Tabel de conținut
Ce se întâmplă când trimiteți o interogare AI?
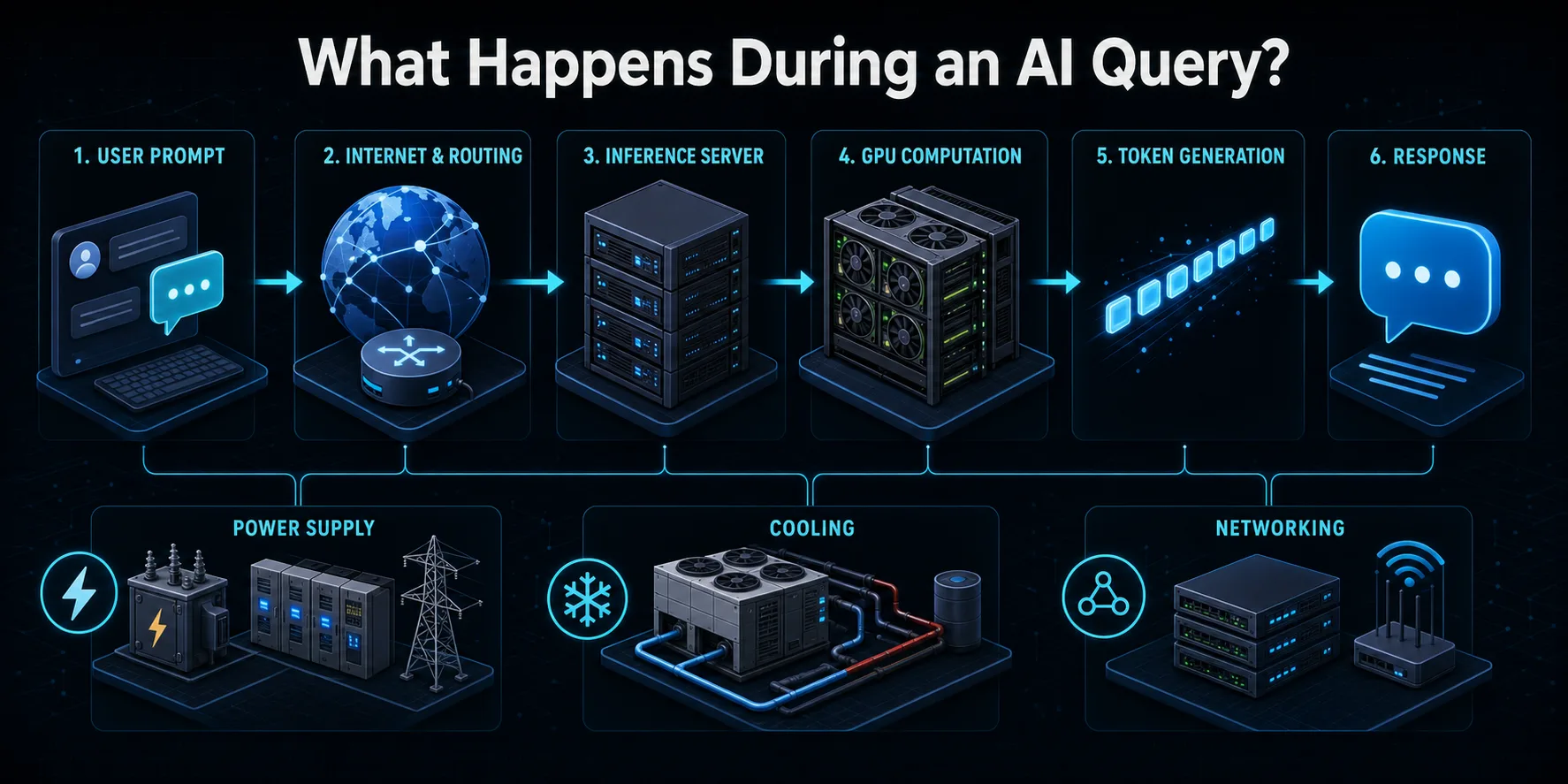
Atunci când trimiteți o solicitare către un serviciu de inteligență artificială, aceasta călătorește mai întâi pe internet către infrastructura furnizorului. Sistemele de rutare autentifică cererea, aplică controale de siguranță și de utilizare și o direcționează către un server de inferență disponibil. Un distribuitor de sarcină poate alege între mai multe mașini, astfel încât traficul utilizatorilor să fie distribuit fără a supraîncărca o parte a sistemului.
Serverul convertește promptul în token-uri, unități numerice prelucrate de un model lingvistic. Aceste simboluri și orice context al conversației anterioare sunt încărcate în memoria acceleratorului. GPU-urile sau alte cipuri de inteligență artificială efectuează apoi straturi de calcule matriciale asupra parametrilor modelului pentru a prezice următorul jeton. Procesul se repetă de mai multe ori până când răspunsul este complet sau atinge o limită configurată.
Rezultatul generat este decodat în text și transmis înapoi utilizatorului, adesea în timp ce jetoanele ulterioare sunt încă calculate. În jurul acestei interacțiuni vizibile, echipamentele de stocare, de rețea, de monitorizare, de conversie a energiei și de răcire rămân active. Prin urmare, o interogare consumă mai mult decât energia electrică măsurată doar la GPU, chiar dacă acceleratorul efectuează de obicei cea mai mare parte a calculelor intensive.
De ce interogările AI consumă energie electrică
Inferența AI este un calcul activ, mai degrabă decât o simplă recuperare dintr-o bază de date. Un model de mari dimensiuni trebuie să evalueze multe operații numerice pentru fiecare jeton generat, utilizând parametri care pot ocupa zeci sau sute de gigabytes de memorie. Deplasarea acestor parametri și a valorilor intermediare între memoria cu lățime de bandă mare și nucleele procesorului consumă energie electrică, pe lângă calculele propriu-zise.
Volumul de muncă crește odată cu modelul, solicitarea și rezultatul cerut. Istoricul conversațiilor lungi necesită procesarea unui context mai larg, în timp ce răspunsurile lungi mențin acceleratoarele în funcțiune pentru mai mulți pași de generare. Sistemele de imagine, audio și video pot necesita diferite conducte de procesare sau operațiuni repetate de rafinare, astfel încât o interogare AI nu este o unitate de lucru standardizată.
De asemenea, cheltuielile generale ale centrului de date sunt importante. Serverele au nevoie de surse de alimentare, rețele, stocare și răcire, iar o parte din electricitate se pierde în timpul conversiei și distribuției energiei. Operatorii exprimă adesea aceste cheltuieli generale prin eficiența utilizării energiei, sau PUE. O instalație eficientă aduce energia totală mai aproape de energia utilizată de echipamentele de calcul, în timp ce o instalație mai puțin eficientă necesită mai multă energie electrică de sprijin pentru același volum de muncă de inferență.
Câtă energie electrică consumă o interogare AI?
Nu există o cifră universală de energie electrică pentru o interogare AI. Estimările publice pentru interacțiunile text variază de obicei de la fracțiuni de watt-oră la câțiva watt-oră, dar intervalul ar trebui tratat mai degrabă ca un ordin de mărime decât ca o conversie fixă. O cerere scurtă gestionată de un model optimizat și bine utilizat poate consuma mult mai puțină energie decât un răspuns lung de la un model mai mare care rulează pe un hardware subutilizat.
Un watt-oră măsoară energia, nu puterea instantanee. De exemplu, un server care consumă multă energie timp de o fracțiune de secundă poate utiliza mai puțină energie totală decât un sistem cu putere mai mică care funcționează mult mai mult timp. Prin urmare, o estimare credibilă pe cerere necesită atât consumul de energie al echipamentului, cât și durata și ponderea acestui echipament atribuibile cererii.
Comparațiile cu căutările pe internet, becurile sau încărcarea telefonului pot face scala mai ușor de vizualizat, dar adesea ascund ipoteze importante. Întrebarea relevantă nu este dacă fiecare solicitare consumă o anumită cantitate. Este vorba despre modelul care a servit solicitarea, despre câte tokenuri și modalități au fost procesate, despre cât de eficient au fost grupate solicitările și despre câtă energie de infrastructură a fost inclusă în calcul.
De ce variază estimările
Furnizorii de inteligență artificială publică rareori măsurători complete care fac legătura între cererile individuale și dimensiunea modelului, utilizarea hardware, numărul de jetoane și cheltuielile generale ale instalației. Prin urmare, cercetătorii trebuie să combine specificațiile hardware dezvăluite, rezultatele testelor de referință, timpii de servire estimați și ipotezele privind eficiența centrelor de date. Alegeri diferite la orice etapă pot produce răspunsuri substanțial diferite.
Gruparea în loturi este o sursă majoră de variație. Un server de inferență poate procesa mai mulți utilizatori împreună, împărțind încărcarea modelului și calculul în cadrul unui lot. Utilizarea ridicată poate reduce energia medie alocată fiecărei cereri, în timp ce capacitatea neutilizată, cerințele de latență sau vârfurile de trafic pot lăsa hardware-ul costisitor parțial utilizat. Acceleratoarele mai noi pot, de asemenea, să finalizeze aceeași sarcină de lucru mai rapid sau cu mai puțini jouli.
Limita estimării modifică, de asemenea, rezultatul. Unele calcule iau în considerare doar energia acceleratorului; altele includ procesoarele, memoria, rețelele, răcirea și pierderile de energie. Majoritatea cifrelor per interogare exclud energia anterioară utilizată pentru fabricarea hardware-ului și antrenarea modelului. Estimările sunt mai utile atunci când limitele sistemului și ipotezele sunt explicite, nu atunci când un singur număr este prezentat ca fiind universal.
Interogări AI versus antrenare AI
Antrenarea creează sau actualizează un model prin prelucrarea repetată a unor seturi mari de date și ajustarea parametrilor acestuia. O rulare majoră de antrenare poate ocupa mii de acceleratoare timp de zile sau săptămâni, ceea ce o face un eveniment de calcul concentrat și foarte vizibil. Odată ce antrenarea este finalizată, modelul rezultat poate fi implementat pe mai multe servere de inferență pentru a răspunde solicitărilor utilizatorilor.
Inferența este de obicei mult mai mică pentru o interacțiune, dar este continuă. Sistemele de producție trebuie să răspundă la orice oră, să păstreze suficientă capacitate disponibilă pentru vârfuri și să deservească utilizatori din mai multe regiuni. Prin urmare, profilul energetic este distribuit în mai multe centre de date și repetat de fiecare dată când sunt generate texte, imagini, materiale audio sau alte rezultate.
Nu ar trebui să se presupună în mod automat că niciun volum de lucru nu va domina consumul de energie electrică al unui model pe întreaga durată de viață. Antrenarea poate fi cel mai mare eveniment individual, în special pentru sistemele de frontieră, în timp ce inferența îl poate depăși în cele din urmă atunci când un serviciu gestionează un trafic enorm pe parcursul lunilor sau anilor. Echilibrul depinde de frecvența cu care modelele sunt reantrenate, de amploarea cu care sunt implementate și de intensitatea cu care oamenii le utilizează.
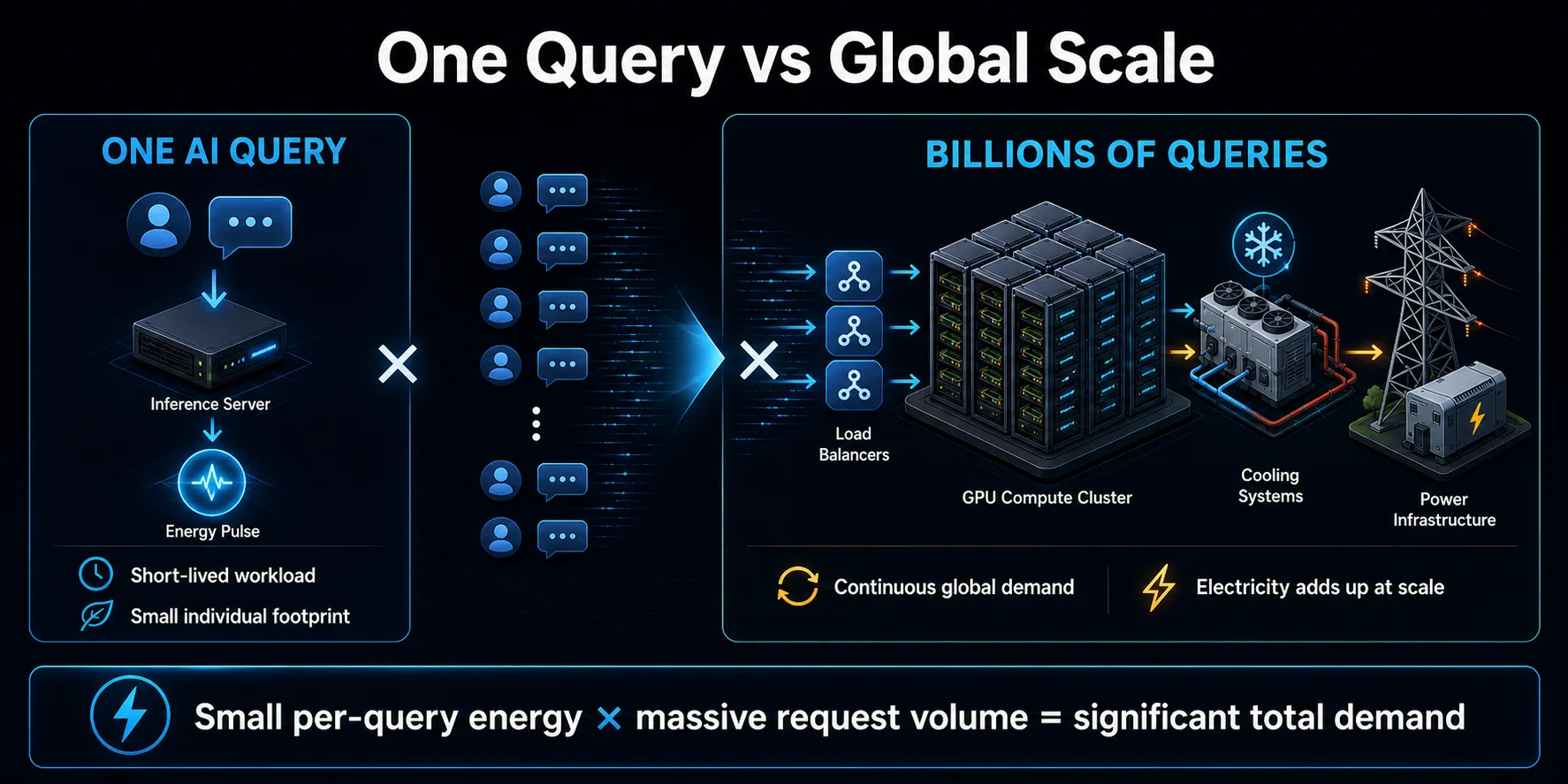
Miliardele de interogări se adună
Importanța pentru mediu a interogărilor AI provine în primul rând din multiplicare. O singură solicitare scurtă poate reprezenta o cantitate mică de energie, însă asistenții consumatorilor, funcțiile de căutare, instrumentele de codare și aplicațiile de afaceri pot genera un număr mare de solicitări. Repetată continuu, energia modestă per solicitare devine o sarcină substanțială pentru centrul de date.
Cererea nu se limitează la mesajele vizibile ale chatbotului. Aplicațiile pot efectua mai multe apeluri la modele pentru a răspunde unei acțiuni a utilizatorului, pot utiliza modele separate pentru moderare sau recuperare, pot încerca din nou solicitări eșuate și pot genera rezumate sau recomandări. Sistemele agenetice pot extinde acest model prin apelarea repetată a modelelor și instrumentelor software în timpul îndeplinirii unei singure sarcini.
Scara afectează, de asemenea, planificarea infrastructurii. Furnizorii construiesc capacități pentru creștere și trafic de vârf, ceea ce poate crește cererea de energie electrică înainte ca fiecare server să fie complet utilizat. Impactul total depinde atât de eficiența per interogare, cât și de rata la care se extinde utilizarea. Dacă cererea crește mai repede decât eficiența, consumul agregat de energie electrică poate continua să crească, chiar dacă fiecare interacțiune individuală devine mai puțin energointensivă.
Vor deveni interogările AI mai eficiente?
Este probabil ca inferența AI să devină mai eficientă din punct de vedere energetic la nivelul unei sarcini comparabile. Noile acceleratoare oferă mai multe calcule pe unitate de electricitate, în timp ce cuantificarea, reducerea, decodificarea speculativă și arhitecturile de model îmbunătățite pot reduce operațiile necesare pentru un rezultat util. O mai bună planificare și repartizare în loturi poate crește, de asemenea, utilizarea hardware-ului fără a modifica experiența utilizatorului.
Modelele specializate mai mici oferă o altă cale. Un serviciu nu are întotdeauna nevoie de cel mai mare model pentru clasificare, extragere sau întrebări de rutină. Direcționarea lucrărilor simple către modele compacte, limitarea contextului inutil și stocarea în cache a rezultatelor reutilizabile pot reduce atât latența, cât și consumul de energie electrică. Centrele de date pot îmbunătăți și mai mult eficiența totală prin furnizarea de energie, răcire și plasarea volumului de lucru.
Eficiența nu garantează un consum global mai scăzut. Inteligența artificială mai rapidă și mai ieftină poate încuraja mai multe aplicații, interacțiuni mai îndelungate și noi caracteristici care necesită multe calcule, un efect descris uneori ca cerere de revenire. Prin urmare, amprenta electrică viitoare a interogărilor AI va depinde de două tendințe concurente: cât de repede devine mai eficientă fiecare unitate de muncă utilă și cât de repede crește volumul total și complexitatea utilizării AI.