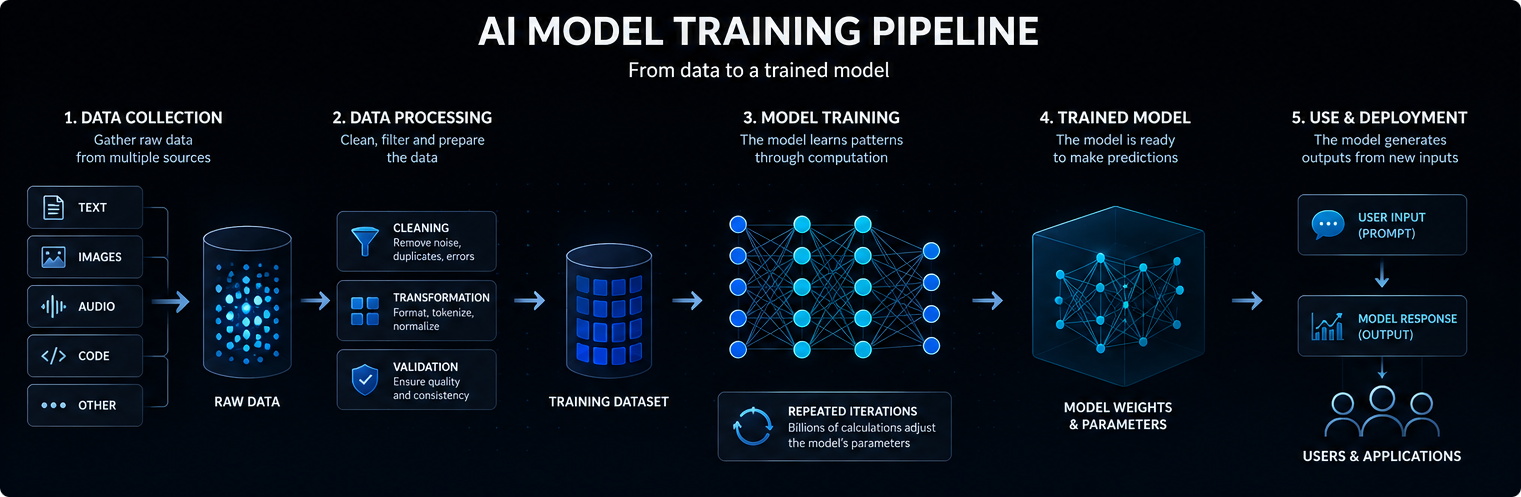
Zawartość
Trenowanie rozpoczyna się od danych
Trenowanie modelu AI rozpoczyna się od danych. W zależności od modelu, dane te mogą obejmować tekst, obrazy, dźwięk, kod, wideo, pomiary naukowe lub ustrukturyzowane rekordy.
Duże modele językowe są szkolone na ogromnych zbiorach tekstu i kodu, dzięki czemu mogą uczyć się statystycznych relacji między słowami, pojęciami, instrukcjami i wynikami.
Jakość, różnorodność i struktura danych treningowych silnie wpływają na to, czego model może się nauczyć, jak dobrze uogólnia i gdzie pojawiają się jego ograniczenia.
Sieci neuronowe i parametry
Współczesne modele sztucznej inteligencji opierają się zazwyczaj na sieciach neuronowych. Sieci te składają się z wielu warstw operacji matematycznych, które przekształcają dane wejściowe w prognozy, klasyfikacje lub wygenerowane wyniki.
Wewnętrzne wartości dostosowane podczas trenowania nazywane są parametrami. Duże modele AI mogą zawierać miliardy, a nawet biliony parametrów.
Uczenie to proces dostosowywania tych parametrów w taki sposób, aby model lepiej przewidywał, klasyfikował, generował lub dokonywał wnioskowania na podstawie nowych danych wejściowych. Mówiąc prościej, model sztucznej inteligencji działa poprzez przekształcanie danych wejściowych w sygnały wewnętrzne, przepuszczanie tych sygnałów przez wyuczone parametry oraz generowanie wyniku, który z największym prawdopodobieństwem okaże się użyteczny.
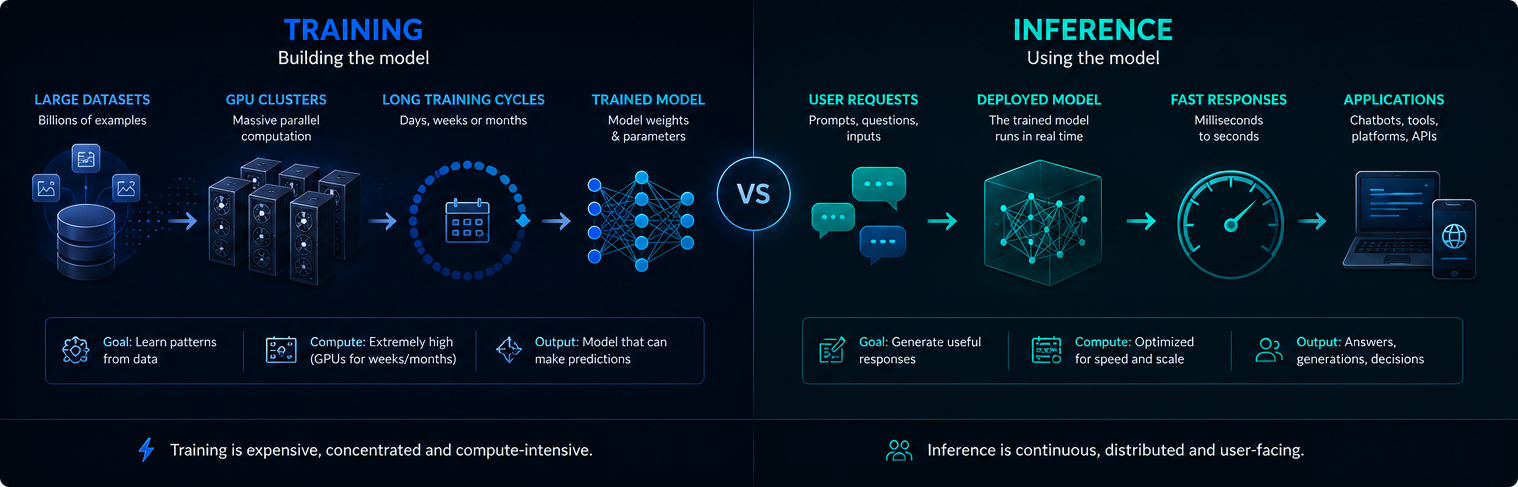
Jak faktycznie przebiega nauka
Podczas trenowania model przetwarza przykłady i tworzy prognozy. Prognozy te są porównywane z oczekiwanymi wynikami lub celami trenowania.
Gdy model popełnia błędy, algorytmy optymalizacji nieznacznie dostosowują jego parametry. Proces ten jest powtarzany wielokrotnie w ogromnych zbiorach danych.
Z biegiem czasu model uczy się wzorców statystycznych, które pozwalają mu generować bardziej użyteczne wyniki, gdy później otrzyma nowe podpowiedzi lub dane wejściowe.
Dlaczego trening wymaga tak wielu obliczeń
Trenowanie dużych modeli sztucznej inteligencji wymaga ogromnych obliczeń, ponieważ miliardy parametrów muszą być wielokrotnie aktualizowane w ogromnych ilościach danych.
Proces ten jest zazwyczaj rozproszony na duże klastry GPU w wyspecjalizowanych centrach danych. Układy GPU wykonują równoległe operacje matematyczne znacznie szybciej niż konwencjonalne procesory.
Im większy model i zbiór danych, tym więcej mocy obliczeniowej, energii elektrycznej, chłodzenia i infrastruktury.
Jak długo trwa trenowanie AI?
Czas trwania trenowania jest bardzo różny. Małe modele mogą być trenowane w ciągu kilku minut lub godzin, podczas gdy modele frontier mogą wymagać tygodni lub miesięcy skoordynowanych obliczeń.
Czas treningu zależy od rozmiaru modelu, rozmiaru zbioru danych, dostępności sprzętu, technik optymalizacji i liczby równolegle wykorzystywanych procesorów graficznych.
Duże laboratoria AI inwestują znaczne środki w infrastrukturę, ponieważ szybsze cykle treningowe pozwalają im testować więcej pomysłów, szybciej ulepszać modele i szybciej wdrażać nowe systemy.
Trening a wnioskowanie
Trening i wnioskowanie to różne fazy infrastruktury AI. Trening tworzy lub aktualizuje model, podczas gdy wnioskowanie wykorzystuje wytrenowany model do odpowiadania na żądania użytkowników.
Trening jest zwykle skoncentrowany i niezwykle intensywny obliczeniowo. Wnioskowanie jest ciągłe, ponieważ wdrożone systemy sztucznej inteligencji mogą obsługiwać miliony podpowiedzi każdego dnia.
Obie fazy mają znaczenie dla zapotrzebowania na energię elektryczną, wykorzystania GPU i wpływu nowoczesnej sztucznej inteligencji na środowisko.
Przyszłość szkoleń AI
Trenowanie AI prawdopodobnie stanie się bardziej wydajne dzięki lepszemu sprzętowi, ulepszonym algorytmom, mniejszym wyspecjalizowanym modelom i bardziej zoptymalizowanym potokom danych.
Jednocześnie zapotrzebowanie na bardziej wydajne modele wciąż rośnie. Poprawa wydajności może obniżyć koszty poszczególnych obciążeń, podczas gdy całkowite zapotrzebowanie na moc obliczeniową wciąż rośnie.
Zrozumienie, w jaki sposób trenowane są modele AI, ma zasadnicze znaczenie dla oceny przyszłości infrastruktury AI, zużycia energii i postępu technologicznego.