Table des matières
Que se passe-t-il lorsque vous envoyez une requête IA ?
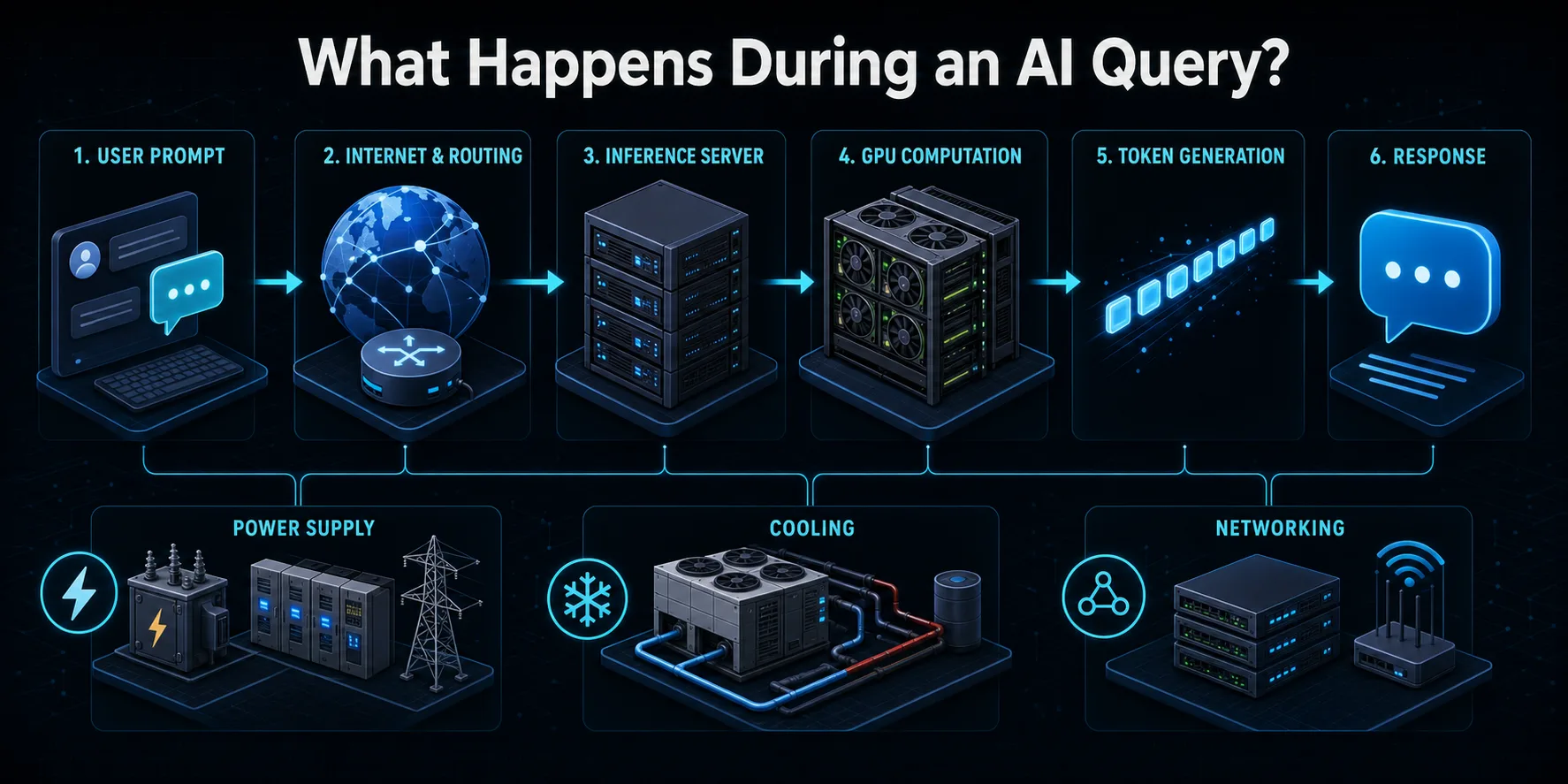
Lorsque vous soumettez une requête à un service d'IA, elle voyage d'abord sur Internet jusqu'à l'infrastructure du fournisseur. Les systèmes de routage l'authentifient, appliquent des contrôles de sécurité et d'utilisation et la dirigent vers un serveur d'inférence disponible. Un équilibreur de charge peut choisir entre plusieurs machines afin de répartir le trafic des utilisateurs sans surcharger une partie du système.
Le serveur convertit le prompt en tokens, des unités numériques traitées par un modèle linguistique. Ces tokens et tout contexte de conversation précédent sont chargés dans la mémoire de l'accélérateur. Les GPU ou autres puces d'intelligence artificielle effectuent alors des couches de calculs matriciels sur les paramètres du modèle afin de prédire le token suivant. Le processus se répète plusieurs fois jusqu'à ce que la réponse soit complète ou atteigne une limite configurée.
La sortie générée est décodée en texte et renvoyée à l'utilisateur, souvent alors que les jetons ultérieurs sont encore en cours de calcul. Autour de cette interaction visible, les équipements de stockage, de mise en réseau, de surveillance, de conversion d'énergie et de refroidissement restent actifs. Une requête consomme donc plus que l'électricité mesurée au seul niveau du GPU, même si l'accélérateur effectue généralement la plupart des calculs intensifs.
Pourquoi les requêtes IA consomment-elles de l'électricité ?
L'inférence en IA est un calcul actif plutôt qu'une simple extraction d'une base de données. Un grand modèle doit évaluer de nombreuses opérations numériques pour chaque jeton généré, en utilisant des paramètres qui peuvent occuper des dizaines ou des centaines de gigaoctets de mémoire. Le déplacement de ces paramètres et des valeurs intermédiaires entre la mémoire à large bande et les cœurs de processeur consomme de l'électricité en même temps que les calculs eux-mêmes.
La quantité de travail augmente en fonction du modèle, du prompt et de la sortie demandée. Les longs historiques de conversation nécessitent le traitement d'un plus grand nombre de contextes, tandis que les longues réponses font tourner les accélérateurs pour davantage d'étapes de génération. Les systèmes d'images, d'audio et de vidéo peuvent nécessiter des pipelines de traitement différents ou des opérations de raffinement répétées, de sorte qu'une requête IA n'est pas une unité de travail standardisée.
Les frais généraux du datacenter sont également importants. Les serveurs ont besoin d'une alimentation électrique, d'un réseau, de stockage et de refroidissement, et une partie de l'électricité est perdue lors de la conversion et de la distribution de l'énergie. Les opérateurs expriment souvent ces frais généraux par le biais de l'efficacité de l'utilisation de l'énergie, ou PUE. Une installation efficace rapproche l'énergie totale de l'énergie utilisée par l'équipement informatique, tandis qu'une installation moins efficace nécessite plus d'électricité de soutien pour la même charge de travail d'inférence.
Quelle est la consommation d'électricité d'une requête IA ?
Il n'existe pas de chiffre universel sur la consommation d'électricité d'une requête IA. Les estimations publiques pour les interactions textuelles vont généralement de quelques fractions de wattheures à plusieurs wattheures, mais cette fourchette doit être considérée comme un ordre de grandeur plutôt que comme une conversion fixe. Une requête courte traitée par un modèle optimisé et bien utilisé peut consommer beaucoup moins d'énergie qu'une réponse longue d'un modèle plus grand fonctionnant sur un matériel sous-utilisé.
Le wattheure mesure l'énergie et non la puissance instantanée. Par exemple, un serveur qui consomme beaucoup d'énergie pendant une fraction de seconde peut utiliser moins d'énergie totale qu'un système de moindre puissance fonctionnant pendant beaucoup plus longtemps. Une estimation crédible par requête nécessite donc à la fois la consommation d'énergie de l'équipement et la durée et la part de cet équipement attribuable à la requête.
Les comparaisons avec les recherches sur le web, les ampoules électriques ou le chargement des téléphones peuvent faciliter la visualisation de l'échelle, mais elles cachent souvent des hypothèses importantes. La question pertinente n'est pas de savoir si chaque requête consomme une quantité spécifique. Il s'agit de savoir quel modèle a traité la requête, combien de tokens et de modalités ont été traités, avec quelle efficacité les requêtes ont été regroupées et quelle quantité d'énergie d'infrastructure a été incluse dans le calcul.
Pourquoi les estimations varient-elles ?
Les fournisseurs d'IA publient rarement des mesures complètes qui relient les requêtes individuelles à la taille du modèle, à l'utilisation du matériel, au nombre de tokens et aux frais généraux de l'installation. Les chercheurs doivent donc combiner les spécifications matérielles divulguées, les résultats des benchmarks, les temps de service estimés et les hypothèses d'efficacité du datacenter. Des choix différents à chaque étape peuvent produire des réponses sensiblement différentes.
La mise en lots est l'une des principales sources de variation. Un serveur d'inférence peut traiter plusieurs utilisateurs ensemble, en partageant le chargement du modèle et le calcul au sein d'un lot. Une utilisation élevée peut réduire l'énergie moyenne attribuée à chaque requête, tandis que la capacité inactive, les exigences de latence ou les pics de trafic peuvent laisser du matériel coûteux partiellement utilisé. Des accélérateurs plus récents peuvent également effectuer la même charge de travail plus rapidement ou avec moins de joules.
Le périmètre de l'estimation modifie également le résultat. Certains calculs ne prennent en compte que l'énergie de l'accélérateur ; d'autres incluent les unités centrales de traitement, la mémoire, la mise en réseau, le refroidissement et les pertes de puissance. La plupart des chiffres par requête excluent l'énergie utilisée précédemment pour fabriquer le matériel et former le modèle. Les estimations sont plus utiles lorsque les limites du système et les hypothèses sont explicites, et non lorsqu'un seul chiffre est présenté comme universel.
Requêtes IA et entraînement de l'IA
L'entraînement permet de créer ou de mettre à jour un modèle en traitant de manière répétée de grands jeux de données et en ajustant ses paramètres. Un grand cycle d'entraînement peut occuper des milliers d'accélérateurs pendant des jours ou des semaines, ce qui en fait un événement de calcul concentré et très visible. Une fois l'entraînement terminé, le modèle résultant peut être déployé sur de nombreux serveurs d'inférence pour répondre aux requêtes des utilisateurs.
L'inférence est généralement beaucoup plus petite pour une interaction, mais elle est continue. Les systèmes de production doivent répondre à toute heure, garder une capacité suffisante pour les pics et traiter des utilisateurs dans plusieurs régions. Le profil énergétique est donc réparti entre de nombreux datacenters et répété à chaque fois que du texte, des images, du son ou d'autres sorties sont générés.
Aucune charge de travail ne doit automatiquement être considérée comme dominant la consommation d'électricité d'un modèle pendant toute sa durée de vie. L'entraînement peut être l'événement unique le plus important, en particulier pour les systèmes d'avant-garde, tandis que l'inférence peut éventuellement le dépasser lorsqu'un service gère un trafic énorme pendant des mois ou des années. L'équilibre dépend de la fréquence de recyclage des modèles, de l'étendue de leur déploiement et de l'intensité de leur utilisation.
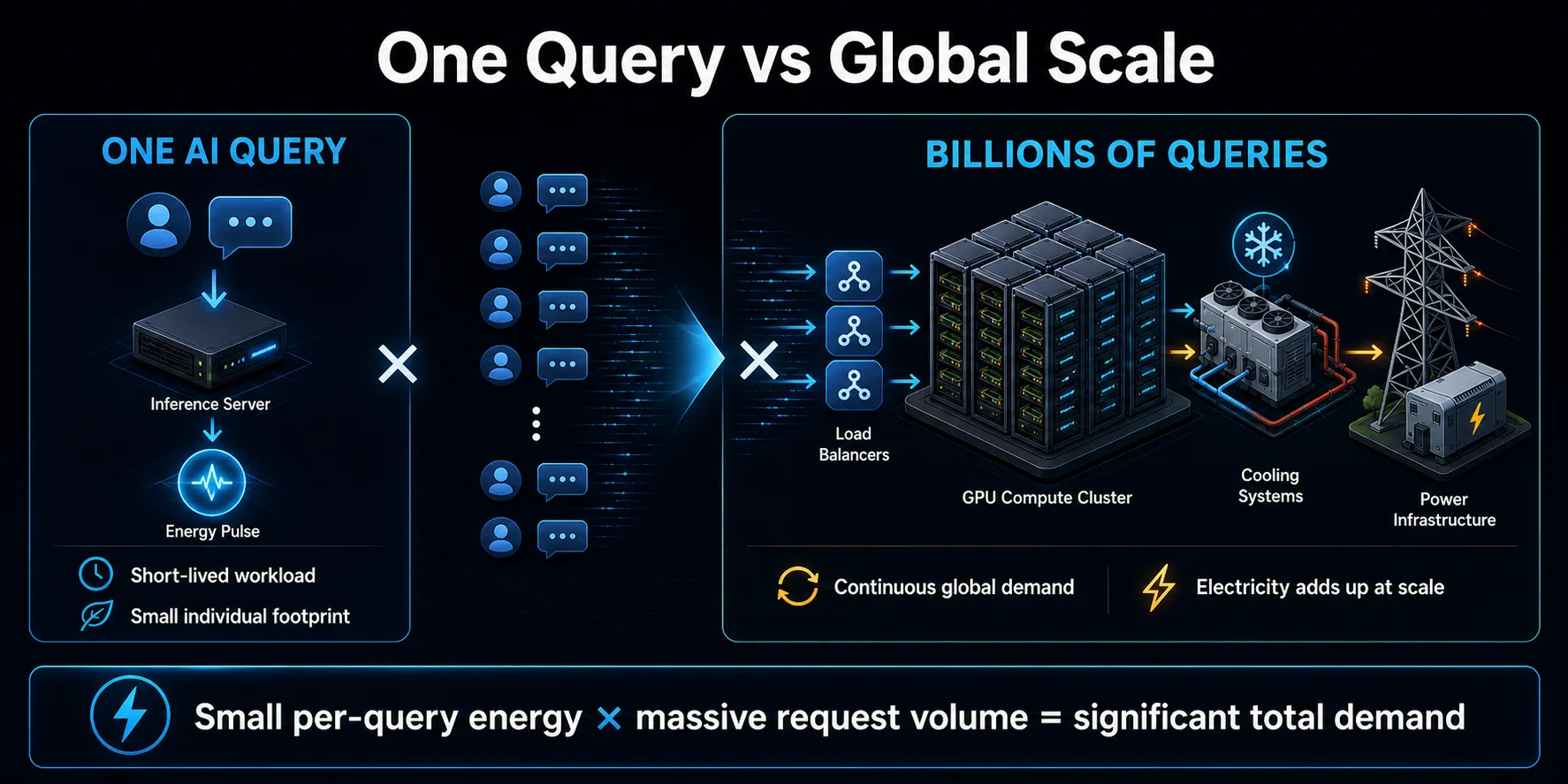
Des milliards de requêtes s'additionnent
L'importance environnementale des requêtes IA provient principalement de la multiplication. Une seule requête courte peut représenter une petite quantité d'énergie, mais les assistants grand public, les fonctions de recherche, les outils de codage et les applications commerciales peuvent générer un grand nombre de requêtes. Répétée continuellement, l'énergie modeste par requête devient une charge substantielle pour les datacenters.
La demande ne se limite pas aux messages visibles du chatbot. Les applications peuvent faire appel à plusieurs modèles pour répondre à une action de l'utilisateur, utiliser des modèles distincts pour la modération ou l'extraction, réessayer les requêtes qui ont échoué et générer des résumés ou des recommandations en arrière-plan. Les systèmes agentiques peuvent étendre ce modèle en appelant des modèles et des outils logiciels de manière répétée pendant l'exécution d'une tâche unique.
L'échelle influe également sur la planification de l'infrastructure. Les fournisseurs développent leur capacité en fonction de la croissance et des pics de trafic, ce qui peut augmenter la demande en électricité avant que chaque serveur ne soit pleinement utilisé. L'impact total dépend à la fois de l'efficacité par requête et de la vitesse à laquelle l'utilisation augmente. Si la demande augmente plus vite que l'efficacité, la consommation globale d'électricité peut continuer à augmenter même si chaque interaction individuelle devient moins gourmande en énergie.
Les requêtes d'IA deviendront-elles plus efficaces ?
L'inférence de l'IA est susceptible de devenir plus économe en énergie au niveau d'une tâche comparable. Les nouveaux accélérateurs fournissent plus de calculs par unité d'électricité, tandis que la quantification, l'élagage, le décodage spéculatif et les architectures de modèles améliorées peuvent réduire les opérations nécessaires pour obtenir des résultats utiles. Une meilleure planification et une mise en lots peuvent également améliorer l'utilisation du matériel sans modifier l'expérience de l'utilisateur.
Les modèles spécialisés plus petits offrent une autre voie. Un service n'a pas toujours besoin de son plus grand modèle pour la classification, l'extraction ou les questions de routine. L'acheminement des tâches simples vers des modèles compacts, la limitation du contexte inutile et la mise en cache des résultats réutilisables peuvent réduire à la fois la latence et la consommation d'électricité. Les datacenters peuvent encore améliorer l'efficacité totale grâce à l'alimentation électrique, au refroidissement et au placement de la charge de travail.
L'efficacité ne garantit pas une consommation globale plus faible. Une IA plus rapide et moins chère peut encourager davantage d'applications, des interactions plus longues et de nouvelles fonctionnalités à forte intensité de calcul, un effet parfois décrit comme une demande de rebond. L'empreinte électrique future des requêtes d'IA dépendra donc de deux tendances concurrentes : la rapidité avec laquelle chaque unité de travail utile devient plus efficace et la rapidité avec laquelle le volume total et la complexité de l'utilisation de l'IA augmentent.