Conteúdo
O treino começa com os dados
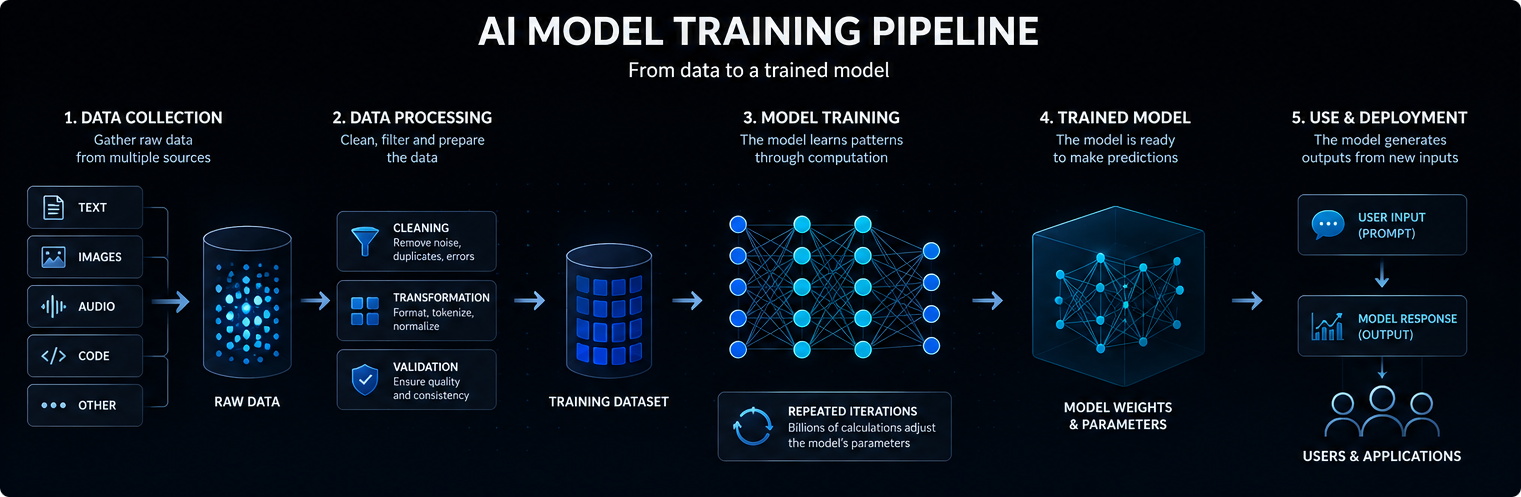
O treino de um modelo de IA começa com dados. Dependendo do modelo, estes dados podem incluir texto, imagens, áudio, código, vídeo, medições científicas ou registos estruturados.
Os modelos de linguagem de grande dimensão são treinados em vastas colecções de texto e código para que possam aprender relações estatísticas entre palavras, conceitos, instruções e resultados.
A qualidade, a diversidade e a estrutura dos dados de treino influenciam fortemente o que o modelo pode aprender, a sua generalização e as suas limitações.
Redes neuronais e parâmetros
Os modelos modernos de IA baseiam-se geralmente em redes neurais. Estas redes contêm várias camadas de operações matemáticas que transformam os dados de entrada em previsões, classificações ou resultados gerados.
Os valores internos ajustados durante o treino são designados por parâmetros. Os grandes modelos de IA podem conter milhares de milhões ou mesmo biliões de parâmetros.
O treino consiste no processo de ajustar esses parâmetros para que o modelo se torne mais eficaz na previsão, classificação, geração ou raciocínio sobre novos dados de entrada. Em termos simples, um modelo de IA funciona convertendo um dado de entrada em sinais internos, submetendo esses sinais aos parâmetros aprendidos e produzindo o resultado mais provável e útil.
Como é que a aprendizagem acontece de facto
Durante o treino, o modelo processa exemplos e produz previsões. Essas previsões são comparadas com os resultados esperados ou com os objectivos de treino.
Quando o modelo comete erros, os algoritmos de otimização ajustam ligeiramente os seus parâmetros. Este processo é repetido muitas vezes em enormes conjuntos de dados.
Ao longo do tempo, o modelo aprende padrões estatísticos que lhe permitem produzir resultados mais úteis quando recebe novas solicitações ou entradas.
Porque é que o treino requer tanta computação
O treino de grandes modelos de IA requer uma computação maciça, porque milhares de milhões de parâmetros têm de ser actualizados repetidamente em grandes volumes de dados.
Este processo é normalmente distribuído por grandes clusters de GPU em centros de dados especializados. As GPUs efectuam operações matemáticas paralelas muito mais rapidamente do que os processadores convencionais.
Quanto maior for o modelo e o conjunto de dados, maior será a necessidade de computação, eletricidade, refrigeração e infraestrutura.
Quanto tempo demora o treino em IA?
A duração do treino varia muito. Os modelos pequenos podem ser treinados em minutos ou horas, enquanto os modelos de fronteira podem exigir semanas ou meses de computação coordenada.
O tempo de treino depende do tamanho do modelo, do tamanho do conjunto de dados, da disponibilidade de hardware, das técnicas de otimização e do número de GPUs utilizadas em paralelo.
Os grandes laboratórios de IA investem fortemente em infra-estruturas porque os ciclos de treino mais rápidos permitem-lhes testar mais ideias, melhorar os modelos mais rapidamente e implementar novos sistemas mais cedo.
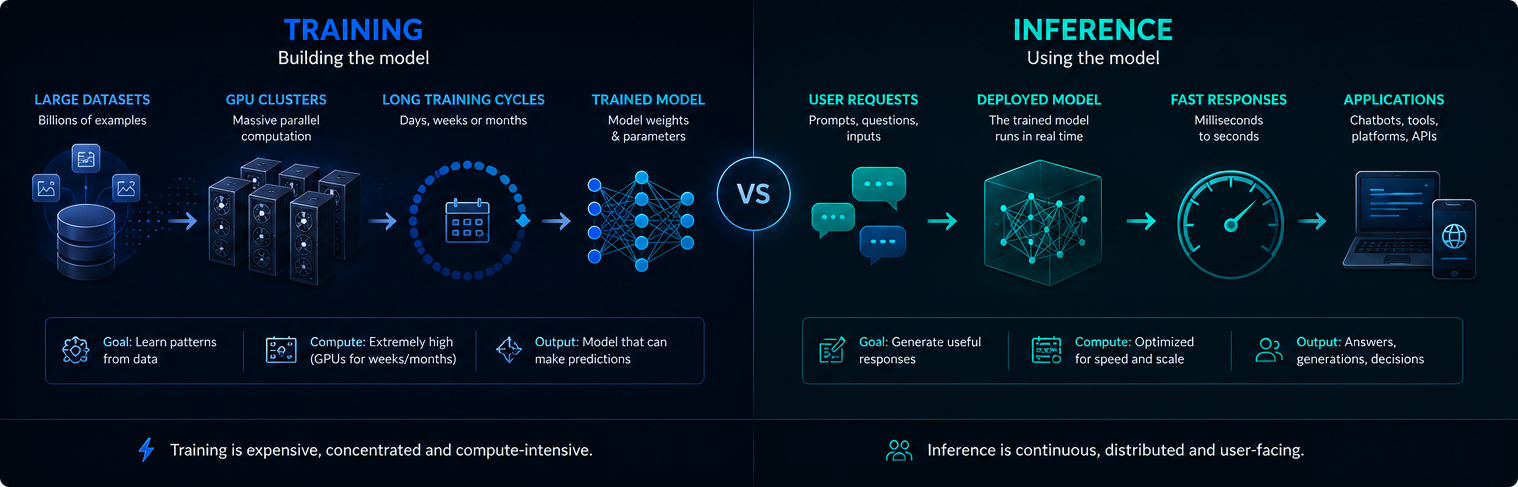
Treino vs inferência
O treino e a inferência são fases diferentes da infraestrutura de IA. O treino cria ou actualiza o modelo, enquanto a inferência utiliza o modelo treinado para responder aos pedidos dos utilizadores.
O treino é normalmente concentrado e extremamente intensivo em termos de computação. A inferência é contínua, porque os sistemas de IA implementados podem servir milhões de pedidos todos os dias.
Ambas as fases são importantes para a procura de eletricidade, a utilização de GPU e o impacto ambiental da IA moderna.
O futuro do treino em IA
É provável que o treino em IA se torne mais eficiente através de melhor hardware, algoritmos melhorados, modelos especializados mais pequenos e pipelines de dados mais optimizados.
Ao mesmo tempo, a procura de modelos mais capazes continua a crescer. As melhorias de eficiência podem reduzir o custo de cargas de trabalho individuais, enquanto a procura total de computação continua a aumentar.
Compreender a forma como os modelos de IA são treinados é essencial para avaliar o futuro das infra-estruturas de IA, a utilização de energia e o progresso tecnológico.