Spis treści
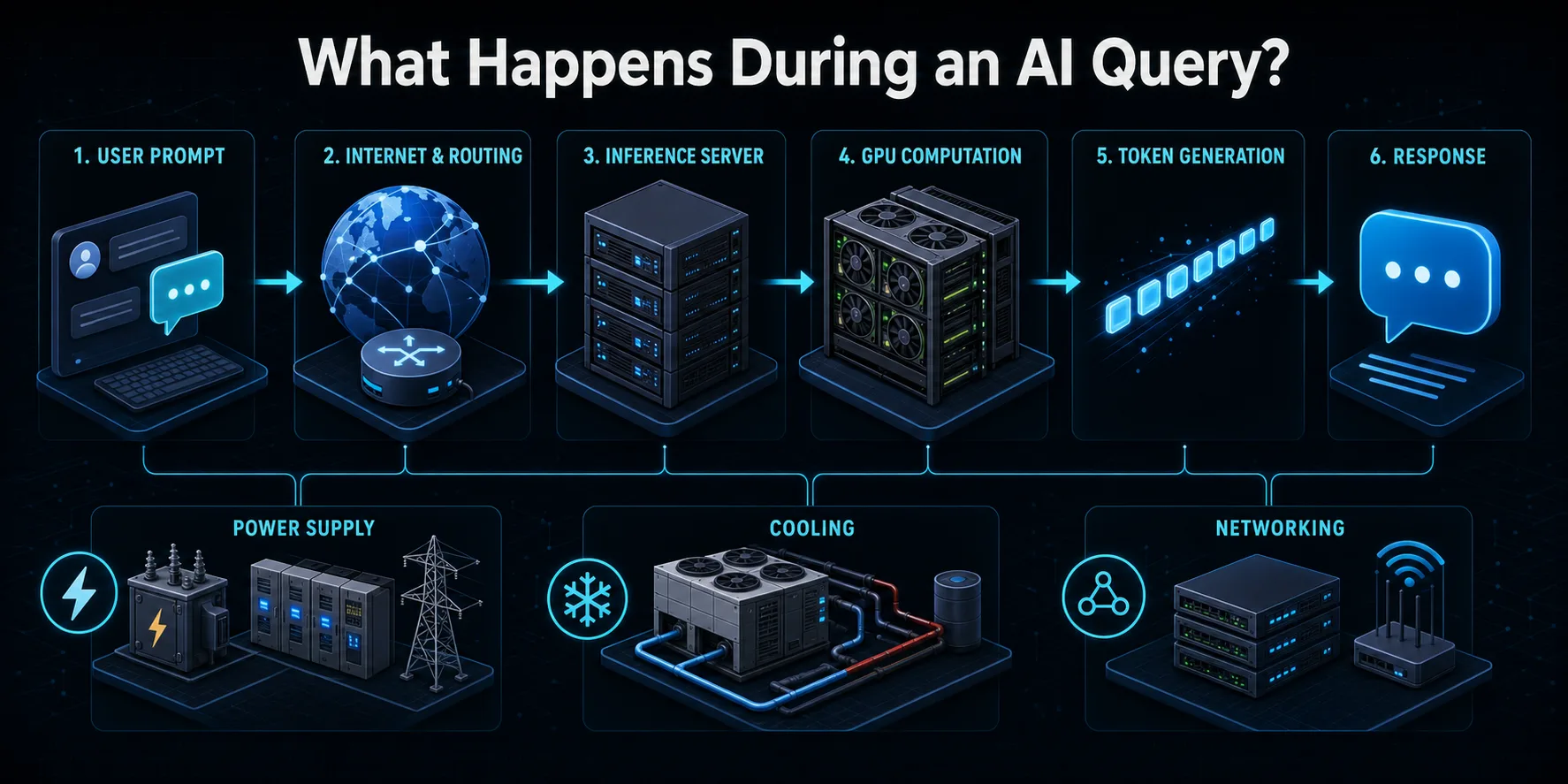
Co się dzieje po wysłaniu zapytania AI?
Po przesłaniu promptu do usługi AI, żądanie najpierw podróżuje przez Internet do infrastruktury dostawcy. Systemy routingu uwierzytelniają żądanie, stosują kontrole bezpieczeństwa i użytkowania oraz kierują je do dostępnego serwera wnioskowania. System równoważenia obciążenia może wybierać spośród wielu maszyn, tak aby ruch użytkowników był dystrybuowany bez przeciążania jednej części systemu.
Serwer konwertuje podpowiedź na tokeny, jednostki numeryczne przetwarzane przez model językowy. Te tokeny i wszelkie poprzednie konteksty konwersacji są ładowane do pamięci akceleratora. Układy GPU lub inne układy sztucznej inteligencji wykonują następnie warstwy obliczeń macierzowych na parametrach modelu, aby przewidzieć następny token. Proces ten powtarza się wiele razy, aż odpowiedź jest kompletna lub osiągnie skonfigurowany limit.
Wygenerowane dane wyjściowe są dekodowane na tekst i przesyłane strumieniowo z powrotem do użytkownika, często podczas gdy późniejsze tokeny są nadal obliczane. Wokół tej widocznej interakcji, pamięć masowa, sieć, monitorowanie, konwersja mocy i sprzęt chłodzący pozostają aktywne. Zapytanie zużywa zatem więcej energii elektrycznej niż zmierzono w samym GPU, mimo że akcelerator zwykle wykonuje większość intensywnych obliczeń.
Dlaczego zapytania AI zużywają energię elektryczną
Wnioskowanie sztucznej inteligencji jest raczej aktywnym procesem obliczeniowym niż prostym pobieraniem danych z bazy danych. Duży model musi ocenić wiele operacji numerycznych dla każdego wygenerowanego tokena, używając parametrów, które mogą zajmować dziesiątki lub setki gigabajtów pamięci. Przenoszenie tych parametrów i wartości pośrednich między pamięcią o wysokiej przepustowości a rdzeniami procesora zużywa energię elektryczną wraz z samymi obliczeniami.
Ilość pracy rośnie wraz z modelem, promptem i żądanym wynikiem. Długie historie rozmów wymagają więcej kontekstu do przetworzenia, podczas gdy długie odpowiedzi sprawiają, że akceleratory działają przez więcej kroków generowania. Systemy obrazów, audio i wideo mogą wymagać różnych potoków przetwarzania lub powtarzających się operacji udoskonalania, więc zapytanie AI nie jest jedną znormalizowaną jednostką pracy.
Koszty ogólne centrum danych również mają znaczenie. Serwery potrzebują zasilaczy, sieci, pamięci masowej i chłodzenia, a część energii elektrycznej jest tracona podczas konwersji i dystrybucji energii. Operatorzy często wyrażają ten narzut poprzez efektywność zużycia energii (PUE). Wydajny obiekt zbliża całkowitą energię do energii zużywanej przez sprzęt obliczeniowy, podczas gdy mniej wydajny obiekt wymaga więcej energii elektrycznej do obsługi tego samego obciążenia wnioskowania.
Ile energii elektrycznej zużywa zapytanie AI?
Nie ma uniwersalnej liczby energii elektrycznej dla zapytań AI. Publiczne szacunki dla interakcji tekstowych zwykle wahają się od ułamków watogodzin do kilku watogodzin, ale zakres ten należy traktować jako rząd wielkości, a nie stałą konwersję. Krótkie zapytanie obsługiwane przez zoptymalizowany, dobrze wykorzystany model może zużywać znacznie mniej energii niż długa odpowiedź z większego modelu działającego na niewykorzystanym sprzęcie.
Watogodzina mierzy energię, a nie moc chwilową. Na przykład serwer pobierający dużą moc przez ułamek sekundy może zużywać mniej energii niż system o niższej mocy działający znacznie dłużej. Wiarygodne oszacowanie na zapytanie wymaga zatem zarówno poboru mocy przez sprzęt, jak i czasu trwania i udziału tego sprzętu, który można przypisać żądaniu.
Porównania z wyszukiwaniem w sieci, żarówkami lub ładowaniem telefonu mogą ułatwić wizualizację skali, ale często ukrywają ważne założenia. Istotną kwestią nie jest to, czy każdy prompt zużywa jedną określoną kwotę. Chodzi o to, który model obsłużył żądanie, ile tokenów i modalności zostało przetworzonych, jak skutecznie żądania zostały pogrupowane i ile energii infrastruktury zostało uwzględnione w obliczeniach.
Dlaczego szacunki się różnią
Dostawcy sztucznej inteligencji rzadko publikują kompletne pomiary, które łączą poszczególne żądania z rozmiarem modelu, wykorzystaniem sprzętu, liczbą tokenów i kosztami ogólnymi obiektu. Badacze muszą zatem łączyć ujawnione specyfikacje sprzętowe, wyniki testów porównawczych, szacowane czasy obsługi i założenia dotyczące wydajności centrum danych. Różne wybory na każdym etapie mogą przynieść znacząco różne odpowiedzi.
Batching jest jednym z głównych źródeł zmienności. Serwer wnioskowania może przetwarzać kilku użytkowników razem, współdzieląc ładowanie modelu i obliczenia w całej partii. Wysokie wykorzystanie może zmniejszyć średnią energię przypisaną do każdego żądania, podczas gdy bezczynność, wymagania dotyczące opóźnień lub skoki ruchu mogą spowodować częściowe wykorzystanie drogiego sprzętu. Nowsze akceleratory mogą również wykonywać to samo obciążenie szybciej lub zużywając mniej dżuli.
Granica oszacowania również zmienia wynik. Niektóre obliczenia uwzględniają tylko energię akceleratora; inne obejmują procesory, pamięć, sieć, chłodzenie i straty mocy. Większość danych na zapytanie wyklucza wcześniejszą energię wykorzystywaną do produkcji sprzętu i trenowania modelu. Szacunki są najbardziej użyteczne, gdy ich granice systemowe i założenia są wyraźne, a nie gdy pojedyncza liczba jest przedstawiana jako uniwersalna.
Zapytania AI a trenowanie AI
Trening tworzy lub aktualizuje model poprzez wielokrotne przetwarzanie dużych zbiorów danych i dostosowywanie jego parametrów. Duża sesja treningowa może zajmować tysiące akceleratorów przez kilka dni lub tygodni, co czyni je skoncentrowanym i bardzo widocznym wydarzeniem obliczeniowym. Po zakończeniu trenowania wynikowy model można wdrożyć na wielu serwerach wnioskowania, aby odpowiedzieć na żądania użytkowników.
Wnioskowanie jest zwykle znacznie mniejsze dla jednej interakcji, ale ma charakter ciągły. Systemy produkcyjne muszą reagować o każdej porze, utrzymywać wystarczającą przepustowość dostępną dla szczytów i obsługiwać użytkowników w wielu regionach. Profil energetyczny jest zatem rozproszony w wielu centrach danych i powtarzany za każdym razem, gdy generowany jest tekst, obrazy, dźwięk lub inne dane wyjściowe.
Żadne z tych obciążeń nie powinno być automatycznie zakładane jako dominujące w całym okresie użytkowania modelu. Trening może być największym pojedynczym zdarzeniem, szczególnie w przypadku systemów granicznych, podczas gdy wnioskowanie może ostatecznie je przekroczyć, gdy usługa obsługuje ogromny ruch przez miesiące lub lata. Równowaga zależy od tego, jak często modele są ponownie trenowane, jak szeroko są wdrażane i jak intensywnie ludzie z nich korzystają.
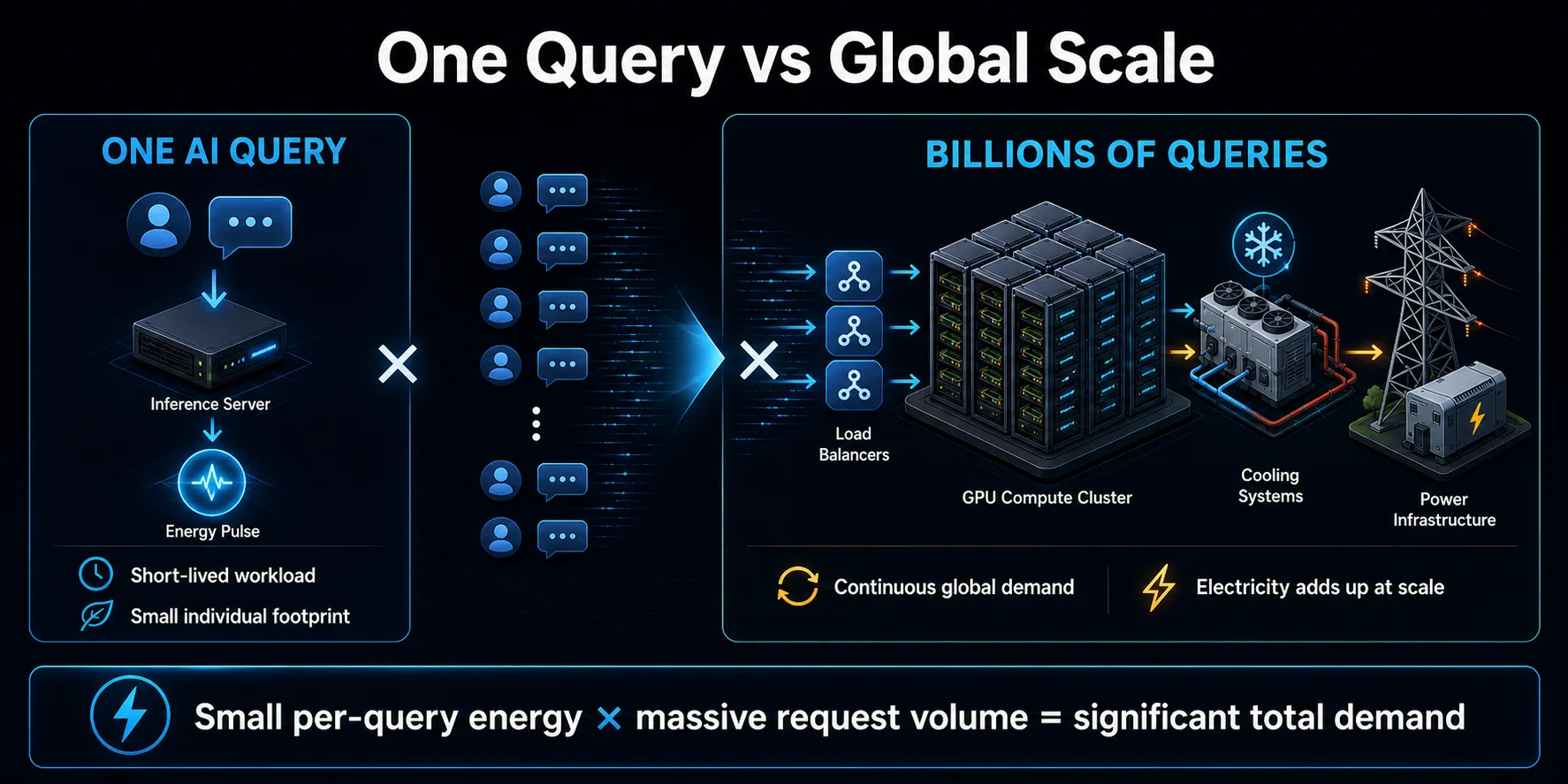
Miliardy zapytań sumują się
Znaczenie zapytań AI dla środowiska wynika przede wszystkim z ich zwielokrotnienia. Pojedynczy krótki prompt może stanowić niewielką ilość energii, ale asystenci konsumentów, funkcje wyszukiwania, narzędzia do kodowania i aplikacje biznesowe mogą generować ogromną liczbę zapytań. Powtarzane w sposób ciągły, skromne zużycie energii na zapytanie staje się znacznym obciążeniem dla centrum danych.
Zapotrzebowanie nie ogranicza się do widocznych komunikatów chatbota. Aplikacje mogą wykonywać kilka wywołań modeli, aby odpowiedzieć na jedną akcję użytkownika, używać oddzielnych modeli do moderowania lub wyszukiwania, ponawiać nieudane żądania i generować podsumowania lub rekomendacje w tle. Systemy agentowe mogą rozszerzyć ten wzorzec poprzez wielokrotne wywoływanie modeli i narzędzi programowych podczas wykonywania pojedynczego zadania.
Skala wpływa również na planowanie infrastruktury. Dostawcy budują pojemność na potrzeby wzrostu i szczytowego ruchu, co może zwiększyć zapotrzebowanie na energię elektryczną, zanim każdy serwer zostanie w pełni wykorzystany. Całkowity wpływ zależy zarówno od wydajności na zapytanie, jak i tempa, w jakim zwiększa się wykorzystanie. Jeśli popyt rośnie szybciej niż poprawia się wydajność, zagregowane zużycie energii elektrycznej może nadal rosnąć, nawet gdy każda indywidualna interakcja staje się mniej energochłonna.
Czy zapytania AI staną się bardziej wydajne?
Wnioskowanie sztucznej inteligencji prawdopodobnie stanie się bardziej energooszczędne na poziomie porównywalnego zadania. Nowe akceleratory zapewniają więcej obliczeń na jednostkę energii elektrycznej, podczas gdy kwantyzacja, przycinanie, dekodowanie spekulacyjne i ulepszone architektury modeli mogą zmniejszyć liczbę operacji potrzebnych do uzyskania użytecznych wyników. Lepsze planowanie i grupowanie może również zwiększyć wykorzystanie sprzętu bez zmiany doświadczenia użytkownika.
Mniejsze wyspecjalizowane modele oferują inną ścieżkę. Usługa nie zawsze potrzebuje największego modelu do klasyfikacji, ekstrakcji lub rutynowych pytań. Przekierowanie prostej pracy do kompaktowych modeli, ograniczenie niepotrzebnego kontekstu i buforowanie wyników wielokrotnego użytku może zmniejszyć zarówno opóźnienia, jak i zużycie energii elektrycznej. Centra danych mogą dodatkowo poprawić całkowitą wydajność poprzez dostarczanie energii, chłodzenie i rozmieszczanie obciążeń.
Wydajność nie gwarantuje niższego ogólnego zużycia. Szybsza i tańsza sztuczna inteligencja może zachęcać do większej liczby aplikacji, dłuższych interakcji i nowych funkcji wymagających dużej mocy obliczeniowej, co czasami określa się jako efekt odbicia popytu. Przyszły ślad energetyczny zapytań AI będzie zatem zależał od dwóch konkurujących ze sobą trendów: jak szybko każda jednostka użytecznej pracy stanie się bardziej wydajna oraz jak szybko wzrośnie całkowity wolumen i złożoność wykorzystania AI.