Tartalomjegyzék
Mi történik, ha elküldesz egy mesterséges intelligencia-lekérdezést?
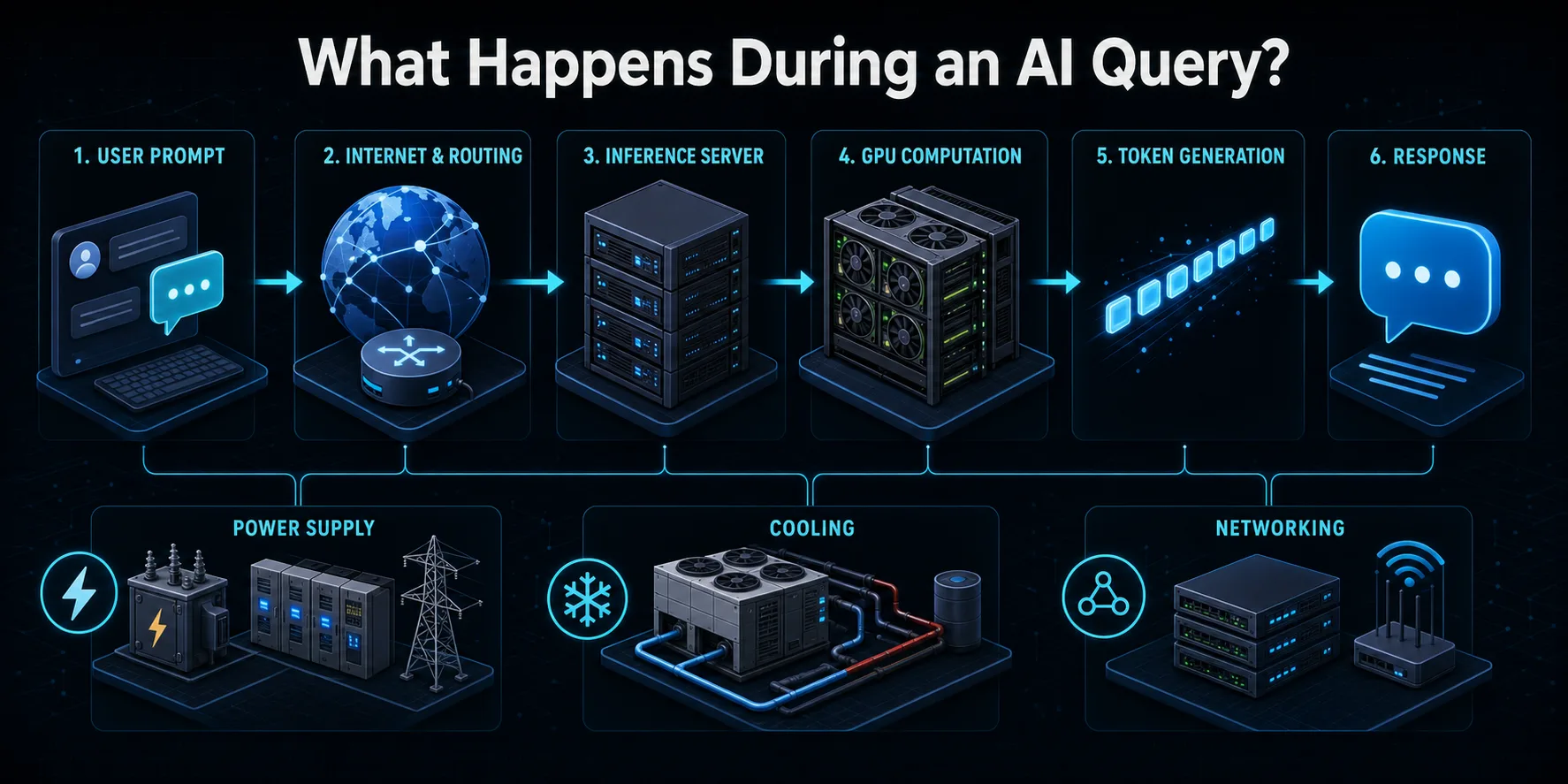
Amikor Ön kérést küld egy mesterséges intelligencia szolgáltatásnak, a kérés először az interneten keresztül eljut a szolgáltató infrastruktúrájához. Az útválasztó rendszerek hitelesítik a kérést, biztonsági és használati ellenőrzéseket alkalmaznak, és egy elérhető következtetés-kiszolgálóhoz irányítják azt. A terheléselosztó sok gép között választhat, hogy a felhasználói forgalom úgy oszoljon el, hogy ne terhelje túl a rendszer egy részét.
A kiszolgáló a felkérést tokenekké alakítja át, amelyek a nyelvi modell által feldolgozott numerikus egységek. Ezek a tokenek és minden korábbi beszélgetés-kontextus betöltődnek a gyorsító memóriájába. A GPU-k vagy más mesterséges intelligenciachipek ezután a modell paraméterein keresztül mátrixszámításokat végeznek a következő token előrejelzése érdekében. A folyamat sokszor megismétlődik, amíg a válasz teljes nem lesz, vagy el nem éri a beállított határt.
A generált kimenetet szöveggé dekódolják és visszaküldik a felhasználónak, gyakran még a későbbi tokenek kiszámítása közben. E látható interakció körül a tároló, a hálózati, a felügyeleti, az energiaátalakító és a hűtőberendezések aktívak maradnak. Egy lekérdezés tehát többet fogyaszt, mint a GPU-n egyedül mért villamos energia, még akkor is, ha a gyorsító általában az intenzív számítások nagy részét a gyorsító végzi.
Miért fogyasztanak áramot az AI-lekérdezések
A mesterséges intelligencia következtetés aktív számítás, nem pedig egyszerű visszakeresés egy adatbázisból. Egy nagy modellnek számos numerikus műveletet kell kiértékelnie minden egyes generált tokenre, olyan paramétereket használva, amelyek több tíz vagy több száz gigabájt memóriát foglalhatnak el. Ezeknek a paramétereknek és a közbenső értékeknek a nagy sávszélességű memória és a processzormagok közötti mozgatása magukkal a számításokkal együtt áramot is fogyaszt.
A munka mennyisége a modellel, a kéréssel és a kért kimenettel együtt nő. A hosszú beszélgetéstörténetek több kontextust igényelnek a feldolgozáshoz, míg a hosszú válaszok több generálási lépésben tartják a gyorsítókat. A kép-, hang- és videorendszerek különböző feldolgozási csővezetékeket vagy ismételt finomítási műveleteket igényelhetnek, így egy mesterséges intelligencia-lekérdezés nem egy egységes munkaegység.
Az adatközpontok általános költségei is számítanak. A szervereknek tápegységekre, hálózatra, tárolásra és hűtésre van szükségük, és az áramátalakítás és -elosztás során némi villamos energia is elvész. Az üzemeltetők ezt a rezsiköltséget gyakran az energiafelhasználás hatékonyságával (PUE) fejezik ki. Egy hatékony létesítmény a teljes energiát közelebb hozza a számítástechnikai berendezések által felhasznált energiához, míg egy kevésbé hatékony létesítmény több támogató áramot igényel ugyanahhoz a következtetési munkaterheléshez.
Mennyi áramot fogyaszt egy mesterséges intelligencia lekérdezés?
Egy mesterséges intelligencia-lekérdezéshez nem létezik univerzális villamosenergia-szám. A szöveges interakciókra vonatkozó nyilvános becslések általában egy wattóra töredékétől több wattóráig terjednek, de a tartományt inkább nagyságrendként kell kezelni, mint fix átváltásként. Egy optimalizált, jól kihasznált modell által kezelt rövid kérés sokkal kevesebb energiát használhat, mint egy alulhasznosított hardveren futó nagyobb modell hosszú válasza.
A wattóra az energiát méri, nem a pillanatnyi teljesítményt. Például egy kiszolgáló, amely a másodperc töredékéig nagy teljesítményt vesz fel, kevesebb teljes energiát használhat, mint egy sokkal hosszabb ideig működő, kisebb teljesítményű rendszer. A hiteles lekérdezésenkénti becsléshez ezért szükség van mind a berendezés energiafelvételére, mind pedig a berendezés időtartamára és a lekérdezésnek tulajdonítható részarányára.
A webes keresésekkel, villanykörtékkel vagy telefonok töltésével való összehasonlítás megkönnyítheti a skála szemléltetését, de gyakran fontos feltételezéseket rejt el. A lényeges kérdés nem az, hogy minden felszólítás egy bizonyos mennyiséget fogyaszt-e. Hanem az, hogy melyik modell szolgálta ki a kérést, hány tokent és modalitást dolgoztak fel, milyen hatékonyan csoportosították a kéréseket, és mennyi infrastrukturális energiát vontak be a számításba.
Miért változnak a becslések
A mesterséges intelligencia szolgáltatók ritkán tesznek közzé olyan teljes körű méréseket, amelyek összekapcsolják az egyes kéréseket a modell méretével, a hardver kihasználtságával, a tokenek számával és a létesítmény általános költségeivel. A kutatóknak ezért kombinálniuk kell a nyilvánosságra hozott hardverspecifikációkat, a benchmark-eredményeket, a becsült kiszolgálási időket és az adatközpont hatékonysági feltételezéseit. A különböző választások bármelyik lépésnél lényegesen eltérő válaszokat adhatnak.
Az eltérések egyik fő forrása a kötegelés. Egy következtetési kiszolgáló több felhasználót is feldolgozhat együtt, megosztva a modell betöltését és a számításokat egy kötegben. A magas kihasználtság csökkentheti az egyes kérésekhez rendelt átlagos energiát, míg a kihasználatlan kapacitás, a késleltetési követelmények vagy a forgalmi csúcsok miatt a drága hardver részben kihasználatlan maradhat. Az újabb gyorsítók ugyanazt a munkaterhelést gyorsabban vagy kevesebb joule-val is elvégezhetik.
A becslés határa is megváltoztatja az eredményt. Egyes számítások csak a gyorsító energiáját veszik figyelembe, mások a CPU-kat, a memóriát, a hálózatot, a hűtést és az energiaveszteségeket is. A legtöbb lekérdezésenkénti számadat nem tartalmazza a hardver gyártásához és a modell betanításához felhasznált korábbi energiát. A becslések akkor a leghasznosabbak, ha a rendszerhatárok és a feltételezések egyértelműek, nem pedig akkor, ha egyetlen számot mutatnak be univerzálisnak.
AI lekérdezések kontra AI képzés
A képzés nagy adathalmazok ismételt feldolgozásával és paramétereinek beállításával hoz létre vagy frissít egy modellt. Egy nagyobb tréningfutás napokig vagy hetekig több ezer gyorsítót foglalhat le, ami koncentrált és jól látható számítástechnikai eseményt jelent. Ha a képzés befejeződött, az eredményül kapott modell számos következtetési kiszolgálóra telepíthető a felhasználói kérések megválaszolására.
A következtetés általában sokkal kisebb egy kölcsönhatás esetén, de folyamatos. A termelési rendszereknek minden órában reagálniuk kell, elegendő kapacitást kell fenntartaniuk a csúcsidőszakokra, és több régióban kell kiszolgálniuk a felhasználókat. Az energiaprofil ezért számos adatközpontban oszlik meg, és minden egyes szöveg, kép, hang vagy más kimenet létrehozásakor megismétlődik.
Egyik munkaterhelésről sem szabad automatikusan azt feltételezni, hogy a modell teljes élettartamra vonatkozó villamosenergia-felhasználása dominál. A képzés lehet a legnagyobb egyszeri esemény, különösen a határterületi rendszerek esetében, míg a következtetés végül meghaladhatja azt, ha egy szolgáltatás hónapokon vagy éveken keresztül hatalmas forgalmat bonyolít le. Az egyensúly attól függ, hogy a modelleket milyen gyakran képzik újra, milyen széles körben alkalmazzák őket, és milyen intenzíven használják őket az emberek.
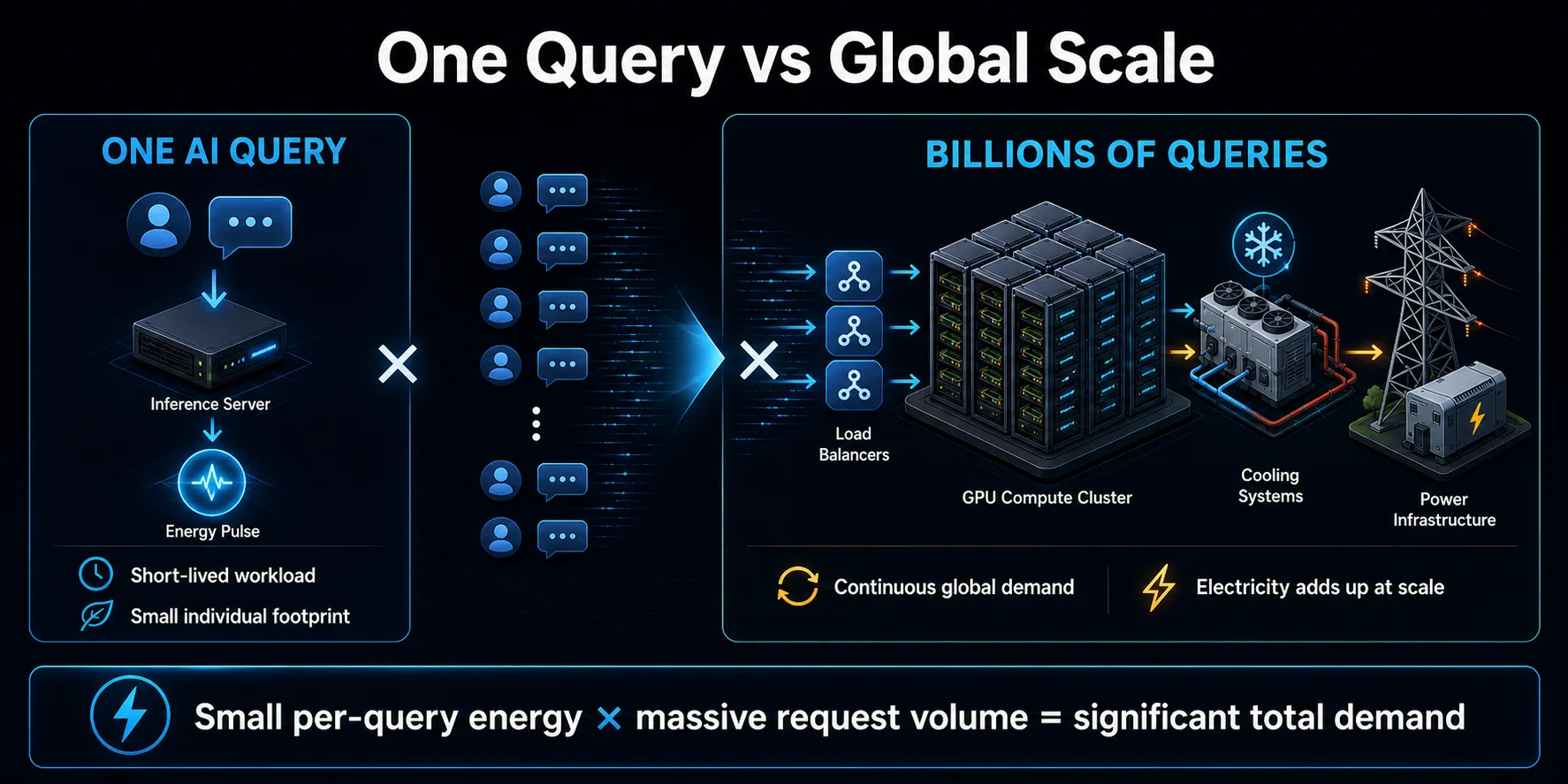
Több milliárd lekérdezés adódik össze
A mesterséges intelligenciakérdések környezeti jelentősége elsősorban a szaporodásból ered. Egyetlen rövid kérés kis mennyiségű energiát jelenthet, ugyanakkor a fogyasztói asszisztensek, keresőfunkciók, kódolási eszközök és üzleti alkalmazások hatalmas mennyiségű kérést generálhatnak. Folyamatosan ismételve a szerény lekérdezésenkénti energia jelentős adatközponti terheléssé válik.
A kereslet nem korlátozódik a látható chatbot-üzenetekre. Az alkalmazások egy felhasználói művelet megválaszolásához több modellhívást is végezhetnek, külön modelleket használhatnak a moderáláshoz vagy a visszakereséshez, újrapróbálhatják a sikertelen kéréseket, és háttér-összefoglalókat vagy ajánlásokat generálhatnak. Az ügynöki rendszerek kibővíthetik ezt a mintát azzal, hogy egyetlen feladat elvégzése közben többször hívnak meg modelleket és szoftvereszközöket.
A nagyságrend az infrastruktúra tervezését is befolyásolja. A szolgáltatók a növekedésre és a csúcsforgalomra építik ki a kapacitást, ami növelheti az áramigényt, mielőtt minden szerver teljes mértékben kihasználásra kerülne. A teljes hatás a lekérdezésenkénti hatékonyságtól és a használat bővülésének ütemétől is függ. Ha a kereslet gyorsabban nő, mint ahogy a hatékonyság javul, az összesített villamosenergia-fogyasztás tovább nőhet, még akkor is, ha az egyes interakciók kevésbé energiaigényesek.
Hatékonyabbak lesznek az AI-lekérdezések?
A mesterséges intelligencia következtetés valószínűleg energiatakarékosabb lesz egy hasonló feladat szintjén. Az új gyorsítók több számítást biztosítanak egységnyi villamos energiára vetítve, míg a kvantálás, a metszés, a spekulatív dekódolás és a továbbfejlesztett modellarchitektúrák csökkenthetik a hasznos kimenethez szükséges műveleteket. A jobb ütemezés és kötegelés szintén növelheti a hardver kihasználtságát anélkül, hogy a felhasználói élmény megváltozna.
A kisebb, speciális modellek egy másik utat kínálnak. Egy szolgáltatásnak nem mindig van szüksége a legnagyobb modelljére az osztályozáshoz, a kivonatoláshoz vagy a rutinszerű kérdésekhez. Az egyszerű munkák kompakt modellekbe való átirányítása, a felesleges kontextus korlátozása és az újrafelhasználható eredmények gyorsítótárazása csökkentheti mind a késleltetést, mind az áramfelhasználást. Az adatközpontok tovább javíthatják a teljes hatékonyságot az energiaellátás, a hűtés és a munkaterhelés elhelyezése révén.
A hatékonyság nem garantálja az alacsonyabb összfogyasztást. A gyorsabb és olcsóbb mesterséges intelligencia több alkalmazást, hosszabb interakciókat és új, számításigényes funkciókat ösztönözhet, amit néha visszapattanó keresletnek neveznek. A mesterséges intelligenciával kapcsolatos lekérdezések jövőbeni villamosenergia-lábnyoma ezért két egymással versengő tendenciától függ: attól, hogy a hasznos munka egyes egységei milyen gyorsan válnak hatékonyabbá, és attól, hogy a mesterséges intelligencia használatának teljes volumene és összetettsége milyen gyorsan növekszik.