbildētu uz vienu lietotāja darbību, izmantot atsevišķus modeļus moderēšanai vai atgūšanai, atkārtot neveiksmīgus pieprasījumus un ģenerēt fona kopsavilkumus vai ieteikumus. Aģentiskās sistēmas var paplašināt šo modeli, atkārtoti izsaucot modeļus un programmatūras rīkus, izpildot vienu uzdevumu.
Infrastruktūras plānošanu ietekmē arī mērogs. Pakalpojumu sniedzēji veido jaudu, kas paredzēta izaugsmei un maksimālai datplūsmai, kas var palielināt pieprasījumu pēc elektroenerģijas, pirms katrs serveris tiek pilnībā izmantots. Kopējā ietekme ir atkarīga gan no efektivitātes uz vienu pieprasījumu, gan no izmantošanas pieauguma tempa. Ja pieprasījums pieaug ātrāk nekā efektivitāte uzlabojas, kopējais elektroenerģijas patēriņš var turpināt pieaugt pat tad, ja katra atsevišķa mijiedarbība kļūst mazāk energoietilpīga.
Vai mākslīgā intelekta pieprasījumi kļūs efektīvāki?
Mākslīgā intelekta secinājumi, visticamāk, kļūs energoefektīvāki salīdzināma uzdevuma līmenī. Jaunie paātrinātāji nodrošina vairāk aprēķinu uz vienu elektrības vienību, savukārt kvantizācija, atdalīšana, spekulatīvā dekodēšana un uzlabotas modeļu arhitektūras var samazināt operāciju skaitu, kas nepieciešamas, lai iegūtu noderīgu rezultātu. Labāka plānošana un pakešu veidošana var arī palielināt aparatūras izmantošanu, nemainot lietotāja pieredzi.
Mazāki specializētie modeļi piedāvā citu ceļu. Pakalpojumam ne vienmēr ir nepieciešams lielākais modelis klasifikācijai, ieguvei vai rutīnas jautājumiem. Vienkāršu darbu novirzīšana kompaktiem modeļiem, nevajadzīga konteksta ierobežošana un atkārtoti izmantojamu rezultātu kešēšana var samazināt gan latentumu, gan elektroenerģijas patēriņu. Datu centri var vēl vairāk uzlabot kopējo efektivitāti, izmantojot enerģijas piegādi, dzesēšanu un darba slodzes izvietojumu.
Efektivitāte negarantē zemāku kopējo patēriņu. Ātrāks un lētāks mākslīgais intelekts var veicināt vairāk lietojumprogrammu, ilgāku mijiedarbību un jaunas skaitļošanas ietilpīgas funkcijas, kas dažkārt tiek dēvēts par pieprasījuma atsitiena efektu. Tāpēc nākotnē mākslīgā intelekta pieprasījumu elektrības ietekme būs atkarīga no divām konkurējošām tendencēm: cik ātri katra lietderīgā darba vienība kļūs efektīvāka un cik ātri pieaugs mākslīgā intelekta izmantošanas kopējais apjoms un sarežģītība.