Isi
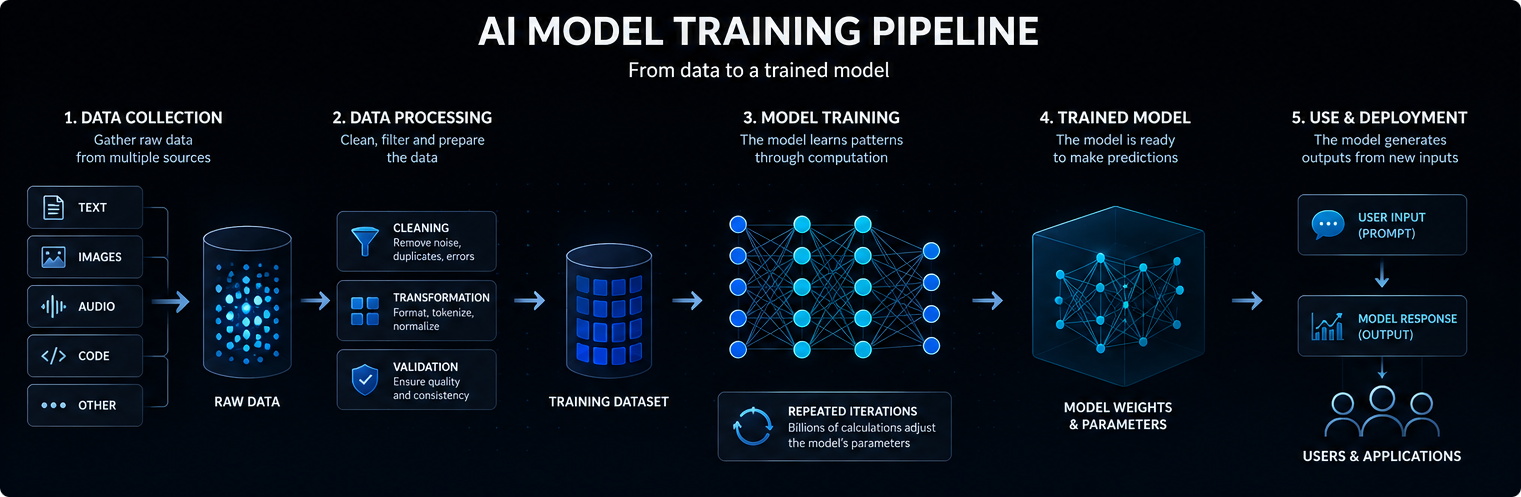
Pelatihan dimulai dengan data
Melatih model AI dimulai dengan data. Bergantung pada modelnya, data ini dapat mencakup teks, gambar, audio, kode, video, pengukuran ilmiah, atau catatan terstruktur.
Model bahasa besar dilatih dengan koleksi teks dan kode yang sangat banyak sehingga dapat mempelajari hubungan statistik antara kata, konsep, instruksi, dan keluaran.
Kualitas, keragaman, dan struktur data pelatihan sangat memengaruhi apa yang dapat dipelajari oleh model, seberapa baik model dapat menggeneralisasi, dan di mana keterbatasannya.
Jaringan dan parameter saraf
Model AI modern biasanya didasarkan pada jaringan saraf. Jaringan-jaringan ini terdiri dari banyak lapisan operasi matematis yang mengubah data masukan menjadi prediksi, klasifikasi, atau hasil yang dihasilkan.
Nilai internal yang disesuaikan selama pelatihan disebut parameter. Model AI yang besar dapat berisi miliaran atau bahkan triliunan parameter.
Pelatihan adalah proses penyesuaian parameter-parameter tersebut agar model menjadi lebih baik dalam memprediksi, mengklasifikasikan, menghasilkan, atau melakukan penalaran terhadap masukan baru. Secara sederhana, model AI bekerja dengan mengubah masukan menjadi sinyal internal, mengalirkan sinyal-sinyal tersebut melalui parameter yang telah dipelajari, dan menghasilkan keluaran yang paling mungkin berguna.
Bagaimana pembelajaran sebenarnya terjadi
Selama pelatihan, model memproses contoh dan menghasilkan prediksi. Prediksi tersebut dibandingkan dengan hasil yang diharapkan atau tujuan pelatihan.
Ketika model membuat kesalahan, algoritme pengoptimalan akan menyesuaikan sedikit parameternya. Proses ini diulang berkali-kali di seluruh kumpulan data yang sangat besar.
Seiring berjalannya waktu, model mempelajari pola statistik yang memungkinkannya menghasilkan output yang lebih berguna ketika nantinya menerima perintah atau input baru.
Mengapa pelatihan membutuhkan begitu banyak komputasi
Melatih model AI yang besar membutuhkan komputasi yang sangat besar karena miliaran parameter harus diperbarui berulang kali pada volume data yang sangat besar.
Proses ini biasanya didistribusikan di seluruh cluster GPU besar di dalam pusat data khusus. GPU melakukan operasi matematika paralel jauh lebih cepat daripada prosesor konvensional.
Semakin besar model dan dataset, semakin banyak komputasi, listrik, pendinginan dan infrastruktur yang dibutuhkan.
Berapa lama waktu yang dibutuhkan untuk pelatihan AI?
Durasi pelatihan sangat bervariasi. Model kecil dapat dilatih dalam hitungan menit atau jam, sementara model frontier mungkin memerlukan waktu berminggu-minggu atau berbulan-bulan untuk melakukan perhitungan yang terkoordinasi.
Waktu pelatihan tergantung pada ukuran model, ukuran set data, ketersediaan perangkat keras, teknik pengoptimalan, dan jumlah GPU yang digunakan secara paralel.
Laboratorium AI besar berinvestasi besar-besaran dalam infrastruktur karena siklus pelatihan yang lebih cepat memungkinkan mereka menguji lebih banyak ide, meningkatkan model dengan lebih cepat, dan menerapkan sistem baru lebih cepat.
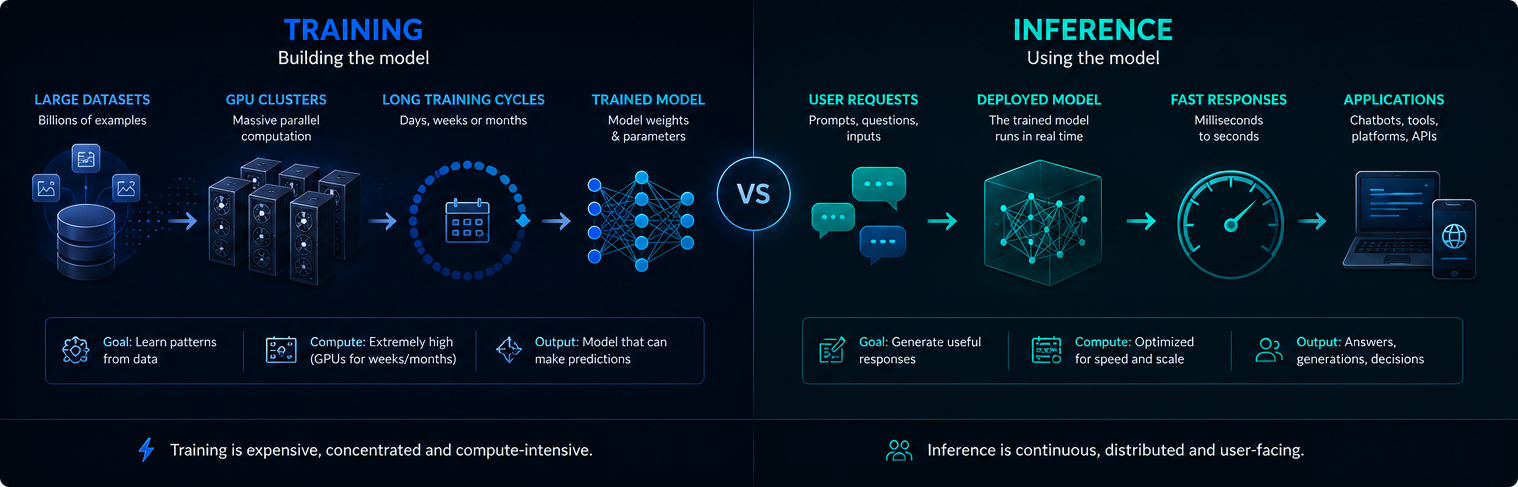
Pelatihan vs kesimpulan
Pelatihan dan inferensi adalah fase yang berbeda dari infrastruktur AI. Pelatihan membuat atau memperbarui model, sedangkan inferensi menggunakan model yang telah dilatih untuk menjawab permintaan pengguna.
Pelatihan biasanya terkonsentrasi dan sangat intensif dalam hal komputasi. Inferensi bersifat kontinu, karena sistem AI yang digunakan dapat melayani jutaan permintaan setiap hari.
Kedua fase tersebut berpengaruh terhadap kebutuhan listrik, penggunaan GPU, dan dampak lingkungan dari AI modern.
Masa depan pelatihan AI
Pelatihan AI cenderung menjadi lebih efisien melalui perangkat keras yang lebih baik, algoritme yang lebih baik, model khusus yang lebih kecil, dan jalur data yang lebih dioptimalkan.
Pada saat yang sama, permintaan untuk model yang lebih mumpuni terus meningkat. Peningkatan efisiensi dapat mengurangi biaya beban kerja individu sementara total permintaan komputasi masih meningkat.
Memahami bagaimana model AI dilatih sangat penting untuk mengevaluasi masa depan infrastruktur AI, penggunaan energi, dan kemajuan teknologi.