Daftar isi
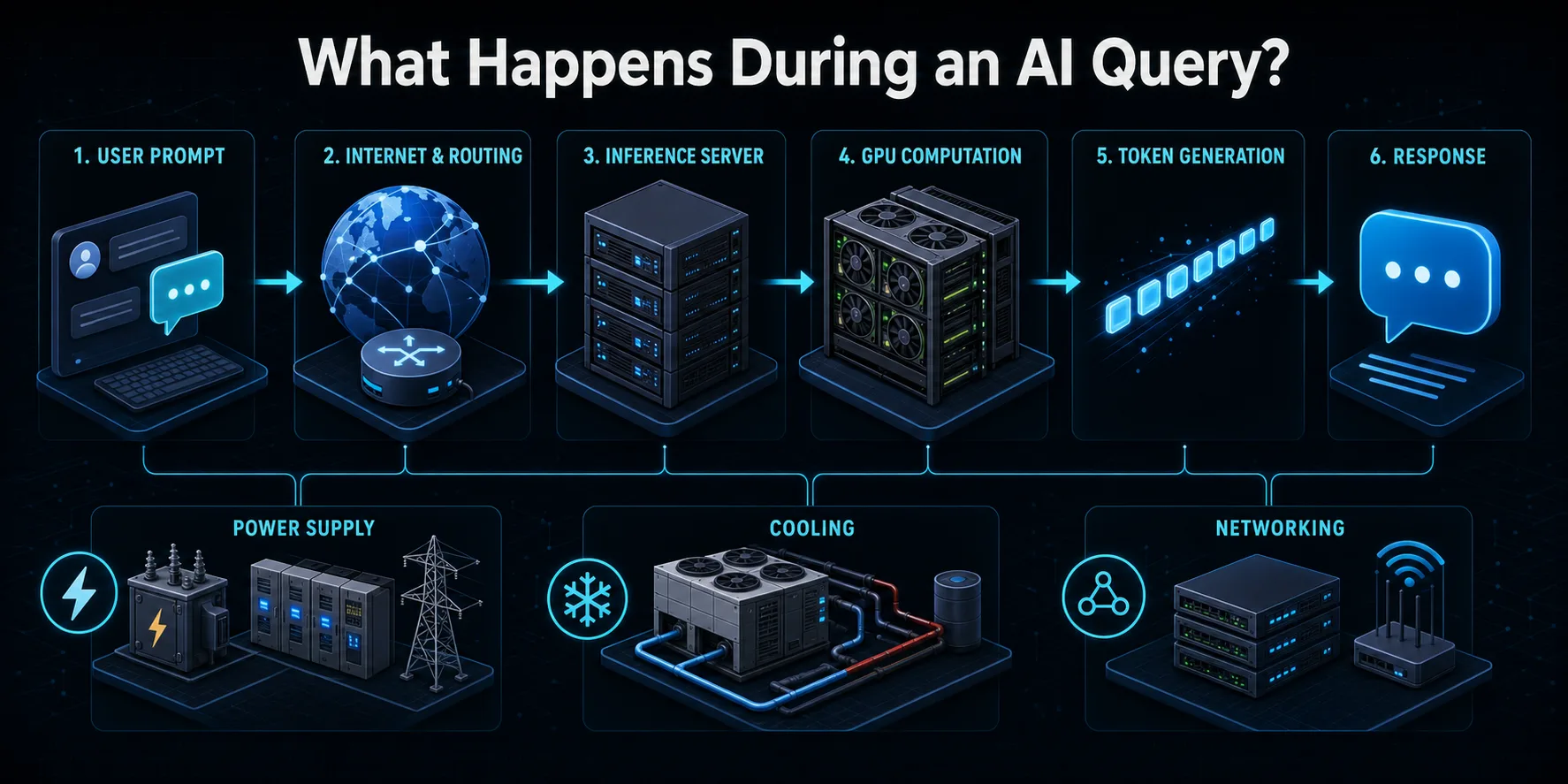
Apa yang terjadi ketika Anda mengirim kueri AI?
Ketika Anda mengirimkan permintaan ke layanan AI, permintaan tersebut pertama-tama berjalan melalui internet ke infrastruktur penyedia. Sistem perutean mengautentikasi permintaan, menerapkan kontrol keamanan dan penggunaan, dan mengarahkannya ke server inferensi yang tersedia. Penyeimbang beban dapat memilih di antara banyak mesin sehingga lalu lintas pengguna didistribusikan tanpa membebani salah satu bagian sistem.
Server mengubah prompt menjadi token, unit numerik yang diproses oleh model bahasa. Token-token tersebut dan konteks percakapan sebelumnya dimuat ke dalam memori akselerator. GPU atau chip AI lainnya kemudian melakukan perhitungan matriks berlapis-lapis di seluruh parameter model untuk memprediksi token berikutnya. Proses ini berulang berkali-kali hingga respons selesai atau mencapai batas yang dikonfigurasi.
Output yang dihasilkan diterjemahkan ke dalam teks dan dialirkan kembali ke pengguna, sering kali ketika token yang dihasilkan masih dihitung. Di sekitar interaksi yang terlihat ini, penyimpanan, jaringan, pemantauan, konversi daya, dan peralatan pendingin tetap aktif. Oleh karena itu, sebuah kueri menggunakan lebih banyak daya daripada listrik yang diukur pada GPU saja, meskipun akselerator biasanya melakukan sebagian besar komputasi intensif.
Mengapa kueri AI mengkonsumsi listrik
Inferensi AI adalah komputasi aktif, bukan pengambilan sederhana dari database. Sebuah model yang besar harus mengevaluasi banyak operasi numerik untuk setiap token yang dihasilkan, menggunakan parameter yang mungkin menempati puluhan atau ratusan gigabyte memori. Memindahkan parameter-parameter tersebut dan nilai-nilai perantara antara memori bandwidth tinggi dan inti prosesor menghabiskan listrik di samping perhitungan itu sendiri.
Jumlah pekerjaan bertambah seiring dengan model, prompt, dan output yang diminta. Riwayat percakapan yang panjang membutuhkan lebih banyak konteks untuk diproses, sementara jawaban yang panjang membuat akselerator terus bekerja untuk lebih banyak langkah pembuatan. Sistem gambar, audio, dan video dapat memerlukan jalur pemrosesan yang berbeda atau operasi penyempurnaan yang berulang-ulang, sehingga kueri AI bukanlah satu unit kerja yang terstandardisasi.
Biaya overhead pusat data juga penting. Server membutuhkan pasokan listrik, jaringan, penyimpanan dan pendinginan, dan sebagian listrik hilang selama konversi dan distribusi daya. Operator sering kali menyatakan biaya overhead ini melalui efektivitas penggunaan daya, atau PUE. Fasilitas yang efisien membawa energi total lebih dekat dengan energi yang digunakan oleh peralatan komputasi, sementara fasilitas yang kurang efisien membutuhkan lebih banyak listrik pendukung untuk beban kerja kesimpulan yang sama.
Berapa banyak listrik yang digunakan oleh kueri AI?
Tidak ada angka listrik universal untuk kueri AI. Perkiraan publik untuk interaksi teks biasanya berkisar dari sepersekian watt-jam hingga beberapa watt-jam, tetapi kisaran tersebut harus diperlakukan sebagai urutan besarnya daripada konversi tetap. Permintaan singkat yang ditangani oleh model yang dioptimalkan dan digunakan dengan baik dapat menggunakan energi yang jauh lebih sedikit daripada respons panjang dari model yang lebih besar yang berjalan pada perangkat keras yang kurang digunakan.
Watt-jam mengukur energi, bukan daya sesaat. Sebagai contoh, server yang menarik daya tinggi selama sepersekian detik mungkin menggunakan energi total yang lebih sedikit daripada sistem berdaya rendah yang berjalan lebih lama. Oleh karena itu, perkiraan per kueri yang kredibel membutuhkan daya yang digunakan peralatan serta durasi dan bagian dari peralatan tersebut yang dapat diatribusikan pada permintaan.
Perbandingan dengan pencarian web, bola lampu, atau pengisian daya ponsel dapat membuat skala lebih mudah divisualisasikan, tetapi sering kali menyembunyikan asumsi yang penting. Pertanyaan yang relevan bukanlah apakah setiap permintaan menghabiskan jumlah tertentu. Ini adalah model mana yang melayani permintaan, berapa banyak token dan modalitas yang diproses, seberapa efisien permintaan dikelompokkan, dan berapa banyak energi infrastruktur yang dimasukkan dalam perhitungan.
Mengapa perkiraan bervariasi
Penyedia AI jarang mempublikasikan pengukuran lengkap yang menghubungkan permintaan individu dengan ukuran model, pemanfaatan perangkat keras, jumlah token, dan biaya overhead fasilitas. Oleh karena itu, para peneliti harus menggabungkan spesifikasi perangkat keras yang diungkapkan, hasil tolok ukur, perkiraan waktu penyajian, dan asumsi efisiensi pusat data. Pilihan yang berbeda pada setiap langkah dapat menghasilkan jawaban yang sangat berbeda.
Batching adalah salah satu sumber utama variasi. Server inferensi dapat memproses beberapa pengguna secara bersamaan, berbagi pemuatan model dan komputasi di seluruh batch. Pemanfaatan yang tinggi dapat mengurangi energi rata-rata yang diberikan untuk setiap permintaan, sementara kapasitas menganggur, persyaratan latensi, atau lonjakan lalu lintas dapat membuat perangkat keras yang mahal digunakan sebagian. Akselerator yang lebih baru juga dapat menyelesaikan beban kerja yang sama dengan lebih cepat atau dengan lebih sedikit joule.
Batasan estimasi juga mengubah hasilnya. Beberapa perhitungan hanya menghitung energi akselerator; yang lainnya termasuk CPU, memori, jaringan, pendinginan, dan kehilangan daya. Sebagian besar angka per kueri tidak termasuk energi sebelumnya yang digunakan untuk memproduksi perangkat keras dan melatih model. Estimasi paling berguna ketika batas sistem dan asumsi mereka eksplisit, bukan ketika satu angka disajikan secara universal.
Pertanyaan AI versus pelatihan AI
Pelatihan membuat atau memperbarui model dengan berulang kali memproses kumpulan data yang besar dan menyesuaikan parameternya. Proses pelatihan yang besar dapat menghabiskan ribuan akselerator selama berhari-hari atau berminggu-minggu, sehingga menjadikannya sebagai peristiwa komputasi yang terkonsentrasi dan sangat terlihat. Setelah pelatihan selesai, model yang dihasilkan dapat digunakan di banyak server inferensi untuk menjawab permintaan pengguna.
Inferensi biasanya jauh lebih kecil untuk satu interaksi, tetapi bersifat kontinu. Sistem produksi harus merespons pada jam berapa pun, menjaga agar kapasitas tetap tersedia untuk puncak dan melayani pengguna di berbagai wilayah. Oleh karena itu, profil energi didistribusikan ke banyak pusat data dan diulang setiap kali teks, gambar, audio, atau output lainnya dihasilkan.
Tidak ada beban kerja yang secara otomatis diasumsikan mendominasi penggunaan listrik seumur hidup model. Pelatihan mungkin merupakan peristiwa tunggal terbesar, terutama untuk sistem frontier, sementara inferensi pada akhirnya dapat melebihi itu ketika layanan menangani lalu lintas yang sangat besar selama berbulan-bulan atau bertahun-tahun. Keseimbangannya tergantung pada seberapa sering model dilatih ulang, seberapa luas model tersebut digunakan dan seberapa intensif orang menggunakannya.
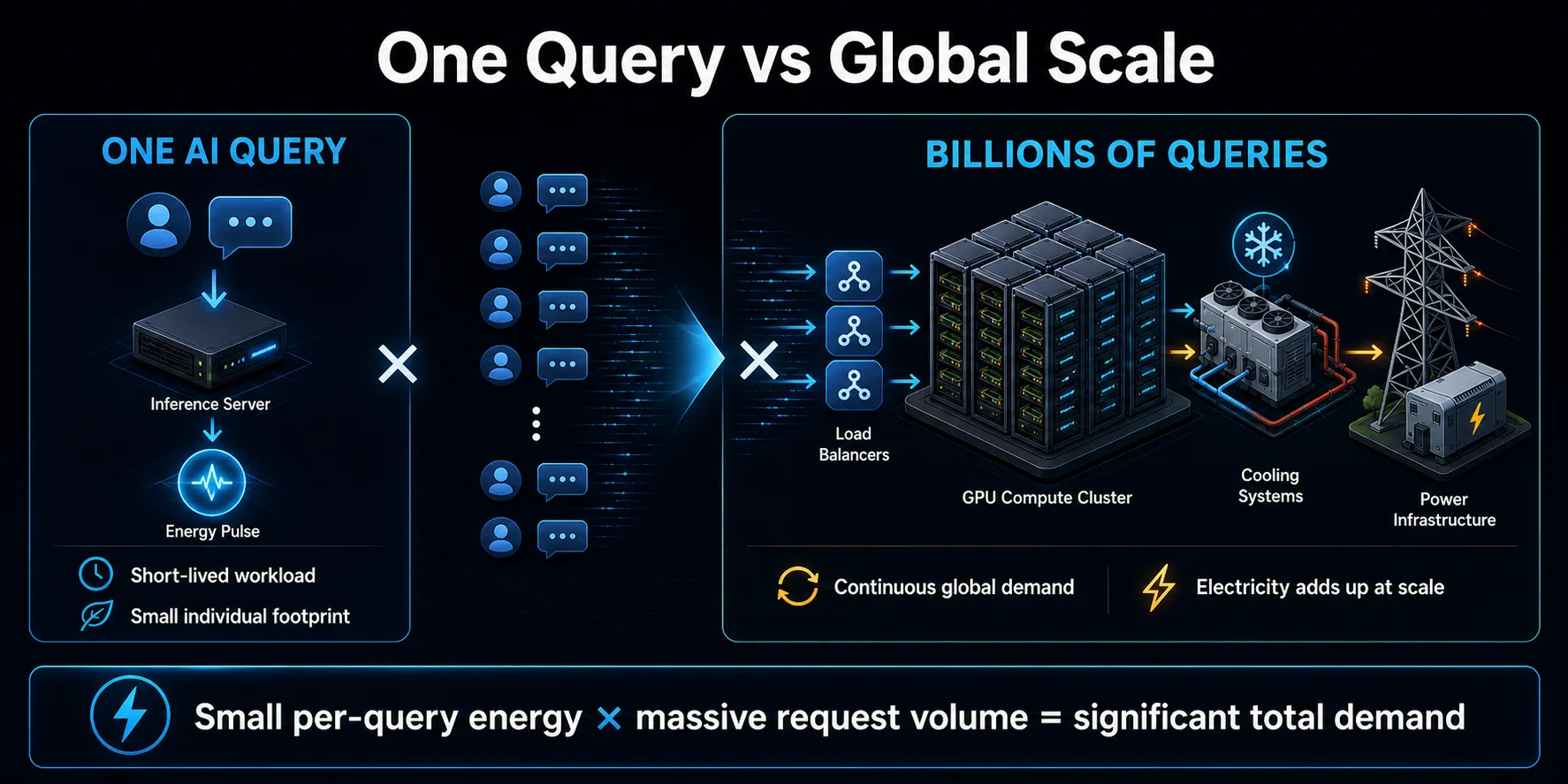
Miliaran pertanyaan bertambah
Signifikansi lingkungan dari permintaan AI terutama berasal dari penggandaan. Satu permintaan singkat dapat mewakili sejumlah kecil energi, namun asisten konsumen, fitur pencarian, alat pengkodean, dan aplikasi bisnis dapat menghasilkan sejumlah besar permintaan. Jika diulang terus menerus, energi per permintaan yang kecil menjadi beban pusat data yang besar.
Permintaan tidak terbatas pada pesan chatbot yang terlihat. Aplikasi dapat membuat beberapa panggilan model untuk menjawab satu tindakan pengguna, menggunakan model terpisah untuk moderasi atau pengambilan, mencoba kembali permintaan yang gagal, dan menghasilkan ringkasan latar belakang atau rekomendasi. Sistem agentik dapat memperluas pola ini dengan memanggil model dan alat perangkat lunak berulang kali saat menyelesaikan satu tugas.
Skala juga mempengaruhi perencanaan infrastruktur. Penyedia layanan membangun kapasitas untuk pertumbuhan dan lalu lintas puncak, yang dapat meningkatkan permintaan listrik sebelum setiap server digunakan sepenuhnya. Dampak totalnya tergantung pada efisiensi per permintaan dan laju pertumbuhan penggunaan. Jika permintaan tumbuh lebih cepat daripada peningkatan efisiensi, konsumsi listrik secara keseluruhan dapat terus meningkat meskipun setiap interaksi individu menjadi lebih hemat energi.
Akankah kueri AI menjadi lebih efisien?
Inferensi AI cenderung menjadi lebih hemat energi pada tingkat tugas yang sebanding. Akselerator baru menghasilkan lebih banyak komputasi per unit listrik, sementara kuantisasi, pemangkasan, penguraian spekulatif, dan arsitektur model yang lebih baik dapat mengurangi operasi yang diperlukan untuk menghasilkan output yang bermanfaat. Penjadwalan dan pengelompokan yang lebih baik juga dapat meningkatkan pemanfaatan perangkat keras tanpa mengubah pengalaman pengguna.
Model-model khusus yang lebih kecil menawarkan jalan lain. Sebuah layanan tidak selalu membutuhkan model terbesar untuk klasifikasi, ekstraksi, atau pertanyaan rutin. Merutekan pekerjaan sederhana ke model yang ringkas, membatasi konteks yang tidak perlu, dan menyimpan hasil yang dapat digunakan kembali dapat mengurangi latensi dan penggunaan listrik. Pusat data dapat meningkatkan efisiensi total lebih lanjut melalui pengiriman daya, pendinginan, dan penempatan beban kerja.
Efisiensi tidak menjamin konsumsi keseluruhan yang lebih rendah. AI yang lebih cepat dan lebih murah dapat mendorong lebih banyak aplikasi, interaksi yang lebih lama, dan fitur-fitur baru yang intensif dalam hal komputasi, sebuah efek yang terkadang digambarkan sebagai permintaan yang meningkat. Oleh karena itu, jejak listrik masa depan dari kueri AI akan bergantung pada dua tren yang saling bersaing: seberapa cepat setiap unit pekerjaan yang berguna menjadi lebih efisien, dan seberapa cepat total volume dan kompleksitas penggunaan AI tumbuh.