目次
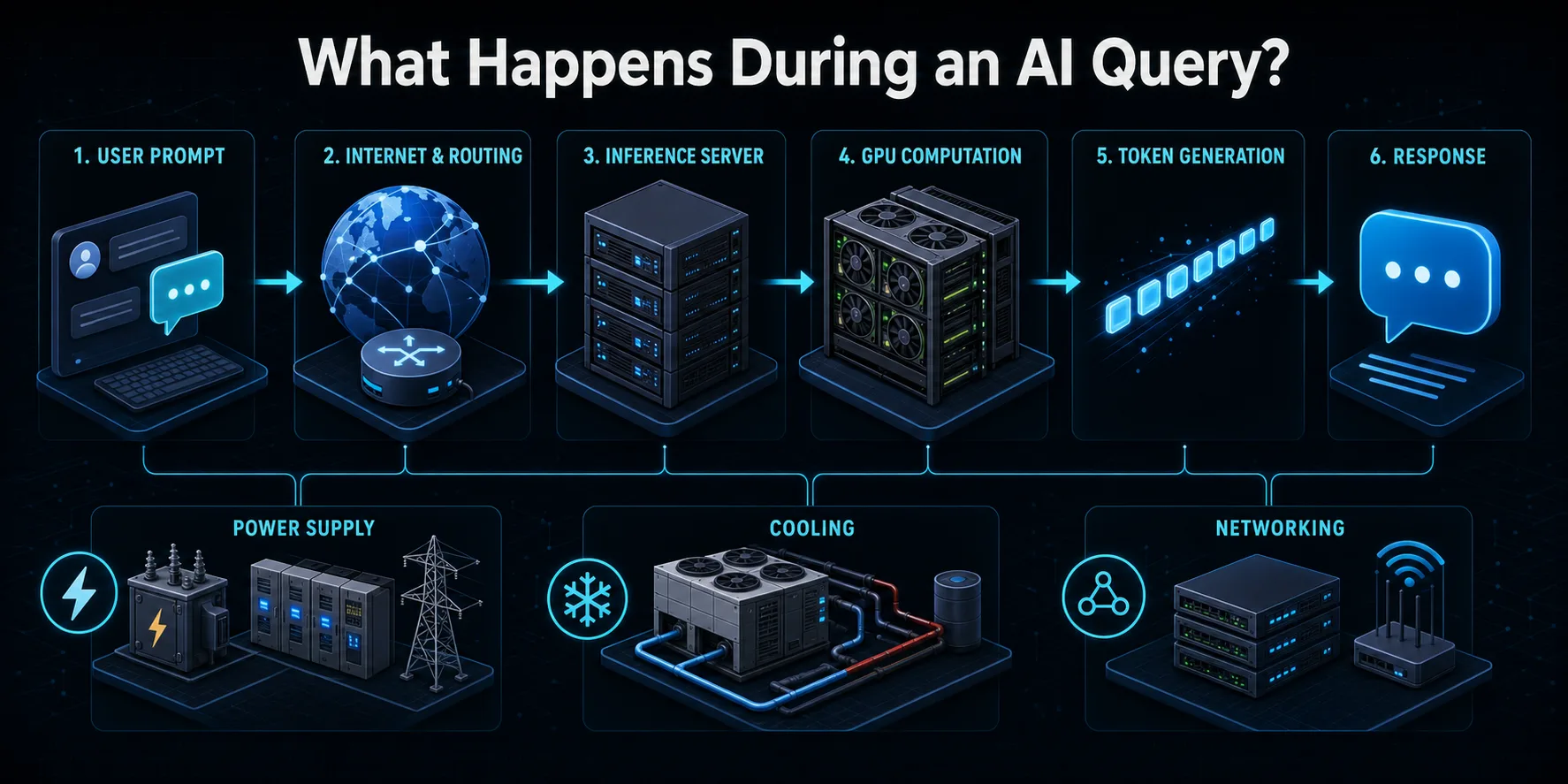
AIにクエリーを送るとどうなるのか?
AIサービスにプロンプトを送信すると、リクエストはまずインターネットを経由してプロバイダーのインフラに到達する。ルーティングシステムは、リクエストを認証し、安全性と利用制御を適用し、利用可能な推論サーバーに向かわせる。ロードバランサーは、ユーザー・トラフィックがシステムの一部に過負荷をかけることなく分散されるように、多くのマシンの中から選択することができる。
サーバーはプロンプトを言語モデルによって処理される数値単位であるトークンに変換する。これらのトークンと以前の会話コンテキストは、アクセラレーターのメモリにロードされる。GPUやその他のAIチップは、次のトークンを予測するために、モデルのパラメータを横断するマトリックス計算を何層にもわたって実行する。このプロセスは、応答が完了するか、設定された上限に達するまで何度も繰り返される。
生成された出力はテキストにデコードされ、ユーザーにストリームバックされる。この目に見えるインタラクションの周辺では、ストレージ、ネットワーキング、モニタリング、電力変換、冷却装置がアクティブなままである。そのため、アクセラレーターは通常、集中的な計算のほとんどを実行するにもかかわらず、クエリーはGPUだけで計測される電力よりも多くの電力を消費する。
AIクエリが電力を消費する理由
AIの推論は、データベースからの単純な検索ではなく、能動的な計算である。大規模なモデルでは、生成されたトークンごとに、数十ギガバイトから数百ギガバイトのメモリを占有する可能性のあるパラメータを使用して、多くの数値演算を評価しなければならない。これらのパラメータや中間値を広帯域幅のメモリとプロセッサコアの間で移動させることは、計算そのものと同時に電力を消費する。
作業量は、モデル、プロンプト、要求される出力とともに増加する。長い会話履歴は、より多くのコンテキストを処理する必要があり、長い回答は、より多くの生成ステップのためにアクセラレータを実行し続ける。画像、音声、ビデオシステムは、異なる処理パイプラインや繰り返し洗練操作を必要とする可能性があるため、AIクエリは1つの標準化された作業単位ではありません。
データセンターのオーバーヘッドも重要だ。サーバーには電源、ネットワーク、ストレージ、冷却が必要であり、電力変換や配電の際に失われる電力もあります。オペレータは、このオーバーヘッドを電力使用効率(PUE)で表すことがよくあります。効率的な施設では、総エネルギーがコンピューティング機器によって使用されるエネルギーに近づきますが、効率の悪い施設では、同じ推論ワークロードに対してより多くのサポート電力が必要になります。
AIクエリはどのくらいの電力を使うのか?
AIクエリに普遍的な電力量は存在しない。公開されているテキスト対話の見積もりでは、一般的に1ワット時の端数から数ワット時までの幅があるが、その幅は固定的な換算ではなく、桁として扱われるべきである。最適化され、十分に利用されたモデルによって処理される短いリクエストは、十分に利用されていないハードウェアで動作する大きなモデルからの長い応答よりも、はるかに少ないエネルギーしか消費しない。
ワット時とは、瞬間的な電力ではなく、エネルギーを測定するものである。例えば、サーバーがほんの一瞬だけ高電力を消費する場合、低電力のシス テムがはるかに長時間稼働する場合よりも、総エネルギー消費量が少ない可能性がある。そのため、信頼できるクエリごとの見積もりには、機器の消費電力と、その機器の持続時間とリクエストに起因する割合の両方が必要である。
ウェブ検索や電球、携帯電話の充電との比較は、スケールを視覚化しやすくするが、しばしば重要な仮定を隠してしまう。関連する問題は、すべてのプロンプトがある特定の量を消費したかどうかではない。どのモデルがリクエストを処理したのか、どれだけのトークンとモダリティが処理されたのか、リクエストがどれだけ効率的にグループ化されたのか、どれだけのインフラエネルギーが計算に含まれたのか、である。
見積もりが異なる理由
AIプロバイダーは、個々のリクエストとモデルサイズ、ハードウェア利用率、トークン数、設備オーバヘッドを結びつける完全な測定値を公開することはほとんどない。そのため研究者は、公開されているハードウェアの仕様、ベンチマーク結果、推定サービング時間、データセンターの効率性の仮定を組み合わせる必要がある。どのステップでも異なる選択をすれば、大幅に異なる答えが得られる可能性がある。
バッチ処理は、ばらつきの主な原因の1つである。推論サーバーは、複数のユーザーをまとめて処理することができ、バッ チ全体でモデルのロードと計算を共有することができる。高い利用率は、各リクエストに割り当てられる平均エネルギーを減少させますが、アイドル容量、待ち時間要件、またはトラフィックの急増は、高価なハードウェアを部分的に使用したままにする可能性があります。新しいアクセラレータは、同じワークロードをより速く、より少ないジュールで完了することもできます。
見積もりの境界線によっても結果は変わる。アクセラレータのエネルギーだけをカウントする計算もあれば、CPU、メモリ、ネットワーク、冷却、電力損失を含む計算もある。ほとんどのクエリーあたりの数値は、ハードウェアの製造やモデルのトレーニングに使用される以前のエネルギーを除外しています。見積もりは、システムの境界と仮定が明示されているときに最も役に立ちます。
AIクエリとAIトレーニング
トレーニングは、大規模なデータセットを繰り返し処理し、パラメータを調整することで、モデルを作成または更新する。大規模なトレーニングは、何千ものアクセラレータを何日も何週間も占有する可能性があり、集中的で非常に目に見えるコンピューティング・イベントとなる。トレーニングが完了すると、得られたモデルは多くの推論サーバーに配置され、ユーザーの要求に答えることができる。
推論は通常、1回のインタラクションでははるかに小さいが、連続的である。プロダクション・システムは、どの時間帯にも対応し、ピーク時に十分な容量を確保し、複数の地域のユーザーにサービスを提供しなければならない。そのため、エネルギー・プロファイルは多くのデータセンターに分散され、テキスト、画像、音声、その他の出力が生成されるたびに繰り返される。
どちらの作業負荷も、モデルの生涯電力使用量を自動的に支配すると仮定すべきではない。特にフロンティアシステムにおいては、トレーニングが最大の単一イベントとなる可能性がある一方、サービスが数カ月から数年にわたって膨大なトラフィックを処理する場合には、推論が最終的にそれを上回る可能性がある。そのバランスは、モデルの再トレーニングの頻度、モデルの展開範囲、モデルの使用頻度によって決まる。
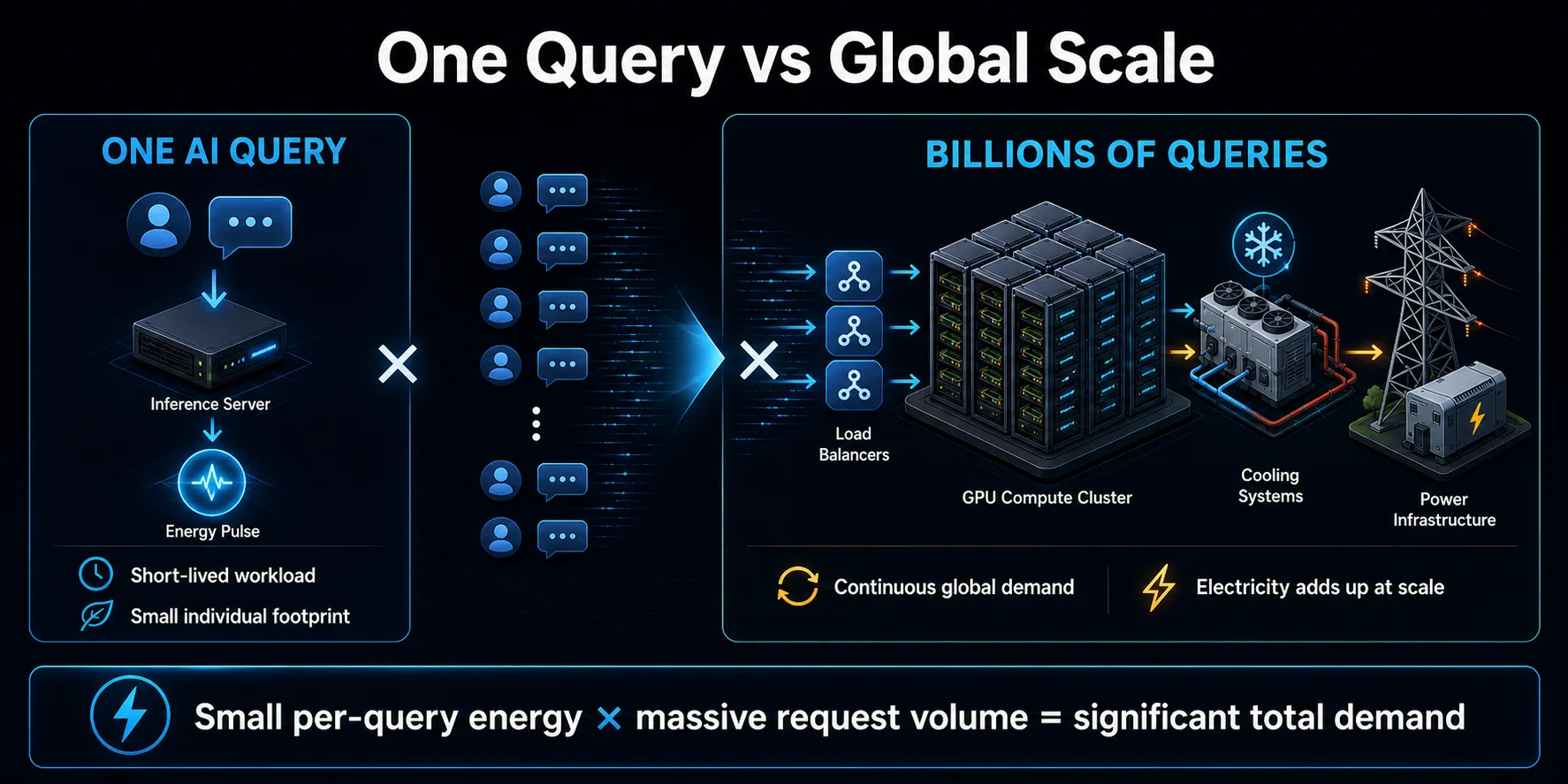
何十億ものクエリが加算される
AIクエリの環境的意義は、主に掛け算から生まれる。1回の短いプロンプトは少量のエネルギーかもしれないが、コンシューマー・アシスタント、検索機能、コーディング・ツール、ビジネス・アプリケーションは膨大な数のリクエストを生成する可能性がある。継続的に繰り返されるリクエストごとのエネルギーは、データセンターの負荷となる。
需要は、目に見えるチャットボットのメッセージに限定されません。アプリケーションは、1つのユーザーアクションに答えるために複数のモデルを呼び出したり、モデレーションや検索に別のモデルを使用したり、失敗したリクエストを再試行したり、バックグラウンドのサマリーやレコメンデーションを生成したりすることがあります。エージェントシステムは、1つのタスクを完了する間にモデルやソフトウェアツールを繰り返し呼び出すことで、このパターンを拡張することができます。
規模はインフラ計画にも影響する。プロバイダーはトラフィックの増加やピークを想定してキャパシティを構築するため、すべてのサーバーがフルに利用される前に電力需要が増加する可能性があります。総影響は、クエリごとの効率と、利用が拡大する速度の両方に依存する。需要が効率の向上よりも速く増加した場合、個々のインタラクションのエネルギー消費量が少なくなっても、総電力消費量は増加し続ける可能性があります。
AIのクエリーはより効率的になるのか?
AIの推論は、同程度のタスクのレベルで、よりエネルギー効率が高くなる可能性がある。新しいアクセラレーターは、単位電力あたりの計算量を増加させ、量子化、プルーニング、投機的デコーディング、モデル・アーキテクチャの改善により、有用な出力に必要な演算を削減することができる。また、スケジューリングやバッチ処理を改善することで、ユーザー体験を変えることなくハードウェアの利用率を高めることができる。
小型の専門モデルは別の道を提供する。サービスは、分類、抽出、定型的な質問に必ずしも最大のモデルを必要としない。シンプルな作業をコンパクトなモデルにルーティングし、不要なコンテキストを制限し、再利用可能な結果をキャッシュすることで、待ち時間と電力使用量の両方を削減することができます。データセンターは、電力供給、冷却、ワークロードの配置を通じて、総合効率をさらに向上させることができます。
効率は消費全体の削減を保証するものではない。より高速で安価なAIは、より多くのアプリケーション、より長いインタラクション、新たな計算集約的な機能を促進する可能性があり、この効果はリバウンド需要と表現されることもある。したがって、AIクエリの将来の電力フットプリントは、2つの競合するトレンドに左右されることになる。すなわち、有用な作業の各単位がどれだけ急速に効率化されるか、AIの使用量と複雑さの合計がどれだけ急速に増大するか、である。