Inhoud
Training begint met gegevens
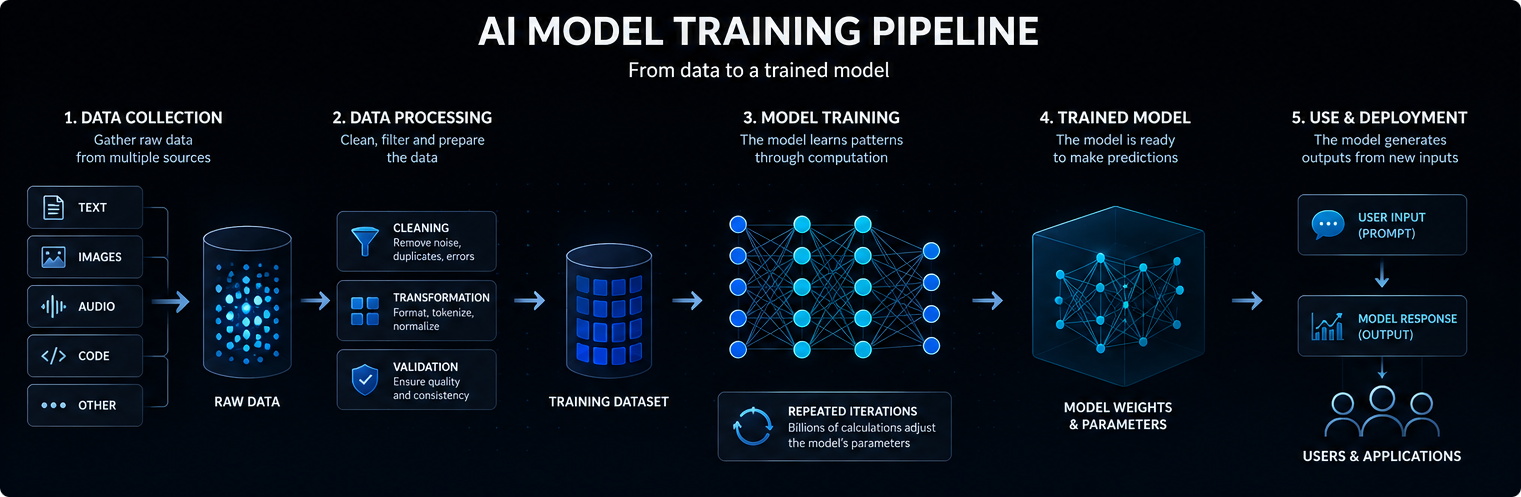
Het trainen van een AI-model begint met gegevens. Afhankelijk van het model kunnen deze gegevens bestaan uit tekst, afbeeldingen, audio, code, video, wetenschappelijke metingen of gestructureerde records.
Grote taalmodellen worden getraind op enorme verzamelingen tekst en code, zodat ze statistische relaties kunnen leren tussen woorden, concepten, instructies en uitgangen.
De kwaliteit, diversiteit en structuur van de trainingsgegevens beïnvloeden sterk wat het model kan leren, hoe goed het generaliseert en waar zijn beperkingen liggen.
Neurale netwerken en parameters
Moderne AI-modellen zijn meestal gebaseerd op neurale netwerken. Deze netwerken bestaan uit vele lagen met wiskundige bewerkingen die invoergegevens omzetten in voorspellingen, classificaties of gegenereerde resultaten.
De interne waarden die tijdens de training worden aangepast, worden parameters genoemd. Grote AI-modellen kunnen miljarden of zelfs biljoenen parameters bevatten.
Training is het proces waarbij deze parameters worden aangepast, zodat het model beter wordt in het voorspellen, classificeren, genereren of redeneren op basis van nieuwe invoer. Eenvoudig gezegd werkt een AI-model door invoer om te zetten in interne signalen, die signalen door aangeleerde parameters te leiden en zo de meest waarschijnlijke, bruikbare uitvoer te genereren.
Hoe leren eigenlijk gebeurt
Tijdens de training verwerkt het model voorbeelden en produceert het voorspellingen. Deze voorspellingen worden vergeleken met de verwachte output of trainingsdoelen.
Als het model fouten maakt, passen optimalisatiealgoritmen de parameters een beetje aan. Dit proces wordt vele malen herhaald over enorme datasets.
Na verloop van tijd leert het model statistische patronen waardoor het nuttiger outputs kan produceren wanneer het later nieuwe prompts of inputs ontvangt.
Waarom training zoveel rekenkracht vereist
Het trainen van grote AI-modellen vereist enorme rekenkracht omdat miljarden parameters herhaaldelijk moeten worden bijgewerkt over enorme hoeveelheden gegevens.
Dit proces wordt meestal verdeeld over grote GPU-clusters in gespecialiseerde datacenters. De GPU's voeren parallelle wiskundige bewerkingen veel sneller uit dan conventionele processors.
Hoe groter het model en de dataset, hoe meer rekenkracht, elektriciteit, koeling en infrastructuur nodig zijn.
Hoe lang duurt AI-training?
De trainingsduur varieert sterk. Kleine modellen kunnen in enkele minuten of uren getraind worden, terwijl grensverleggende modellen weken of maanden gecoördineerd rekenwerk kunnen vereisen.
De trainingstijd hangt af van de grootte van het model, de grootte van de dataset, de beschikbaarheid van hardware, optimalisatietechnieken en het aantal GPU's dat parallel wordt gebruikt.
Grote AI-laboratoria investeren veel in infrastructuur omdat ze door snellere trainingscycli meer ideeën kunnen testen, modellen sneller kunnen verbeteren en nieuwe systemen sneller kunnen inzetten.
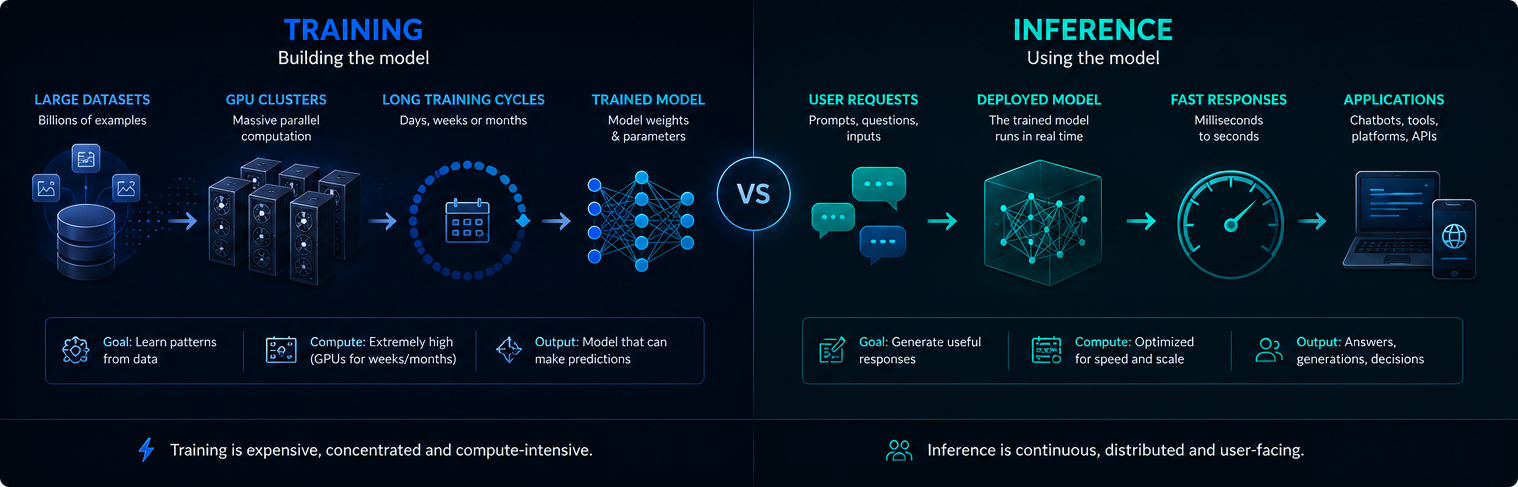
Training vs inferentie
Training en inferentie zijn verschillende fasen van een AI-infrastructuur. Training creëert het model of werkt het bij, terwijl inferentie het getrainde model gebruikt om verzoeken van gebruikers te beantwoorden.
Training is meestal geconcentreerd en extreem rekenintensief. Inferentie is continu, omdat AI-systemen miljoenen aanwijzingen per dag kunnen geven.
Beide fasen zijn van belang voor de vraag naar elektriciteit, het gebruik van GPU's en de impact van moderne AI op het milieu.
De toekomst van AI-training
AI-training zal waarschijnlijk efficiënter worden door betere hardware, verbeterde algoritmen, kleinere gespecialiseerde modellen en meer geoptimaliseerde datapijplijnen.
Tegelijkertijd blijft de vraag naar meer capabele modellen groeien. Efficiëntieverbeteringen kunnen de kosten van individuele werklasten verlagen, terwijl de totale vraag naar computers nog steeds toeneemt.
Begrijpen hoe AI-modellen worden getraind is essentieel voor het evalueren van de toekomst van AI-infrastructuur, energieverbruik en technologische vooruitgang.