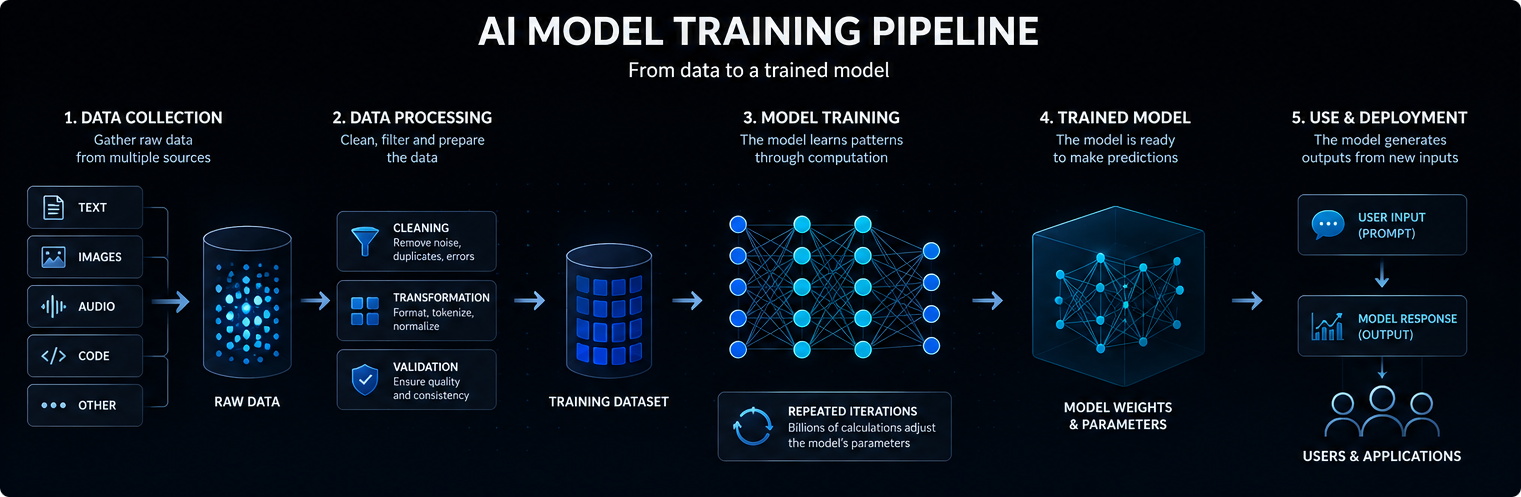
内容
トレーニングはデータから始まる
AIモデルのトレーニングはデータから始まる。モデルによっては、このデータにはテキスト、画像、音声、コード、ビデオ、科学的測定、構造化された記録などが含まれる。
大規模な言語モデルは、膨大なテキストやコードのコレクションで学習されるため、単語、概念、命令、出力間の統計的関係を学習することができる。
学習データの質、多様性、構造は、モデルが何を学習できるか、どの程度汎化できるか、どこに限界が現れるかに強く影響する。
ニューラルネットワークとパラメータ
現代のAIモデルは、通常、ニューラルネットワークに基づいています。これらのネットワークは、入力データを予測、分類、または生成された出力に変換する、多くの層からなる数学的演算で構成されています。
学習中に調整される内部値はパラメータと呼ばれる。大規模なAIモデルには、数十億から数兆のパラメータが含まれることもある。
学習とは、モデルが新しい入力に対して予測、分類、生成、あるいは推論をより正確に行えるようになるよう、これらのパラメータを調整するプロセスです。簡単に言えば、AIモデルは、入力を内部信号に変換し、その信号を学習済みのパラメータに通すことで、最も有用と思われる出力を生成するという仕組みで動作します。
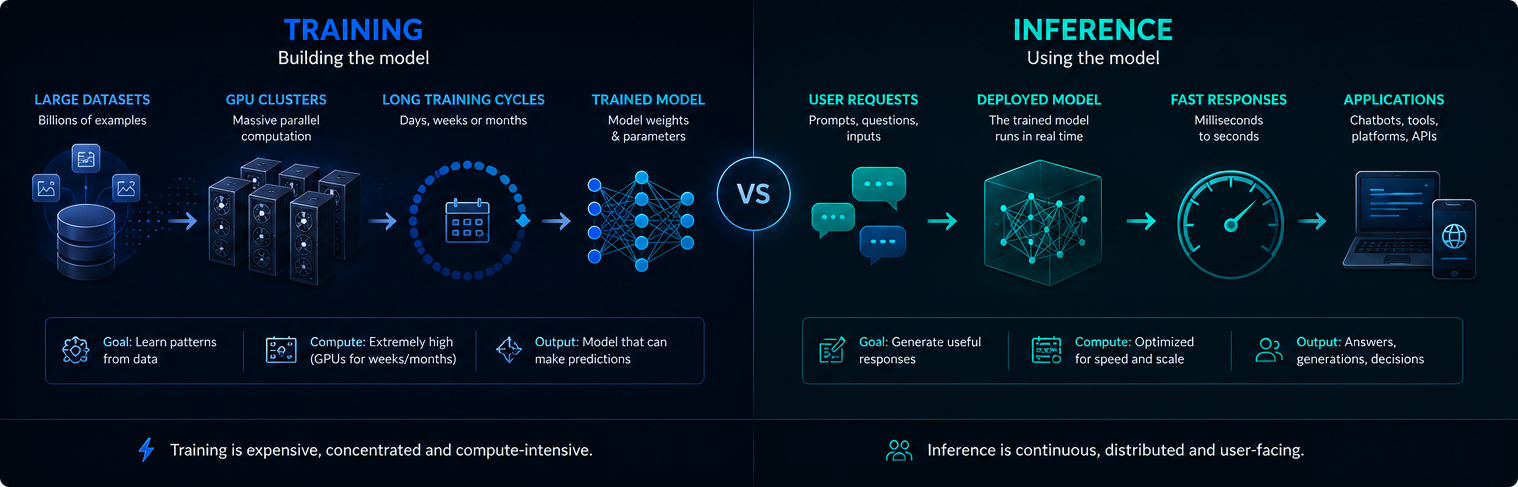
学習が実際にどのように行われるか
トレーニング中、モデルは例を処理し、予測を生成する。これらの予測は、期待される出力またはトレーニング目標と比較される。
モデルが間違いを犯すと、最適化アルゴリズムがそのパラメーターを少しずつ調整する。このプロセスは、膨大なデータセットで何度も繰り返される。
時間が経つにつれて、モデルは統計的パターンを学習し、後に新しいプロンプトや入力を受け取ったときに、より有用な出力を生成できるようになる。
トレーニングに多くの計算量が必要な理由
大規模なAIモデルのトレーニングには、膨大な量のデータに対して何十億ものパラメータを繰り返し更新する必要があるため、膨大な計算が必要となる。
このプロセスは通常、専用のデータセンター内の大規模なGPUクラスターに分散される。GPUは、従来のプロセッサーよりもはるかに高速に並列数学演算を実行する。
モデルやデータセットが大きくなればなるほど、より多くの計算機、電力、冷却、インフラが必要になる。
AIのトレーニングにはどれくらいの時間がかかるのか?
トレーニング期間は大きく異なる。小規模なモデルであれば数分から数時間で学習できるが、フロンティアモデルでは数週間から数ヶ月の調整計算が必要になることもある。
トレーニングにかかる時間は、モデルのサイズ、データセットのサイズ、ハードウェアの可用性、最適化技術、並列に使用するGPUの数に依存します。
大規模なAIラボがインフラに多額の投資を行うのは、トレーニングサイクルを高速化することで、より多くのアイデアをテストし、モデルをより迅速に改善し、新しいシステムをより早く導入することが可能になるからだ。
トレーニングと推論
訓練と推論は、AIインフラストラクチャの異なるフェーズである。訓練はモデルを作成または更新し、推論は訓練されたモデルを使用してユーザーの要求に答える。
トレーニングは通常、集中的に行われ、非常に計算集約的である。導入されたAIシステムは毎日何百万ものプロンプトを提供する可能性があるため、推論は継続的に行われる。
どちらの段階も、電力需要、GPU使用量、そして現代のAIが環境に与える影響にとって重要である。
AIトレーニングの未来
AIのトレーニングは、より優れたハードウェア、改良されたアルゴリズム、より小さな特殊モデル、より最適化されたデータパイプラインによって、より効率的になると思われる。
同時に、より高性能なモデルに対する需要も増え続けている。効率性の向上により、個々のワークロードのコストが削減される可能性がある一方で、総コンピュート需要は依然として増加しています。
AIモデルの学習方法を理解することは、AIインフラ、エネルギー使用、技術進歩の将来を評価する上で不可欠である。