Зміст
Що відбувається, коли ви надсилаєте запит ШІ?
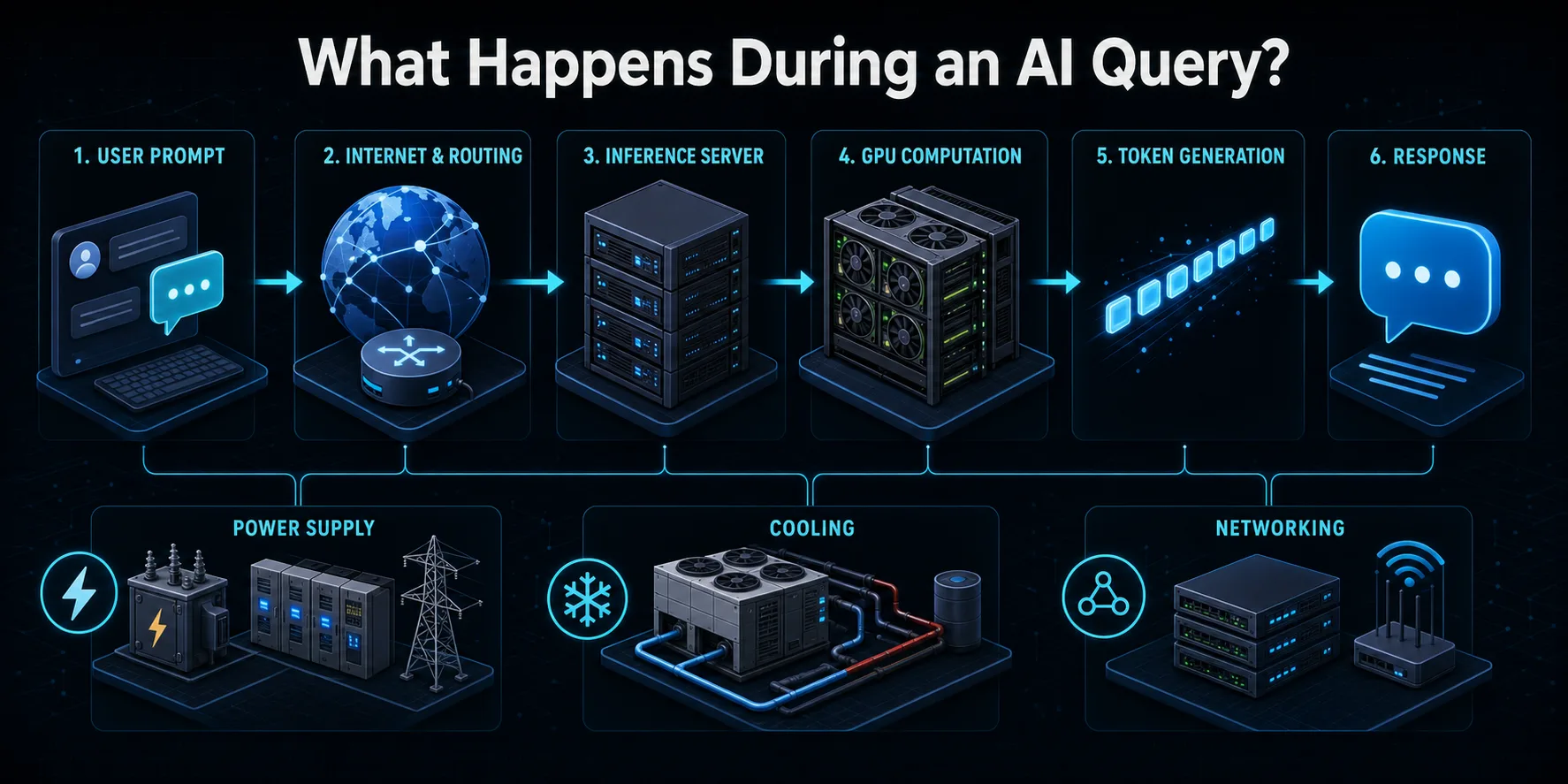
Коли ви надсилаєте запит до служби штучного інтелекту, він спочатку надсилається через Інтернет до інфраструктури провайдера. Системи маршрутизації перевіряють автентичність запиту, застосовують засоби контролю безпеки та використання і перенаправляють його до доступного сервера виведення. Балансувальник навантаження може вибирати між багатьма машинами, щоб розподілити трафік користувачів, не перевантажуючи одну частину системи.
Сервер перетворює запит на токени - числові одиниці, які обробляються мовною моделлю. Ці токени та будь-який попередній контекст розмови завантажуються в пам'ять прискорювача. Потім графічні процесори або інші мікросхеми штучного інтелекту виконують багаторівневі матричні обчислення параметрів моделі, щоб передбачити наступний токен. Процес повторюється багато разів, поки відповідь не буде повною або не досягне заданої межі.
Згенеровані дані декодуються в текст і передаються назад користувачеві, часто під час обчислення наступних токенів. Навколо цієї видимої взаємодії залишається активним обладнання для зберігання, мережевого зв'язку, моніторингу, перетворення енергії та охолодження. Таким чином, запит використовує більше електроенергії, ніж електрика, виміряна лише на графічному процесорі, хоча прискорювач зазвичай виконує більшу частину інтенсивних обчислень.
Чому запити АІ споживають електроенергію
ШІ-висновки - це активні обчислення, а не простий пошук у базі даних. Велика модель повинна оцінити безліч числових операцій для кожного згенерованого токена, використовуючи параметри, які можуть займати десятки і сотні гігабайт пам'яті. Переміщення цих параметрів і проміжних значень між високошвидкісною пам'яттю і ядрами процесора споживає електроенергію разом з самими обчисленнями.
Обсяг роботи зростає разом із моделлю, підказкою та запитуваним результатом. Довгі історії розмов вимагають більше контексту для обробки, тоді як довгі відповіді змушують прискорювачі працювати на більшій кількості кроків генерації. Зображення, аудіо- та відеосистеми можуть вимагати різних конвеєрів обробки або повторюваних операцій уточнення, тому запит ШІ не є єдиною стандартизованою одиницею роботи.
Накладні витрати дата-центру також мають значення. Сервери потребують джерел живлення, мереж, зберігання та охолодження, а частина електроенергії втрачається під час перетворення та розподілу електроенергії. Оператори часто виражають ці накладні витрати через ефективність використання енергії, або PUE. Ефективний об'єкт наближає загальну енергію до енергії, що використовується обчислювальним обладнанням, в той час як менш ефективний об'єкт потребує більше допоміжної електроенергії для того ж робочого навантаження на висновок.
Скільки електроенергії споживає запит ШІ?
Не існує універсального показника споживання електроенергії для запитів штучного інтелекту. Загальнодоступні оцінки для текстової взаємодії зазвичай варіюються від часток ват-години до кількох ват-годин, але цей діапазон слід розглядати як порядок величини, а не як фіксований коефіцієнт перетворення. Короткий запит, оброблений оптимізованою, добре використовуваною моделлю, може споживати набагато менше енергії, ніж довга відповідь великої моделі, що працює на недостатньо завантаженому обладнанні.
Ват-година вимірює енергію, а не миттєву потужність. Наприклад, сервер, який споживає велику потужність протягом частки секунди, може споживати менше енергії, ніж система з меншою потужністю, що працює набагато довше. Тому для достовірної оцінки для кожного запиту потрібно знати як споживану потужність обладнання, так і тривалість і частку цього обладнання, що припадає на запит.
Порівняння з веб-пошуком, лампочками або зарядкою телефону може полегшити візуалізацію шкали, але часто приховує важливі припущення. Питання не в тому, чи кожен запит споживає певну кількість токенів. Питання в тому, яка модель обслуговувала запит, скільки токенів і способів було оброблено, наскільки ефективно запити були згруповані і скільки енергії інфраструктури було включено в розрахунок.
Чому оцінки різняться
Провайдери ШІ рідко публікують повні вимірювання, які пов'язують окремі запити з розміром моделі, завантаженням обладнання, кількістю токенів і накладними витратами. Тому дослідники повинні поєднувати розкриті специфікації обладнання, результати порівняльних тестів, оціночний час обслуговування та припущення щодо ефективності центру обробки даних. Різні варіанти на кожному кроці можуть призвести до суттєво різних відповідей.
Пакетна обробка є одним з основних джерел варіацій. Сервер виводу може обробляти кілька користувачів разом, розподіляючи завантаження моделі та обчислення в пакеті. Висока завантаженість може зменшити середнє споживання енергії на кожен запит, в той час як простої потужностей, вимоги до затримок або сплески трафіку можуть призвести до того, що дороге обладнання буде використовуватися частково. Новіші прискорювачі також можуть виконувати те саме робоче навантаження швидше або з меншою кількістю джоулів.
Межі оцінки також змінюють результат. Деякі розрахунки враховують лише енергію прискорювача; інші включають процесори, пам'ять, мережу, охолодження та втрати енергії. Більшість показників для кожного запиту не враховують енергію, витрачену раніше на виробництво обладнання та навчання моделі. Оцінки є найбільш корисними, коли межі системи та припущення чітко визначені, а не коли єдине число подається як універсальне.
Запити ШІ проти навчання ШІ
Під час навчання створюється або оновлюється модель шляхом багаторазового опрацювання великих наборів даних і коригування її параметрів. Великий навчальний цикл може займати тисячі прискорювачів протягом днів або тижнів, що робить його концентрованою і дуже помітною обчислювальною подією. Після завершення навчання отримана модель може бути розгорнута на багатьох серверах виводу, щоб відповідати на запити користувачів.
Зазвичай висновок набагато менший для однієї взаємодії, але він є безперервним. Виробничі системи повинні реагувати в будь-яку годину, мати достатню потужність для пікових навантажень і обслуговувати користувачів у різних регіонах. Тому енергетичний профіль розподіляється між багатьма центрами обробки даних і повторюється щоразу, коли генерується текст, зображення, аудіо чи інші вихідні дані.
Не слід автоматично вважати, що жодне з цих навантажень не буде домінувати над споживанням електроенергії впродовж усього терміну служби моделі. Навчання може бути найбільшою окремою подією, особливо для прикордонних систем, тоді як виведення може з часом перевищити його, коли сервіс обробляє величезний трафік протягом місяців або років. Баланс залежить від того, як часто моделі перенавчаються, наскільки широко вони розгорнуті і наскільки інтенсивно люди ними користуються.
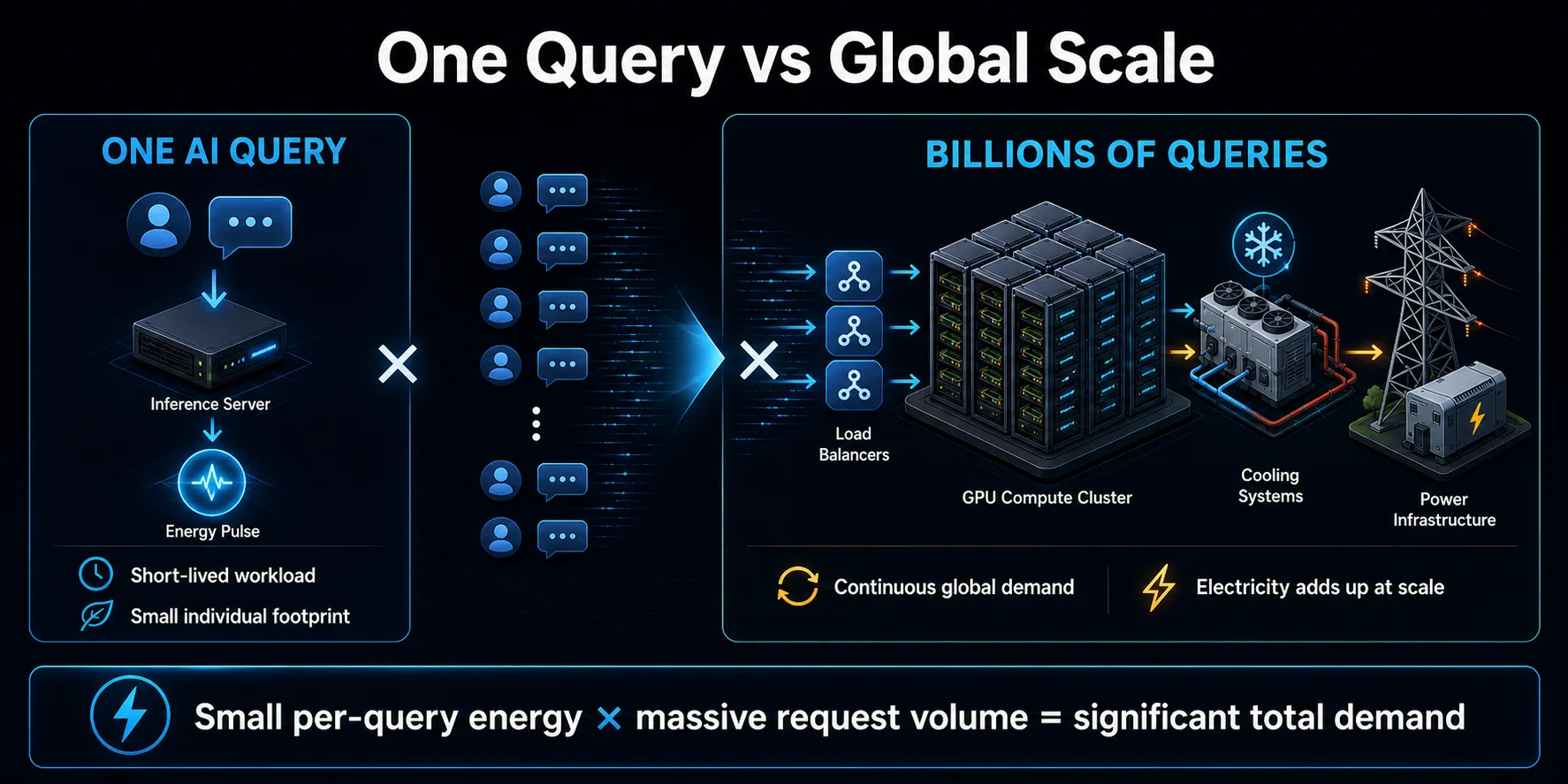
Мільярди запитів складаються
Екологічне значення запитів штучного інтелекту пов'язане насамперед з їхнім розмноженням. Один короткий запит може становити невелику кількість енергії, але споживчі асистенти, пошукові функції, інструменти кодування та бізнес-додатки можуть генерувати величезну кількість запитів. Повторюючись безперервно, скромна енергія одного запиту перетворюється на значне навантаження на центр обробки даних.
Попит не обмежується видимими повідомленнями чат-бота. Додатки можуть викликати кілька моделей у відповідь на одну дію користувача, використовувати окремі моделі для модерації або пошуку, повторювати невдалі запити, а також генерувати довідкові зведення або рекомендації. Агентні системи можуть розширити цей патерн, викликаючи моделі та програмні інструменти багаторазово під час виконання одного завдання.
Масштаб також впливає на планування інфраструктури. Провайдери створюють потужності для зростання та пікового трафіку, що може збільшити попит на електроенергію ще до того, як кожен сервер буде повністю завантажений. Загальний вплив залежить як від ефективності на запит, так і від темпів розширення використання. Якщо попит зростає швидше, ніж підвищується ефективність, сукупне споживання електроенергії може продовжувати зростати, навіть якщо кожна окрема взаємодія стає менш енергоємною.
Чи стануть запити ШІ ефективнішими?
Висновки ШІ, ймовірно, стануть більш енергоефективними на рівні порівнянних завдань. Нові прискорювачі забезпечують більше обчислень на одиницю електроенергії, а квантування, обрізання, спекулятивне декодування і вдосконалені архітектури моделей можуть зменшити кількість операцій, необхідних для отримання корисного результату. Краще планування та пакетне виконання також може підвищити завантаження обладнання, не змінюючи при цьому користувацький досвід.
Менші спеціалізовані моделі пропонують інший шлях. Сервісу не завжди потрібна найбільша модель для класифікації, вилучення або рутинних питань. Спрямування простої роботи на компактні моделі, обмеження непотрібного контексту та кешування результатів багаторазового використання може зменшити затримки та споживання електроенергії. Центри обробки даних можуть ще більше підвищити загальну ефективність за рахунок енергопостачання, охолодження та розміщення робочого навантаження.
Ефективність не гарантує зниження загального споживання. Швидший і дешевший ШІ може сприяти збільшенню кількості додатків, тривалішій взаємодії та появі нових обчислювальних функцій - ефект, який іноді називають "відскоком попиту". Таким чином, майбутнє споживання електроенергії запитами ШІ залежатиме від двох конкуруючих тенденцій: наскільки швидко кожна одиниця корисної роботи стає більш ефективною, і наскільки швидко зростає загальний обсяг і складність використання ШІ.