Зміст
Навчання починається з даних
Навчання моделі ШІ починається з даних. Залежно від моделі, ці дані можуть включати текст, зображення, аудіо, код, відео, наукові вимірювання або структуровані записи.
Великі мовні моделі навчаються на величезних колекціях тексту та коду, щоб вони могли вивчати статистичні зв'язки між словами, поняттями, інструкціями та результатами.
Якість, різноманітність і структура навчальних даних сильно впливають на те, чого може навчитися модель, наскільки добре вона узагальнює і де з'являються її обмеження.
Нейронні мережі та параметри
Сучасні моделі штучного інтелекту зазвичай базуються на нейронних мережах. Ці мережі містять багато шарів математичних операцій, які перетворюють вхідні дані на прогнози, класифікації або генеровані результати.
Внутрішні значення, які коригуються під час навчання, називаються параметрами. Великі моделі ШІ можуть містити мільярди або навіть трильйони параметрів.
Навчання — це процес налаштування цих параметрів, завдяки якому модель починає ефективніше прогнозувати, класифікувати, генерувати або міркувати на основі нових вхідних даних. Простіше кажучи, модель штучного інтелекту працює таким чином: вона перетворює вхідні дані на внутрішні сигнали, пропускає ці сигнали через навчені параметри та генерує найбільш ймовірний корисний результат.
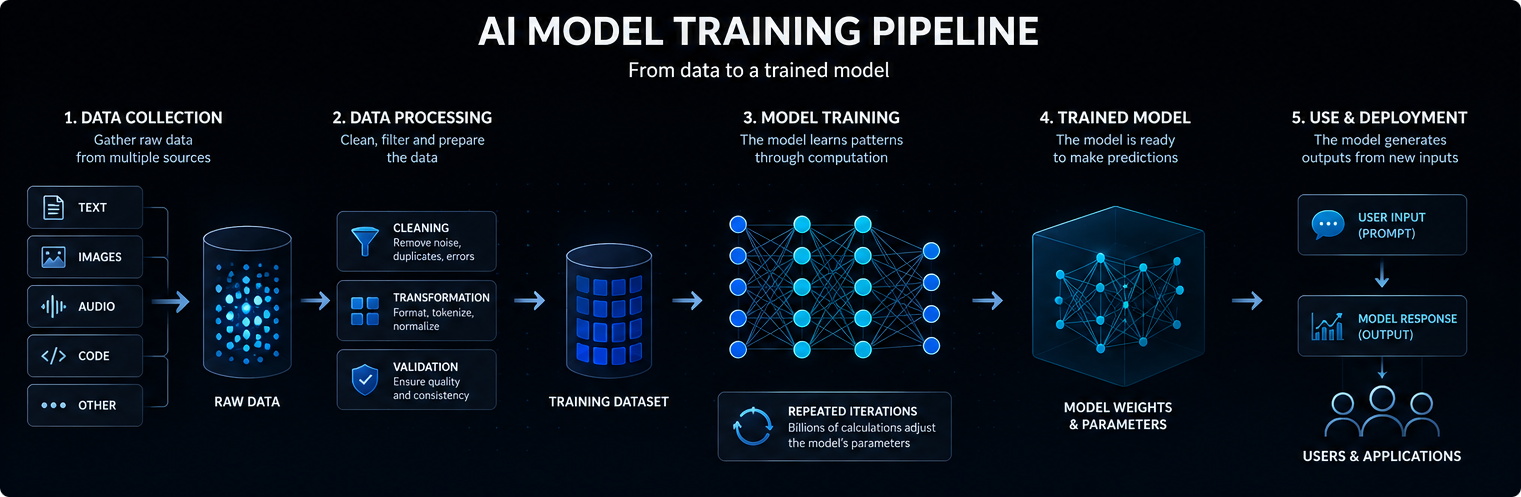
Як насправді відбувається навчання
Під час навчання модель обробляє приклади і робить прогнози. Ці прогнози порівнюються з очікуваними результатами або цілями навчання.
Коли модель помиляється, алгоритми оптимізації дещо змінюють її параметри. Цей процес повторюється багато разів на величезних масивах даних.
З часом модель вивчає статистичні закономірності, які дозволяють їй видавати більш корисні результати, коли вона пізніше отримує нові підказки або вхідні дані.
Чому навчання вимагає так багато обчислень
Навчання великих моделей ШІ вимагає величезних обчислень, оскільки мільярди параметрів повинні постійно оновлюватися у величезних обсягах даних.
Цей процес зазвичай розподіляється між великими кластерами графічних процесорів у спеціалізованих центрах обробки даних. Графічні процесори виконують паралельні математичні операції набагато швидше, ніж звичайні процесори.
Чим більша модель і набір даних, тим більше потрібно обчислювальних ресурсів, електроенергії, охолодження та інфраструктури.
Скільки часу займає навчання ШІ?
Тривалість навчання варіюється в широких межах. Невеликі моделі можна навчити за лічені хвилини або години, тоді як граничні моделі можуть потребувати тижнів або місяців скоординованих обчислень.
Час навчання залежить від розміру моделі, розміру набору даних, доступності апаратного забезпечення, методів оптимізації та кількості паралельно використовуваних графічних процесорів.
Великі лабораторії ШІ інвестують значні кошти в інфраструктуру, оскільки прискорені цикли навчання дозволяють їм тестувати більше ідей, швидше вдосконалювати моделі та швидше розгортати нові системи.
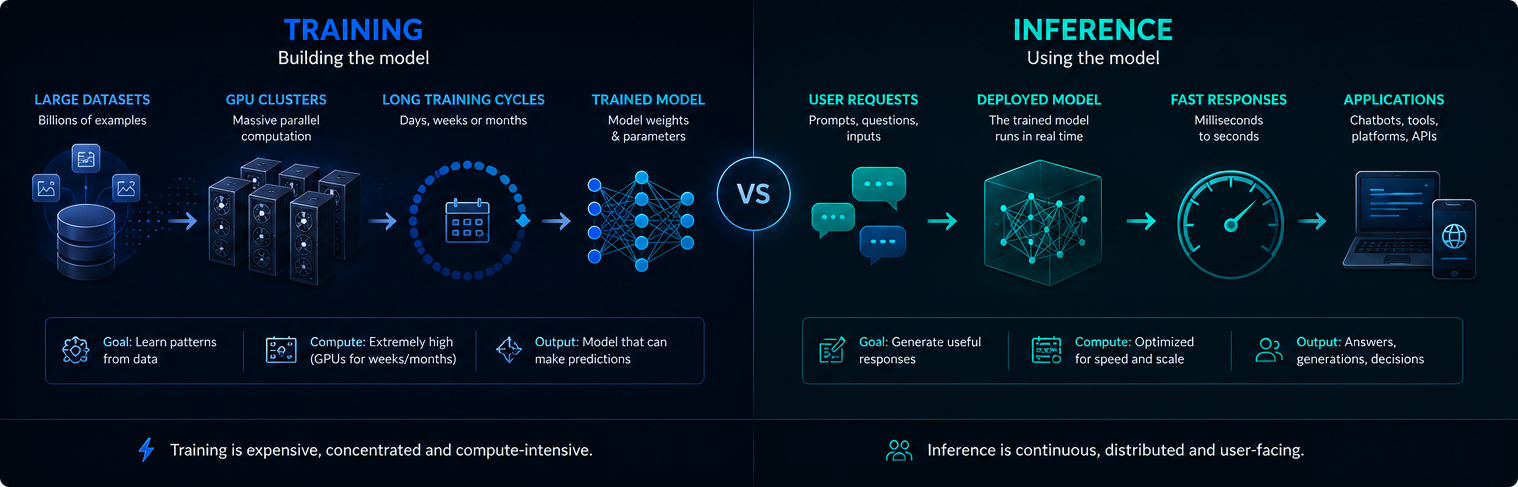
Навчання vs висновки
Навчання та виведення - це різні етапи інфраструктури ШІ. Навчання створює або оновлює модель, тоді як висновок використовує навчену модель для відповіді на запити користувача.
Навчання, як правило, концентроване і надзвичайно трудомістке. Висновки відбуваються безперервно, оскільки розгорнуті системи ШІ можуть обробляти мільйони підказок щодня.
Обидві фази мають значення для попиту на електроенергію, використання графічних процесорів і впливу сучасного ШІ на навколишнє середовище.
Майбутнє навчання ШІ
Навчання ШІ, ймовірно, стане більш ефективним завдяки кращому обладнанню, вдосконаленим алгоритмам, меншим за розміром спеціалізованим моделям і більш оптимізованим конвеєрам даних.
Водночас попит на більш продуктивні моделі продовжує зростати. Підвищення ефективності може знизити вартість окремих робочих навантажень, тоді як загальний попит на обчислення все ще зростає.
Розуміння того, як навчаються моделі ШІ, має важливе значення для оцінки майбутнього інфраструктури ШІ, використання енергії та технологічного прогресу.