目录
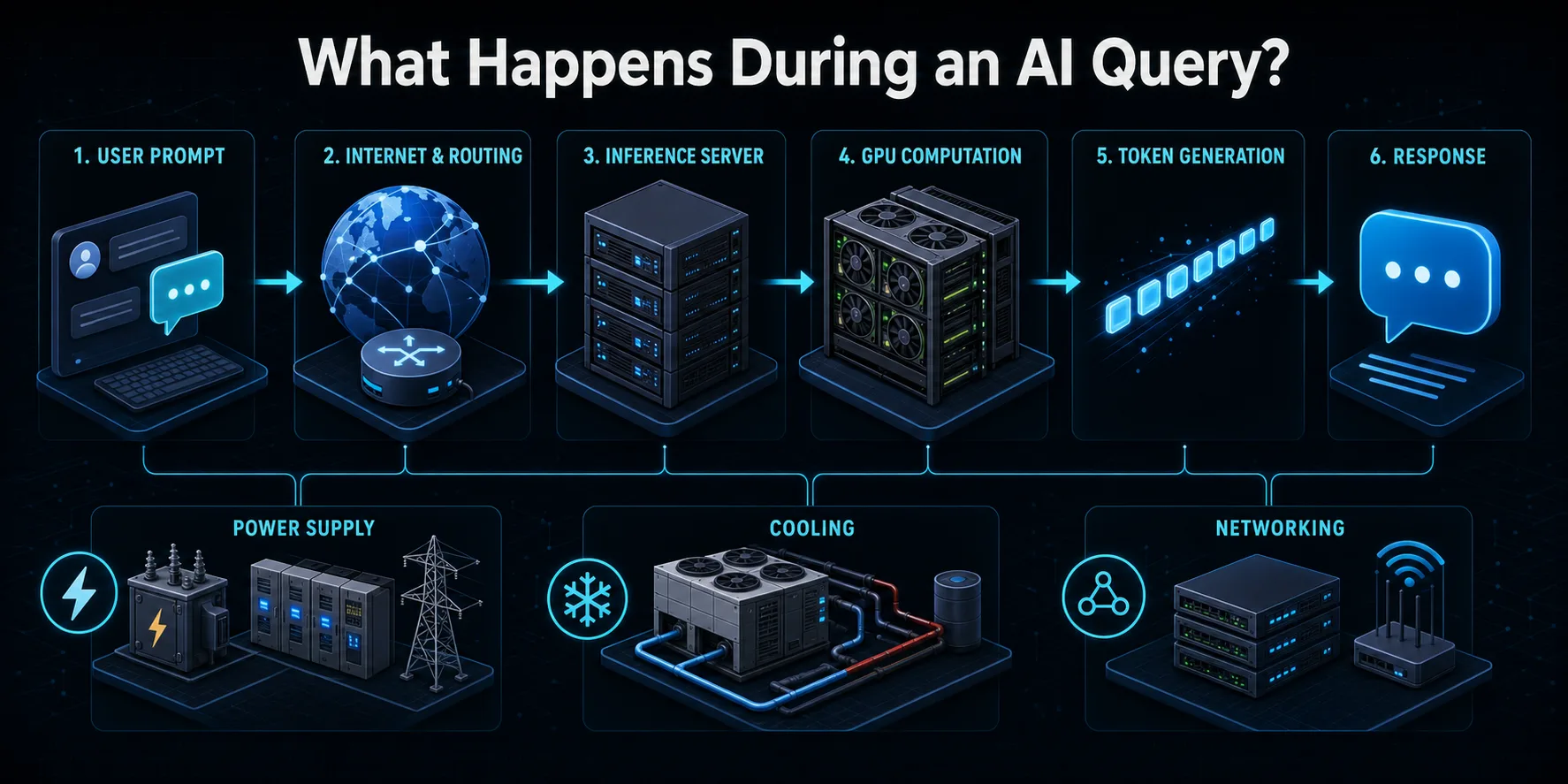
发送人工智能查询时会发生什么?
当您向人工智能服务提交提示时,请求首先会通过互联网传送到提供商的基础设施。路由系统会对请求进行验证,应用安全和使用控制,并将其导向可用的推理服务器。负载平衡器可以在多台机器中进行选择,这样用户流量就会被分散,而不会使系统的某个部分超负荷。
服务器将提示音转换成标记,即语言模型处理的数字单位。这些标记和任何先前的对话上下文都会被加载到加速器内存中。然后,GPU 或其他人工智能芯片会对模型参数进行层层矩阵计算,以预测下一个标记。这个过程会重复多次,直到响应完成或达到配置的限制。
生成的输出被解码成文本并流回给用户,往往是在后面的令牌仍在计算的时候。在这种可见的交互过程中,存储、网络、监控、电源转换和冷却设备仍处于工作状态。因此,尽管加速器通常执行大部分密集型计算,但一次查询所消耗的电力远远超过仅在 GPU 上测量到的电力。
人工智能查询为何耗电
人工智能推理是一种主动计算,而不是简单地从数据库中检索。一个大型模型必须对每个生成的标记进行多次数值运算,使用的参数可能会占用数十或数百千兆字节的内存。在高带宽内存和处理器内核之间移动这些参数和中间值,除了计算本身还要消耗电力。
工作量会随着模型、提示和要求的输出而增加。冗长的对话历史需要处理更多的上下文,而冗长的答案则会让加速器运行更多的生成步骤。图像、音频和视频系统可能需要不同的处理管道或重复细化操作,因此人工智能查询并不是一个标准化的工作单位。
数据中心的开销也很重要。服务器需要电源、网络、存储和冷却,在电力转换和分配过程中会损失一些电力。运营商通常通过用电效率或 PUE 来表示这种开销。高效的设施能使总能耗更接近计算设备使用的能耗,而效率较低的设施则需要更多的电力来支持相同的推理工作量。
人工智能查询耗电量有多大?
人工智能查询没有一个通用的电量数字。对文本交互的公开估算通常从几分之一瓦时到几瓦时不等,但这一范围应被视为一个数量级,而不是一个固定的换算。一个经过优化、利用率高的模型所处理的简短请求,其能耗要远远低于一个在未充分利用的硬件上运行的大型模型所做出的冗长响应。
瓦时测量的是能量,而不是瞬时功率。例如,一台服务器在几分之一秒内消耗的高功率,其总能耗可能低于运行时间更长的低功率系统。因此,可靠的每次查询估算既需要设备的耗电量,也需要查询持续时间和设备所占份额。
与网络搜索、灯泡或手机充电进行比较,可以使规模更容易直观,但它们往往隐藏了重要的假设。与此相关的问题并不是每个提示是否都消耗一个特定的数量。而是哪种模式为请求提供了服务、处理了多少代币和模式、请求的分组效率如何以及计算中包含了多少基础设施能源。
估计数为何不同
人工智能提供商很少公布将单个请求与模型大小、硬件利用率、令牌数量和设施开销联系起来的完整测量结果。因此,研究人员必须将公开的硬件规格、基准测试结果、估计的服务时间和数据中心效率假设结合起来。任何一步的不同选择都可能产生截然不同的答案。
批处理是造成差异的一个主要原因。推理服务器可以同时处理多个用户,在批处理中共享模型加载和计算。高利用率会降低分配给每个请求的平均能量,而闲置容量、延迟要求或流量峰值则会导致昂贵的硬件被部分使用。较新的加速器还可以更快或以更少的焦耳数完成相同的工作负载。
估算的边界也会改变结果。有些计算只计算加速器的能量;有些计算则包括 CPU、内存、网络、冷却和功率损耗。大多数按查询计算的数据不包括早期用于制造硬件和训练模型的能量。只有在系统边界和假设明确的情况下,估算才最有用,而不是将单一数字作为通用数字。
人工智能查询与人工智能训练
训练通过反复处理大型数据集和调整参数来创建或更新模型。一次重要的训练运行可以占用数千台加速器数天或数周,使其成为一个集中且高度可见的计算事件。训练完成后,生成的模型可以部署到许多推理服务器上,以满足用户的要求。
一次交互的推理量通常要小得多,但它是连续的。生产系统必须随时做出响应,保持足够的容量以应对峰值,并为多个地区的用户提供服务。因此,能量曲线分布在许多数据中心,每次生成文本、图像、音频或其他输出时都会重复。
两种工作负载都不应该被自动假定为主导模型的终生用电量。训练可能是最大的单次事件,尤其是对前沿系统而言,而当一项服务在数月或数年内处理巨大流量时,推理最终可能会超过训练。两者之间的平衡取决于模型的重新训练频率、部署范围以及人们使用模型的密集程度。
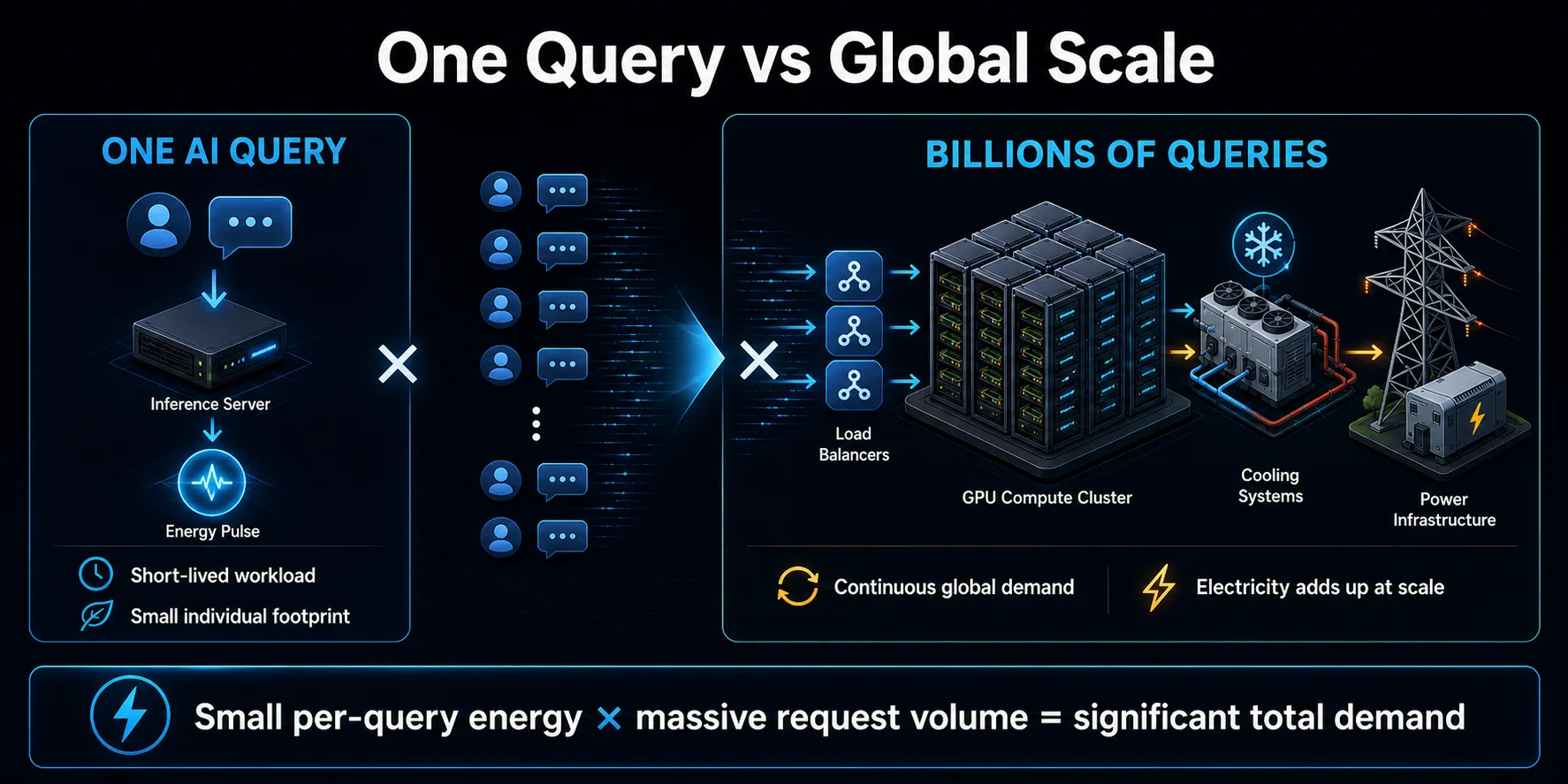
数十亿次查询的总和
人工智能查询对环境的影响主要来自倍增。一次简短的提示可能只消耗少量能源,但消费者助手、搜索功能、编码工具和业务应用程序却能产生大量请求。如此不断重复,每次请求所消耗的少量能源就会成为数据中心的巨大负荷。
需求不仅限于可见的聊天机器人消息。应用程序可能会调用多个模型来回答用户的一个操作,使用不同的模型进行审核或检索,重试失败的请求,以及生成后台摘要或建议。代理系统可以扩展这种模式,在完成单个任务时重复调用模型和软件工具。
规模也会影响基础设施规划。提供商为增长和峰值流量建立容量,这可能会在每台服务器被充分利用之前增加电力需求。总的影响取决于每次查询的效率和使用量的增长速度。如果需求增长的速度快于效率提高的速度,那么即使每次交互的能耗降低,总耗电量也会继续上升。
人工智能查询会变得更高效吗?
人工智能推理有可能在类似任务的层面上变得更加节能。新的加速器可以为每单位电力提供更多计算,而量化、剪枝、推测解码和改进的模型架构则可以减少有用输出所需的操作。更好的调度和批处理也能在不改变用户体验的情况下提高硬件利用率。
小型专业模型提供了另一条途径。对于分类、提取或常规问题,服务并不总是需要最大的模型。将简单工作路由到小型模型、限制不必要的上下文和缓存可重复使用的结果,可以减少延迟和用电量。数据中心可通过电力输送、冷却和工作负载布置进一步提高总效率。
效率并不能保证降低总体消耗。更快、更便宜的人工智能会鼓励更多的应用、更长的交互和新的计算密集型功能,这种效应有时被称为反弹需求。因此,人工智能查询的未来电力足迹将取决于两个相互竞争的趋势:每单位有用工作的效率提高有多快,以及人工智能使用的总量和复杂性增长有多快。