Innehåll
Utbildningen börjar med data
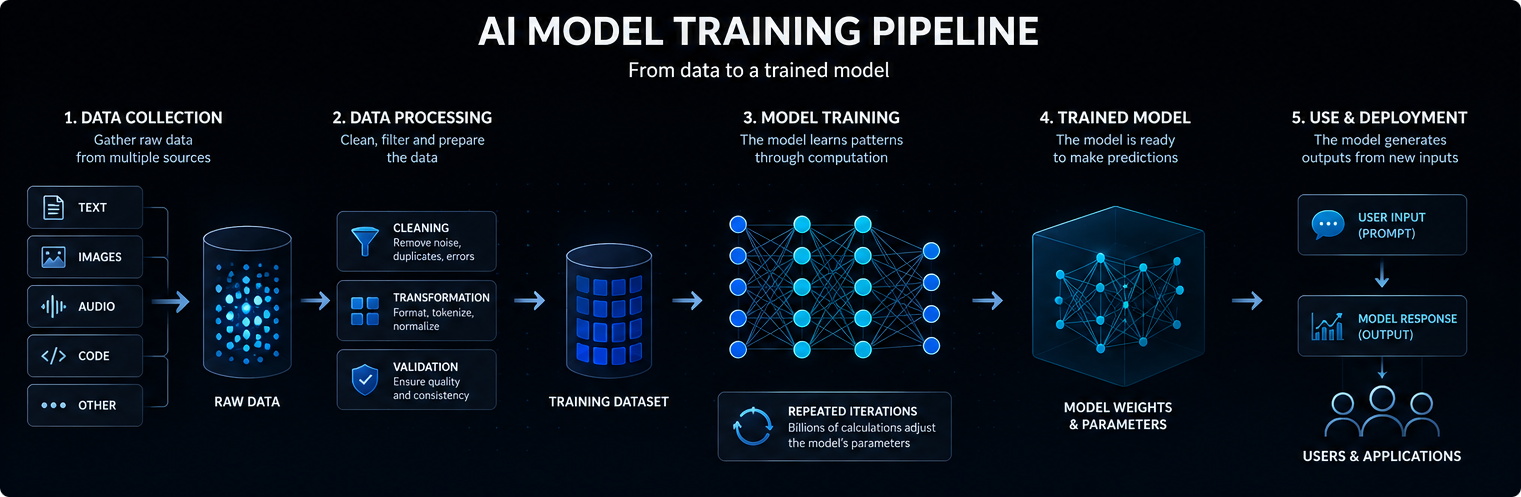
Träningen av en AI-modell börjar med data. Beroende på modell kan dessa data omfatta text, bilder, ljud, kod, video, vetenskapliga mätningar eller strukturerade register.
Stora språkmodeller tränas på stora samlingar av text och kod så att de kan lära sig statistiska relationer mellan ord, begrepp, instruktioner och utdata.
Kvaliteten, mångfalden och strukturen på träningsdata har stor betydelse för vad modellen kan lära sig, hur väl den generaliserar och var dess begränsningar visar sig.
Neurala nätverk och parametrar
Moderna AI-modeller bygger oftast på neurala nätverk. Dessa nätverk består av många lager med matematiska operationer som omvandlar indata till prognoser, klassificeringar eller genererade resultat.
De interna värden som justeras under träningen kallas parametrar. Stora AI-modeller kan innehålla miljarder eller till och med biljoner parametrar.
Träning är den process där dessa parametrar justeras så att modellen blir bättre på att förutsäga, klassificera, generera eller dra slutsatser utifrån nya indata. Enkelt uttryckt fungerar en AI-modell genom att omvandla indata till interna signaler, leda dessa signaler genom inlärda parametrar och generera det utdata som med största sannolikhet är användbart.
Hur lärande faktiskt sker
Under utbildningen bearbetar modellen exempel och gör förutsägelser. Dessa förutsägelser jämförs med förväntade resultat eller utbildningsmål.
När modellen gör misstag justerar optimeringsalgoritmerna dess parametrar något. Denna process upprepas många gånger över enorma datamängder.
Med tiden lär sig modellen statistiska mönster som gör det möjligt för den att producera mer användbara resultat när den senare får nya prompter eller inmatningar.
Varför kräver träning så mycket databehandling
Att träna stora AI-modeller kräver massiva beräkningar eftersom miljarder parametrar måste uppdateras upprepade gånger över enorma datamängder.
Denna process distribueras vanligtvis över stora GPU-kluster i specialiserade datacenter. GPU:erna utför parallella matematiska operationer mycket snabbare än konventionella processorer.
Ju större modell och dataset, desto mer beräkningar, el, kylning och infrastruktur krävs.
Hur lång tid tar en AI-träning?
Utbildningens längd varierar stort. Små modeller kan tränas på några minuter eller timmar, medan avancerade modeller kan kräva veckor eller månader av samordnade beräkningar.
Träningstiden beror på modellstorlek, datasetstorlek, hårdvarutillgänglighet, optimeringstekniker och antalet GPU:er som används parallellt.
Stora AI-labb investerar kraftigt i infrastruktur eftersom snabbare utbildningscykler gör det möjligt för dem att testa fler idéer, förbättra modeller snabbare och driftsätta nya system tidigare.
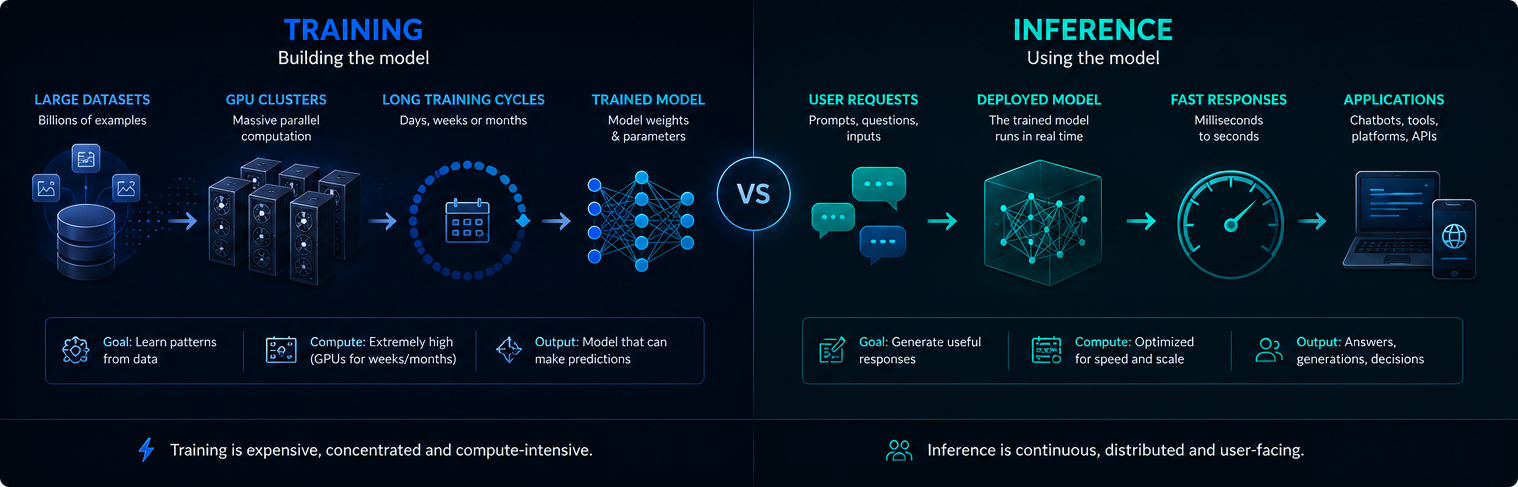
Träning kontra slutledning
Training och inference är olika faser i AI-infrastrukturen. Training skapar eller uppdaterar modellen, medan inference använder den tränade modellen för att besvara användarförfrågningar.
Utbildningen är vanligtvis koncentrerad och extremt dataintensiv. Slutledningsförmågan är kontinuerlig, eftersom AI-system kan hantera miljontals frågor varje dag.
Båda faserna har betydelse för elförbrukning, GPU-användning och den moderna AI:ns miljöpåverkan.
Framtiden för AI-träning
AI-träning kommer sannolikt att bli effektivare genom bättre hårdvara, förbättrade algoritmer, mindre specialiserade modeller och mer optimerade datapipelines.
Samtidigt fortsätter efterfrågan på mer kapabla modeller att växa. Effektivitetsförbättringar kan minska kostnaden för enskilda arbetsbelastningar samtidigt som den totala efterfrågan på databehandling fortfarande ökar.
Att förstå hur AI-modeller tränas är avgörande för att kunna utvärdera framtiden för AI-infrastruktur, energianvändning och tekniska framsteg.