Turinys
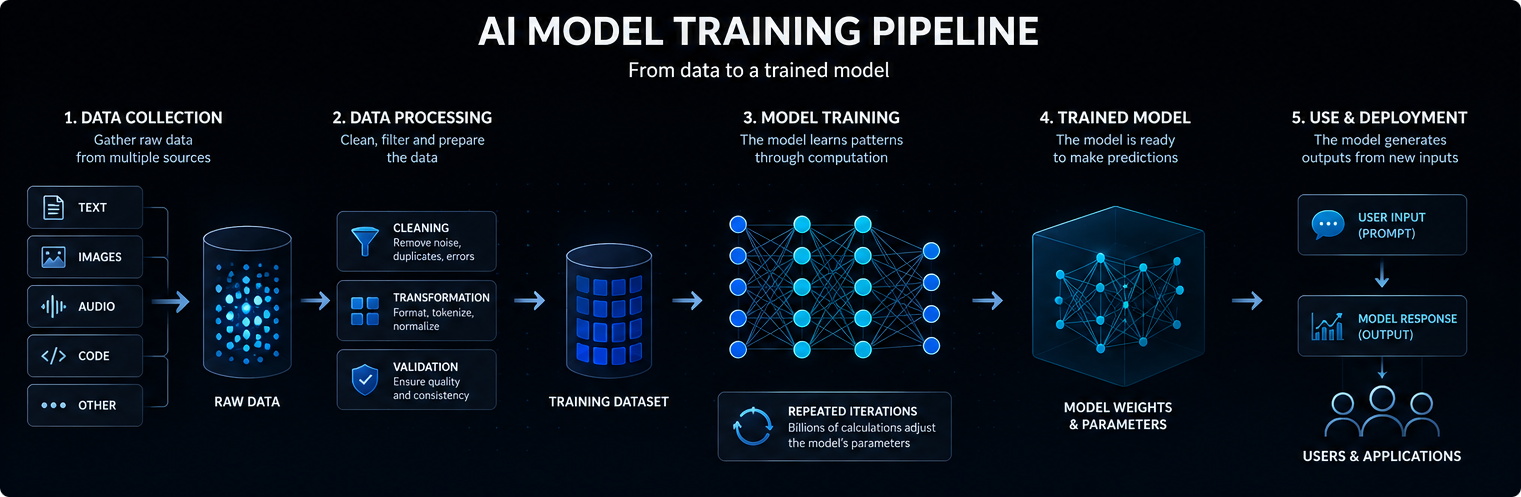
Mokymas prasideda nuo duomenų
Dirbtinio intelekto modelio mokymas prasideda nuo duomenų. Priklausomai nuo modelio, šiuos duomenis gali sudaryti tekstas, vaizdai, garso įrašai, kodai, vaizdo įrašai, moksliniai matavimai arba struktūrizuoti įrašai.
Dideli kalbos modeliai mokomi iš didžiulių tekstų ir kodų rinkinių, kad galėtų išmokti statistinių ryšių tarp žodžių, sąvokų, instrukcijų ir rezultatų.
Mokymo duomenų kokybė, įvairovė ir struktūra daro didelę įtaką tam, ką modelis gali išmokti, kaip gerai jis apibendrina ir kur pasireiškia jo trūkumai.
Neuroniniai tinklai ir parametrai
Šiuolaikiniai dirbtinio intelekto modeliai paprastai grindžiami neuroniniais tinklais. Šie tinklai susideda iš daugybės matematinių operacijų sluoksnių, kurie įvestinius duomenis paverčia prognozėmis, klasifikacijomis arba generuojamais rezultatais.
Mokymo metu koreguojamos vidinės reikšmės vadinamos parametrais. Dideli dirbtinio intelekto modeliai gali turėti milijardus ar net trilijonus parametrų.
Mokymas – tai procesas, kurio metu šie parametrai koreguojami taip, kad modelis galėtų geriau prognozuoti, klasifikuoti, generuoti ar daryti išvadas remiantis naujais įvesties duomenimis. Paprastai tariant, dirbtinio intelekto modelis veikia taip: įvesties duomenys paverčiami vidiniais signalais, šie signalai perduodami per išmoktus parametrus, o galiausiai generuojamas labiausiai tikėtinas naudingas rezultatas.
Kaip iš tikrųjų vyksta mokymasis
Mokymo metu modelis apdoroja pavyzdžius ir rengia prognozes. Šios prognozės lyginamos su laukiamais rezultatais arba mokymo tikslais.
Kai modelis daro klaidų, optimizavimo algoritmai šiek tiek pakoreguoja jo parametrus. Šis procesas daug kartų kartojamas didžiuliuose duomenų rinkiniuose.
Laikui bėgant modelis išmoksta statistinių modelių, kurie leidžia jam pateikti naudingesnius rezultatus, kai jis vėliau gauna naujus raginimus ar įvestis.
Kodėl mokymams reikia tiek daug skaičiavimų
Dideliems dirbtinio intelekto modeliams mokyti reikalingi didžiuliai skaičiavimai, nes milijardai parametrų turi būti pakartotinai atnaujinami naudojant didžiulius duomenų kiekius.
Šis procesas paprastai paskirstomas dideliems GPU klasteriams specializuotuose duomenų centruose. GPU lygiagrečias matematines operacijas atlieka daug greičiau nei įprasti procesoriai.
Kuo didesnis modelis ir duomenų rinkinys, tuo daugiau reikia skaičiavimų, elektros energijos, aušinimo ir infrastruktūros.
Kiek laiko trunka dirbtinio intelekto mokymas?
Mokymo trukmė labai skiriasi. Mažus modelius galima apmokyti per kelias minutes ar valandas, o ribiniams modeliams gali prireikti savaičių ar mėnesių koordinuotų skaičiavimų.
Mokymo trukmė priklauso nuo modelio dydžio, duomenų rinkinio dydžio, techninės įrangos prieinamumo, optimizavimo metodų ir lygiagrečiai naudojamų GPU skaičiaus.
Didelės dirbtinio intelekto laboratorijos daug investuoja į infrastruktūrą, nes greitesni mokymo ciklai leidžia joms išbandyti daugiau idėjų, greičiau tobulinti modelius ir greičiau diegti naujas sistemas.
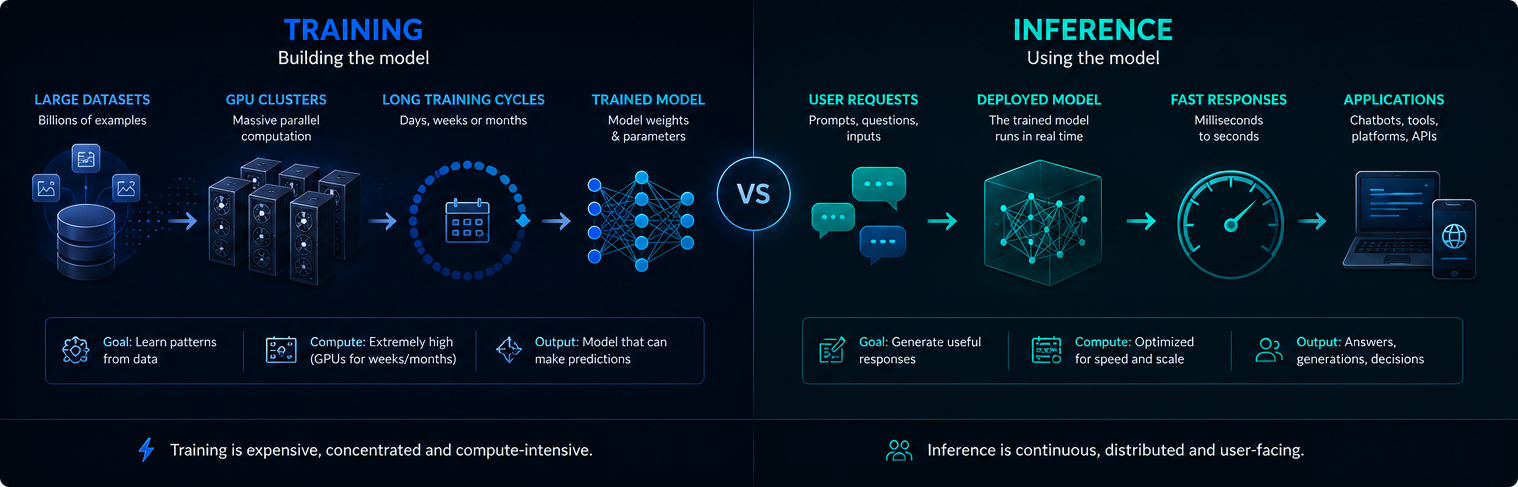
Mokymas ir išvada
Mokymas ir išvadų darymas yra skirtingi dirbtinio intelekto infrastruktūros etapai. Mokymo metu sukuriamas arba atnaujinamas modelis, o išvadų darymo metu apmokytas modelis naudojamas atsakant į naudotojo užklausas.
Mokymai paprastai būna koncentruoti ir reikalauja itin daug kompiuterinių išteklių. Išvados daromos nuolat, nes įdiegtos dirbtinio intelekto sistemos kasdien gali pateikti milijonus užklausų.
Abu etapai turi reikšmės elektros energijos poreikiui, GPU naudojimui ir šiuolaikinio dirbtinio intelekto poveikiui aplinkai.
AI mokymo ateitis
Tikėtina, kad dirbtinio intelekto mokymas taps efektyvesnis dėl geresnės aparatinės įrangos, patobulintų algoritmų, mažesnių specializuotų modelių ir labiau optimizuotų duomenų vamzdynų.
Tuo pat metu vis didėja galingesnių modelių paklausa. Efektyvumo didinimas gali sumažinti atskirų darbo krūvių sąnaudas, nors bendra skaičiavimo įrangos paklausa vis dar didėja.
Suprasti, kaip mokomi dirbtinio intelekto modeliai, labai svarbu vertinant dirbtinio intelekto infrastruktūros, energijos naudojimo ir technologinės pažangos ateitį.