目录
培训从数据开始
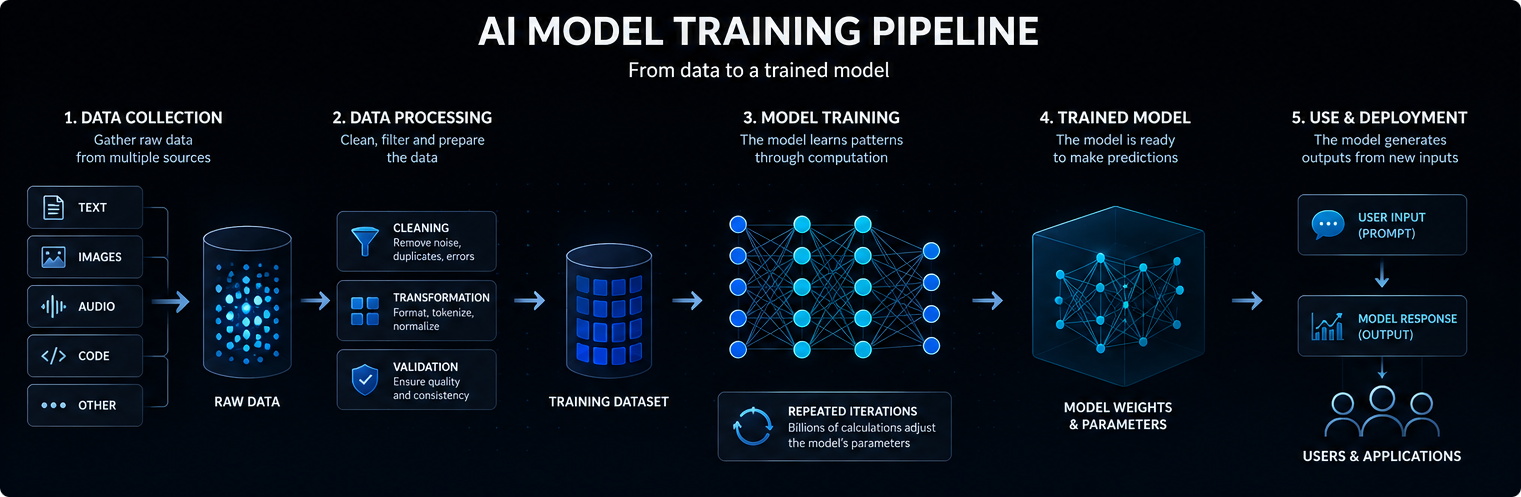
人工智能模型的训练始于数据。根据模型的不同,这些数据可能包括文本、图像、音频、代码、视频、科学测量或结构化记录。
大型语言模型是在大量文本和代码集合上训练出来的,因此可以学习单词、概念、指令和输出之间的统计关系。
训练数据的质量、多样性和结构对模型的学习内容、泛化程度和局限性有很大影响。
神经网络和参数
现代人工智能模型通常基于神经网络。这些网络包含多层数学运算,能够将输入数据转换为预测结果、分类结果或生成输出。
在训练过程中调整的内部值称为参数。大型人工智能模型可能包含数十亿甚至数万亿个参数。
训练就是调整这些参数的过程,以便模型能够更好地对新的输入进行预测、分类、生成或推理。通俗地说,人工智能模型的工作原理是将输入转换为内部信号,将这些信号通过已学习的参数进行处理,从而生成最有可能有用的输出。
学习是如何发生的
在训练过程中,模型会处理示例并做出预测。这些预测会与预期输出或训练目标进行比较。
当模型出现错误时,优化算法会对其参数稍作调整。这一过程会在庞大的数据集中重复多次。
随着时间的推移,模型会学习到一些统计模式,使其在以后接收到新的提示或输入时能够产生更有用的输出。
为什么培训需要如此多的计算
训练大型人工智能模型需要大量计算,因为必须在海量数据中反复更新数十亿个参数。
这一过程通常分布在专用数据中心内的大型 GPU 集群上。GPU 执行并行数学运算的速度远远超过传统处理器。
模型和数据集越大,所需的计算、电力、冷却和基础设施就越多。
人工智能培训需要多长时间?
训练时间差别很大。小型模型可以在几分钟或几小时内完成训练,而前沿模型可能需要数周或数月的协调计算。
训练时间取决于模型大小、数据集大小、硬件可用性、优化技术以及并行使用的 GPU 数量。
大型人工智能实验室在基础设施方面投入巨资,因为更快的训练周期可以让他们测试更多想法,更快地改进模型,更快地部署新系统。
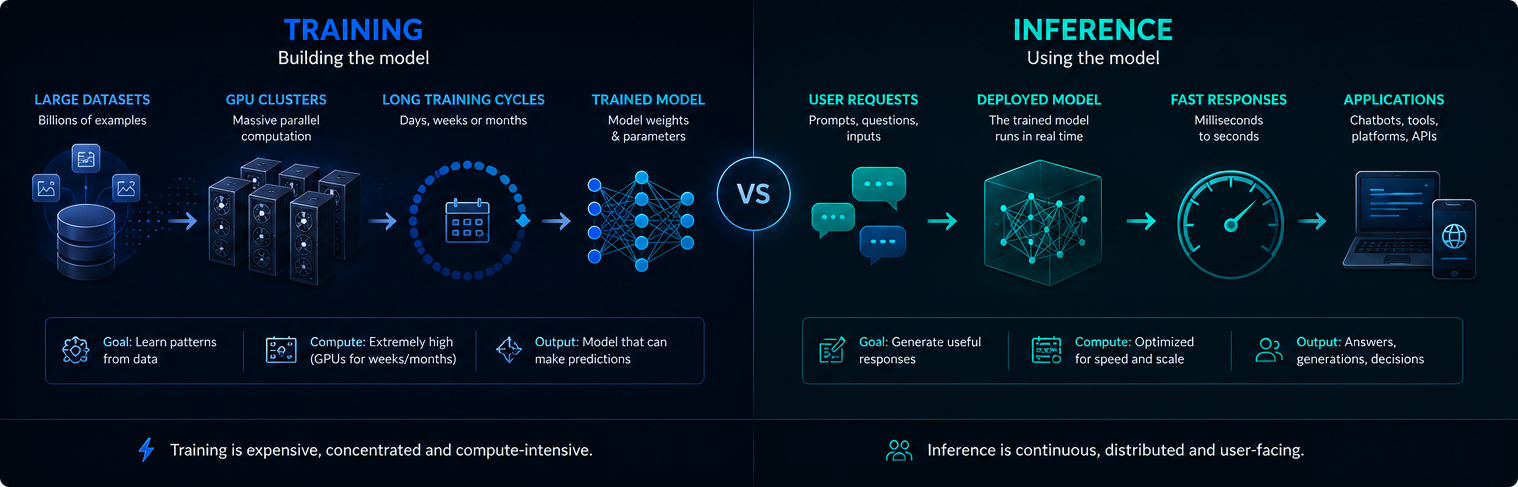
训练与推理
训练和推理是人工智能基础设施的不同阶段。训练创建或更新模型,而推理则使用训练好的模型来回答用户的请求。
训练通常是集中进行的,计算密集度极高。推理是持续性的,因为部署的人工智能系统每天可能提供数百万个提示。
这两个阶段对现代人工智能的电力需求、GPU 使用和环境影响都很重要。
人工智能培训的未来
通过更好的硬件、改进的算法、更小的专用模型和更优化的数据管道,人工智能训练可能会变得更加高效。
与此同时,对更高性能机型的需求也在持续增长。效率的提高可能会降低单个工作负载的成本,而总的计算需求仍在增加。
了解人工智能模型是如何训练出来的,对于评估人工智能基础设施、能源使用和技术进步的未来至关重要。