Tartalomjegyzék
A képzés adatokkal kezdődik
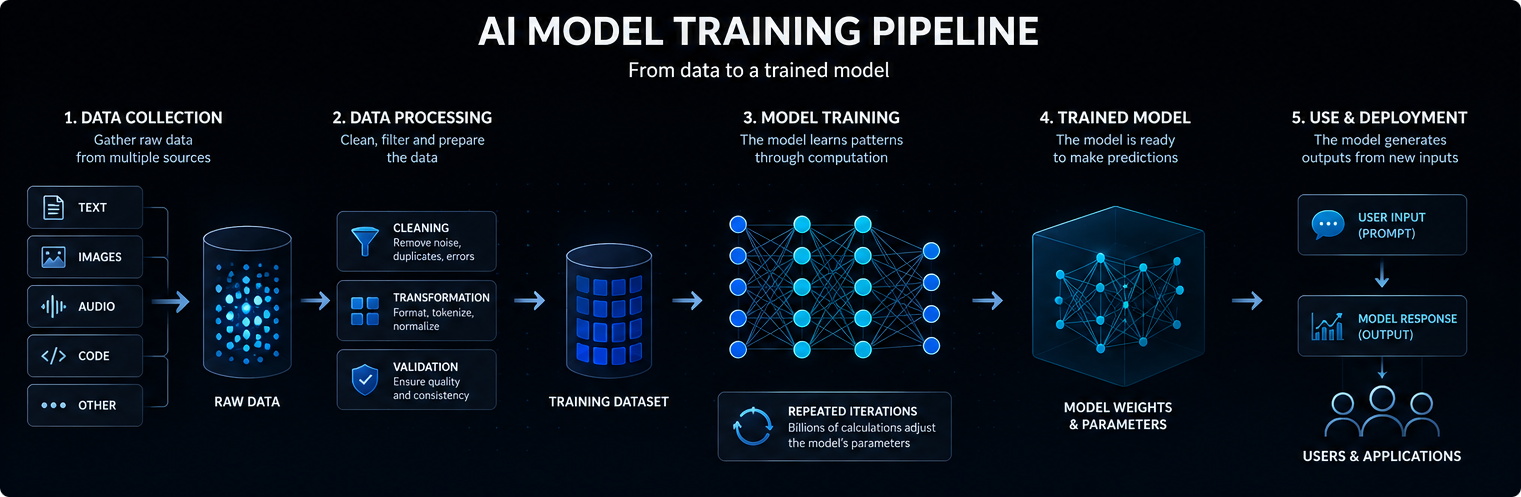
Egy mesterséges intelligencia modell képzése adatokkal kezdődik. A modelltől függően ezek az adatok lehetnek szövegek, képek, hangok, kódok, videók, tudományos mérések vagy strukturált feljegyzések.
A nagyméretű nyelvi modelleket hatalmas szöveg- és kódgyűjteményeken képzik ki, hogy statisztikai kapcsolatokat tanulhassanak a szavak, fogalmak, utasítások és kimenetek között.
A képzési adatok minősége, sokfélesége és szerkezete erősen befolyásolja, hogy a modell mit tud megtanulni, mennyire jól általánosít, és hol mutatkoznak a korlátai.
Neurális hálózatok és paraméterek
A modern mesterséges intelligencia-modellek általában neurális hálózatokon alapulnak. Ezek a hálózatok számos rétegből állnak, amelyek matematikai műveletek segítségével alakítják át a bemeneti adatokat előrejelzésekké, osztályozásokká vagy generált kimeneti adatokká.
A képzés során beállított belső értékeket paramétereknek nevezzük. A nagy mesterséges intelligencia modellek több milliárd vagy akár több billió paramétert is tartalmazhatnak.
A betanítás az a folyamat, amelynek során ezeket a paramétereket úgy állítják be, hogy a modell hatékonyabban tudjon új bemeneti adatokra vonatkozóan előrejelzéseket készíteni, osztályozni, generálni vagy következtetéseket levonni. Egyszerűen fogalmazva: egy mesterséges intelligencia-modell úgy működik, hogy a bemeneti adatokat belső jelekké alakítja át, ezeket a jeleket a megtanult paramétereken keresztül futtatja, és így a legvalószínűbb, hasznos kimenetet állítja elő.
Hogyan történik a tanulás valójában
A képzés során a modell feldolgozza a példákat és előrejelzéseket készít. Ezeket a jóslatokat összehasonlítjuk a várt kimenetekkel vagy a képzési célokkal.
Amikor a modell hibázik, az optimalizáló algoritmusok kissé módosítják a paramétereit. Ez a folyamat sokszor megismétlődik hatalmas adathalmazokon keresztül.
Idővel a modell olyan statisztikai mintákat tanul, amelyek lehetővé teszik, hogy hasznosabb kimeneteket produkáljon, amikor később új utasításokat vagy bemeneteket kap.
Miért igényel a képzés olyan sok számítást
A nagyméretű mesterséges intelligenciamodellek képzése hatalmas számításokat igényel, mivel több milliárd paramétert kell ismételten frissíteni hatalmas adatmennyiségeken keresztül.
Ez a folyamat jellemzően nagy GPU-klaszterekre oszlik szét a speciális adatközpontokban. A GPU-k a hagyományos processzoroknál jóval gyorsabban hajtják végre a párhuzamos matematikai műveleteket.
Minél nagyobb a modell és az adatkészlet, annál több számítógépre, áramra, hűtésre és infrastruktúrára van szükség.
Mennyi ideig tart a mesterséges intelligencia képzése?
A képzés időtartama széles skálán mozog. A kis modellek percek vagy órák alatt betaníthatók, míg a határmodellek hetek vagy hónapok összehangolt számítását igényelhetik.
A képzési idő függ a modell méretétől, az adathalmaz méretétől, a hardver rendelkezésre állásától, az optimalizálási technikáktól és a párhuzamosan használt GPU-k számától.
A nagy AI-laborok nagy összegeket fektetnek be az infrastruktúrába, mivel a gyorsabb képzési ciklusok lehetővé teszik számukra, hogy több ötletet teszteljenek, gyorsabban javítsák a modelleket és hamarabb telepítsenek új rendszereket.
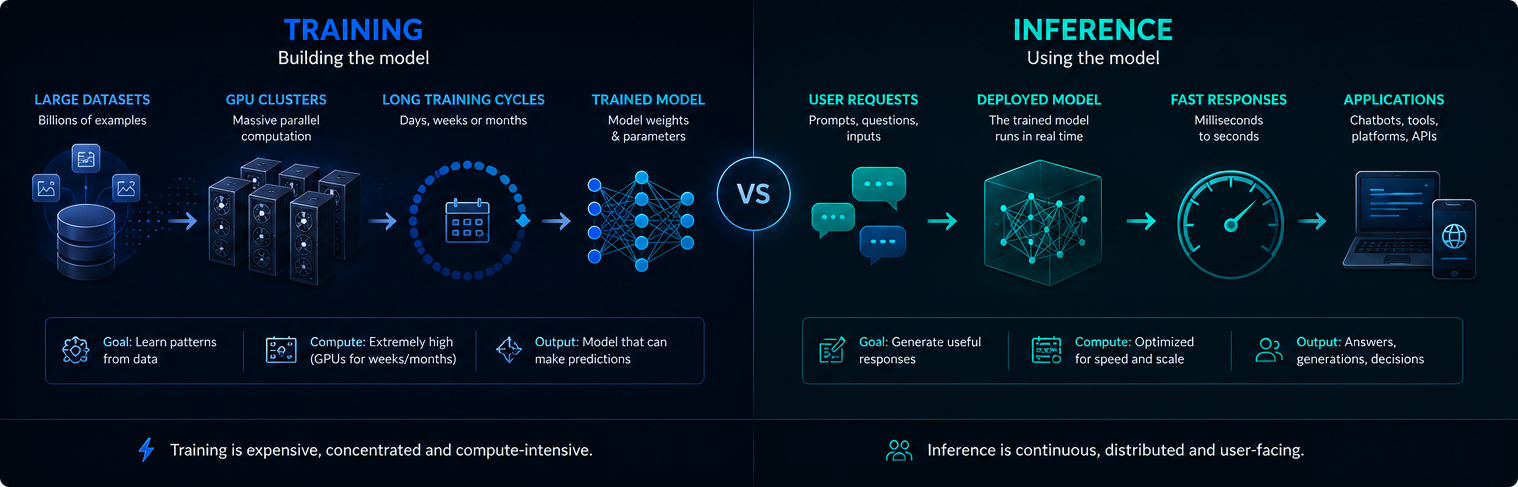
Képzés vs következtetés
A képzés és a következtetés az AI-infrastruktúra különböző fázisai. A képzés létrehozza vagy frissíti a modellt, míg a következtetés a képzett modellt használja a felhasználói kérések megválaszolására.
A képzés általában koncentrált és rendkívül számításigényes. A következtetés folyamatos, mivel a telepített mesterséges intelligencia rendszerek naponta akár több millió kérést is kiszolgálhatnak.
Mindkét fázis fontos az áramigény, a GPU-használat és a modern mesterséges intelligencia környezeti hatása szempontjából.
Az AI képzés jövője
A mesterséges intelligencia képzése valószínűleg hatékonyabbá válik a jobb hardverek, a továbbfejlesztett algoritmusok, a kisebb speciális modellek és az optimalizáltabb adatvezetékek révén.
Ugyanakkor a nagyobb teljesítményű modellek iránti kereslet folyamatosan növekszik. A hatékonyságnövelés csökkentheti az egyes munkaterhelések költségeit, miközben a teljes számítási igény még mindig növekszik.
A mesterséges intelligenciamodellek képzésének megértése alapvető fontosságú a mesterséges intelligencia infrastruktúrájának, az energiafelhasználásnak és a technológiai fejlődésnek az értékeléséhez.