Contents
Training starts with data
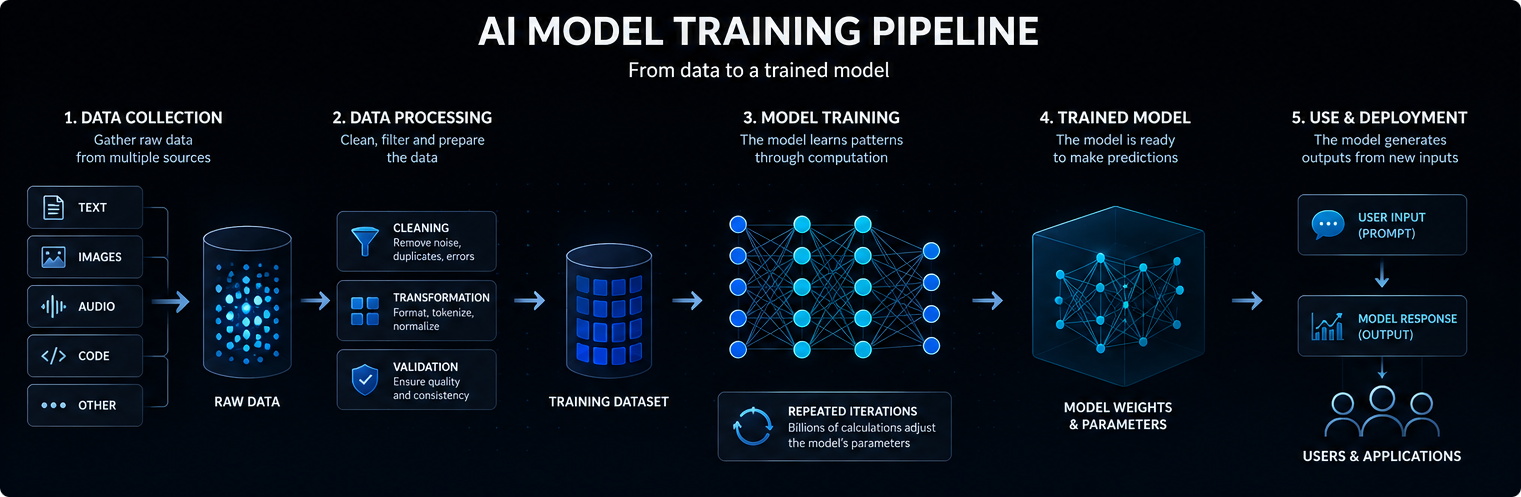
Training an AI model begins with data. Depending on the model, this data may include text, images, audio, code, video, scientific measurements or structured records.
Large language models are trained on vast collections of text and code so they can learn statistical relationships between words, concepts, instructions and outputs.
The quality, diversity and structure of the training data strongly influence what the model can learn, how well it generalizes and where its limitations appear.
Neural networks and parameters
Modern AI models are usually based on neural networks. These networks contain many layers of mathematical operations that transform input data into predictions, classifications or generated outputs.
The internal values adjusted during training are called parameters. Large AI models may contain billions or even trillions of parameters.
Training is the process of adjusting these parameters so the model becomes better at predicting, classifying, generating or reasoning over new inputs. In simple terms, an AI model works by converting an input into internal signals, passing those signals through learned parameters, and producing the most likely useful output.
How learning actually happens
During training, the model processes examples and produces predictions. Those predictions are compared with expected outputs or training objectives.
When the model makes mistakes, optimization algorithms adjust its parameters slightly. This process is repeated many times across enormous datasets.
Over time, the model learns statistical patterns that allow it to produce more useful outputs when it later receives new prompts or inputs.
Why training requires so much compute
Training large AI models requires massive computation because billions of parameters must be updated repeatedly across huge volumes of data.
This process is typically distributed across large GPU clusters inside specialized datacenters. The GPUs perform parallel mathematical operations far faster than conventional processors.
The larger the model and the dataset, the more compute, electricity, cooling and infrastructure are required.
How long does AI training take?
Training duration varies widely. Small models can be trained in minutes or hours, while frontier models may require weeks or months of coordinated computation.
Training time depends on model size, dataset size, hardware availability, optimization techniques, and the number of GPUs used in parallel.
Large AI labs invest heavily in infrastructure because faster training cycles allow them to test more ideas, improve models more quickly and deploy new systems sooner.
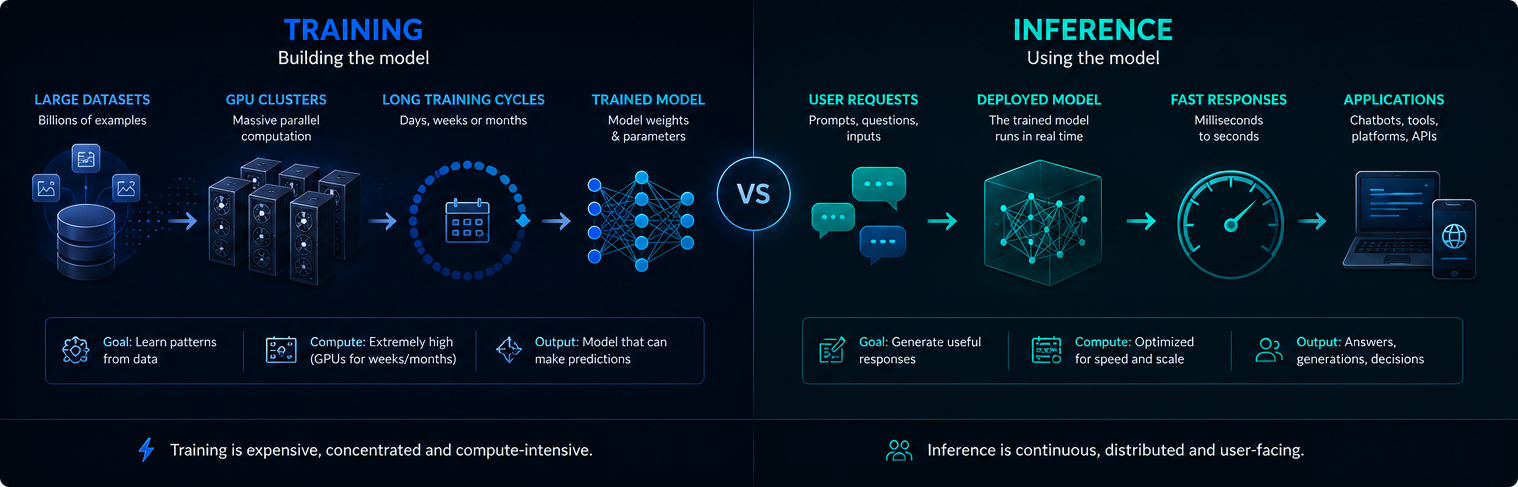
Training vs inference
Training and inference are different phases of AI infrastructure. Training creates or updates the model, while inference uses the trained model to answer user requests.
Training is usually concentrated and extremely compute-intensive. Inference is continuous, because deployed AI systems may serve millions of prompts every day.
Both phases matter for electricity demand, GPU usage and the environmental impact of modern AI.
The future of AI training
AI training is likely to become more efficient through better hardware, improved algorithms, smaller specialized models and more optimized data pipelines.
At the same time, demand for more capable models continues to grow. Efficiency improvements may reduce the cost of individual workloads while total compute demand still increases.
Understanding how AI models are trained is essential for evaluating the future of AI infrastructure, energy use and technological progress.